 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistically-Informed Self-Attention for Semantic Role Labeling
Aug 28, 2018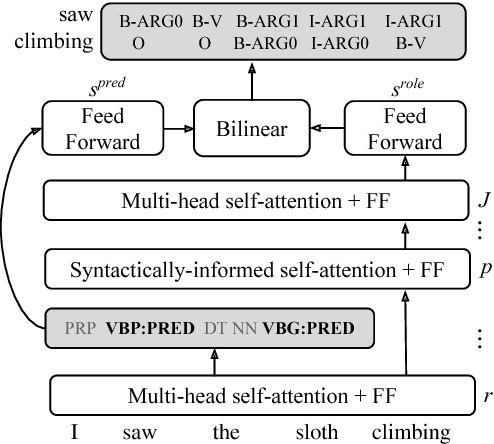
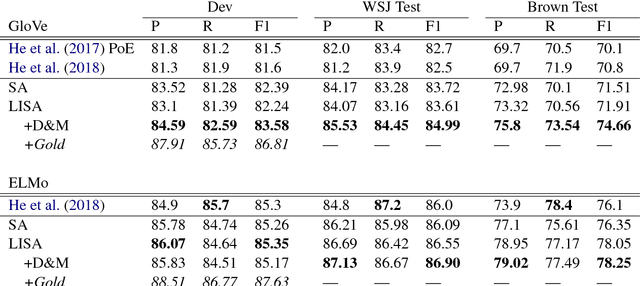
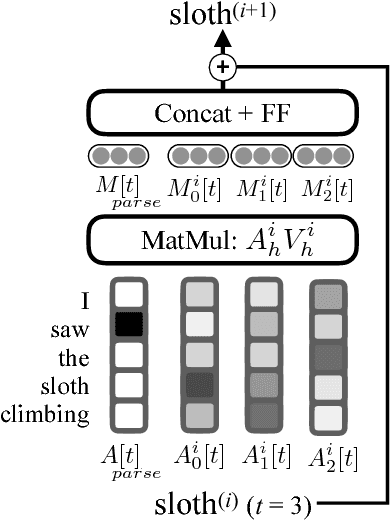
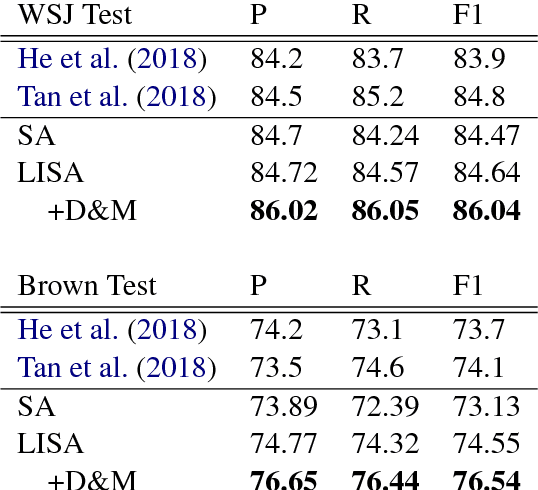
Current state-of-the-art semantic role labeling (SRL) uses a deep neural network with no explicit linguistic features. However, prior work has shown that gold syntax trees can dramatically improve SRL decoding, suggesting the possibility of increased accuracy from explicit modeling of syntax. In this work, we present linguistically-informed self-attention (LISA): a neural network model that combines multi-head self-attention with multi-task learning across dependency parsing, part-of-speech tagging, predicate detection and SRL. Unlike previous models which require significant pre-processing to prepare linguistic features, LISA can incorporate syntax using merely raw tokens as input, encoding the sequence only once to simultaneously perform parsing, predicate detection and role labeling for all predicates. Syntax is incorporated by training one attention head to attend to syntactic parents for each token. Moreover, if a high-quality syntactic parse is already available, it can be beneficially injected at test time without re-training our SRL model. In experiments on CoNLL-2005 SRL, LISA achieves new state-of-the-art performance for a model using predicted predicates and standard word embeddings, attaining 2.5 F1 absolute higher than the previous state-of-the-art on newswire and more than 3.5 F1 on out-of-domain data, nearly 10% reduction in error. On ConLL-2012 English SRL we also show an improvement of more than 2.5 F1. LISA also out-performs the state-of-the-art with contextually-encoded (ELMo) word representations, by nearly 1.0 F1 on news and more than 2.0 F1 on out-of-domain text.
Simultaneously Self-Attending to All Mentions for Full-Abstract Biological Relation Extraction
Feb 28, 2018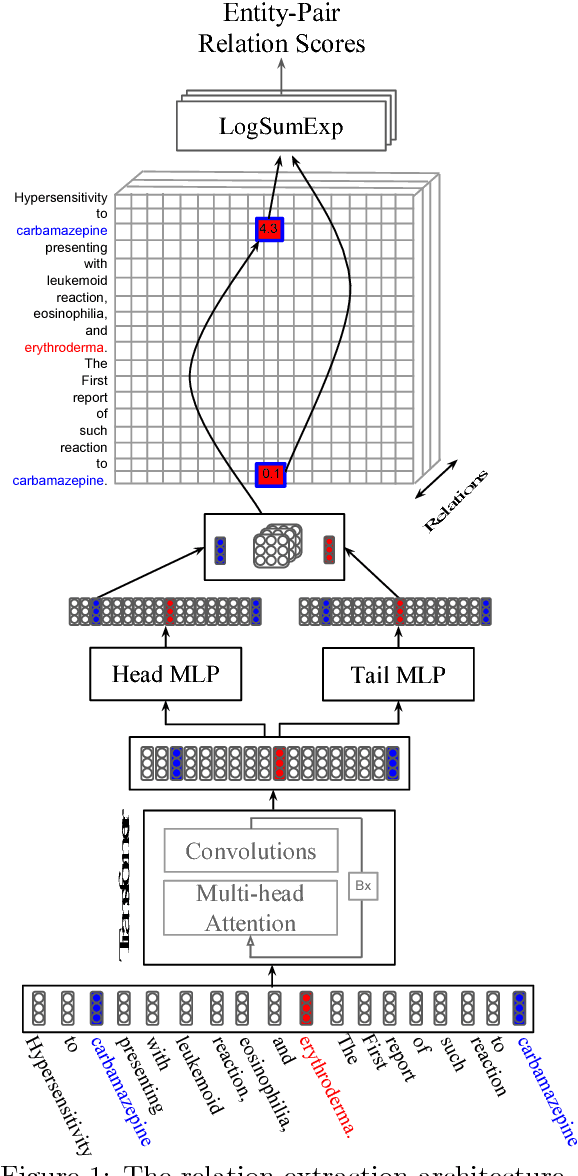
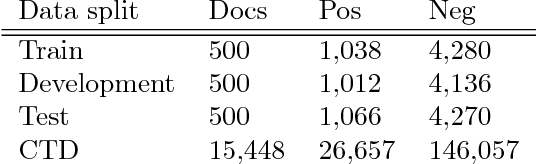
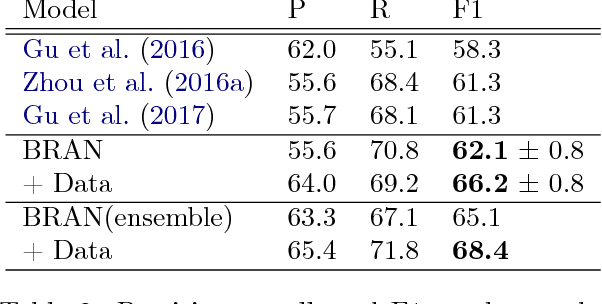
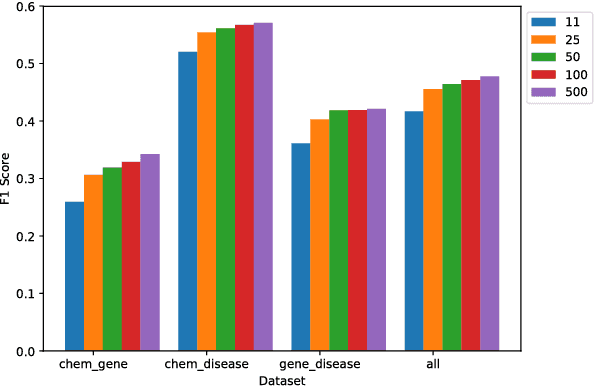
Most work in relation extraction forms a prediction by looking at a short span of text within a single sentence containing a single entity pair mention. This approach often does not consider interactions across mentions, requires redundant computation for each mention pair, and ignores relationships expressed across sentence boundaries. These problems are exacerbated by the document- (rather than sentence-) level annotation common in biological text. In response, we propose a model which simultaneously predicts relationships between all mention pairs in a document. We form pairwise predictions over entire paper abstracts using an efficient self-attention encoder. All-pairs mention scores allow us to perform multi-instance learning by aggregating over mentions to form entity pair representations. We further adapt to settings without mention-level annotation by jointly training to predict named entities and adding a corpus of weakly labeled data. In experiments on two Biocreative benchmark datasets, we achieve state of the art performance on the Biocreative V Chemical Disease Relation dataset for models without external KB resources. We also introduce a new dataset an order of magnitude larger than existing human-annotated biological information extraction datasets and more accurate than distantly supervised alternatives.
Finer Grained Entity Typing with TypeNet
Nov 15, 2017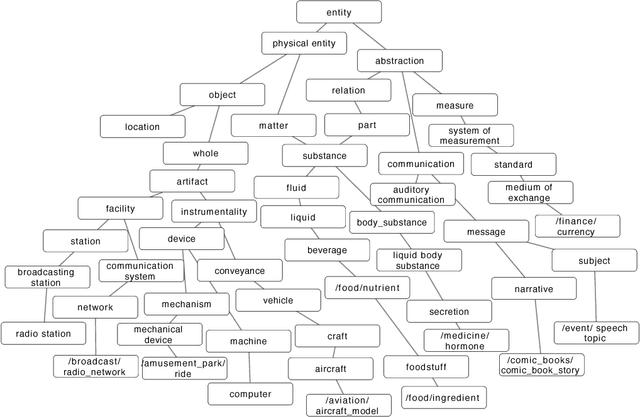
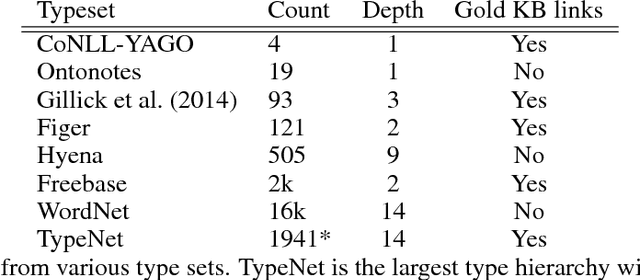
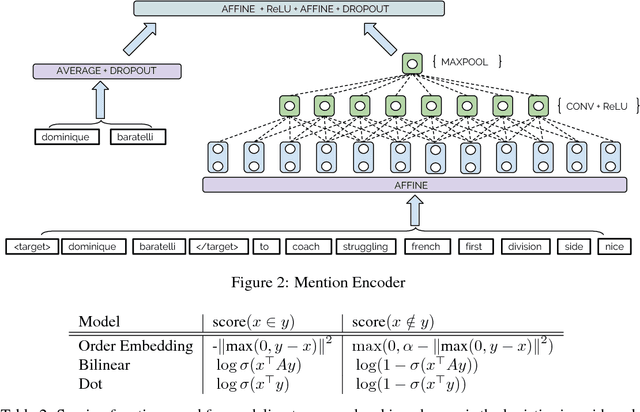
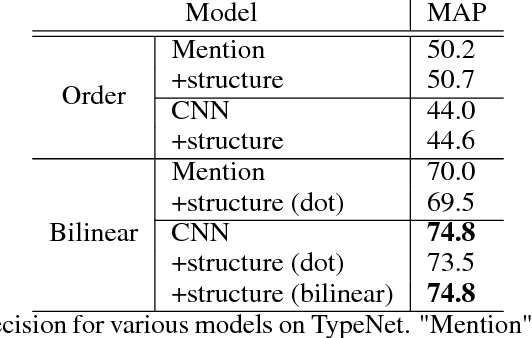
We consider the challenging problem of entity typing over an extremely fine grained set of types, wherein a single mention or entity can have many simultaneous and often hierarchically-structured types. Despite the importance of the problem, there is a relative lack of resources in the form of fine-grained, deep type hierarchies aligned to existing knowledge bases. In response, we introduce TypeNet, a dataset of entity types consisting of over 1941 types organized in a hierarchy, obtained by manually annotating a mapping from 1081 Freebase types to WordNet. We also experiment with several models comparable to state-of-the-art systems and explore techniques to incorporate a structure loss on the hierarchy with the standard mention typing loss, as a first step towards future research on this dataset.
Attending to All Mention Pairs for Full Abstract Biological Relation Extraction
Nov 15, 2017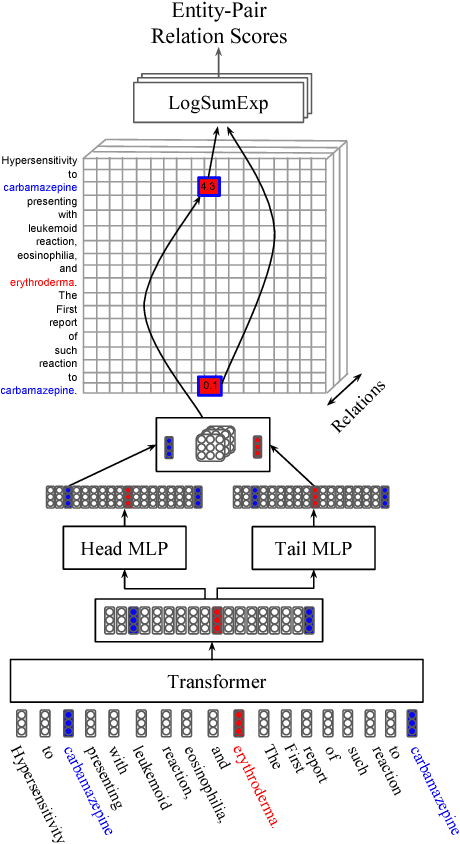
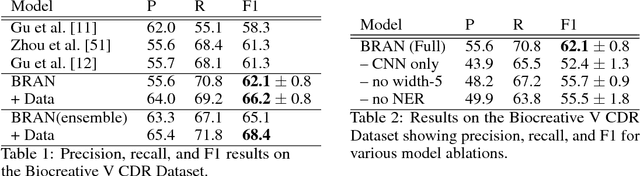
Most work in relation extraction forms a prediction by looking at a short span of text within a single sentence containing a single entity pair mention. However, many relation types, particularly in biomedical text, are expressed across sentences or require a large context to disambiguate. We propose a model to consider all mention and entity pairs simultaneously in order to make a prediction. We encode full paper abstracts using an efficient self-attention encoder and form pairwise predictions between all mentions with a bi-affine operation. An entity-pair wise pooling aggregates mention pair scores to make a final prediction while alleviating training noise by performing within document multi-instance learning. We improve our model's performance by jointly training the model to predict named entities and adding an additional corpus of weakly labeled data. We demonstrate our model's effectiveness by achieving the state of the art on the Biocreative V Chemical Disease Relation dataset for models without KB resources, outperforming ensembles of models which use hand-crafted features and additional linguistic resources.
Fast and Accurate Entity Recognition with Iterated Dilated Convolutions
Jul 22, 2017
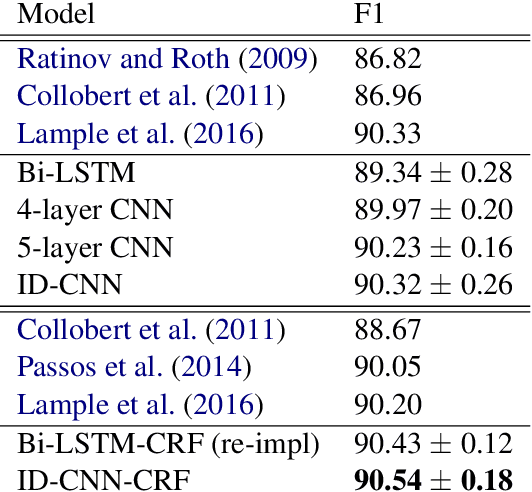
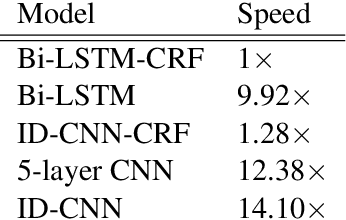
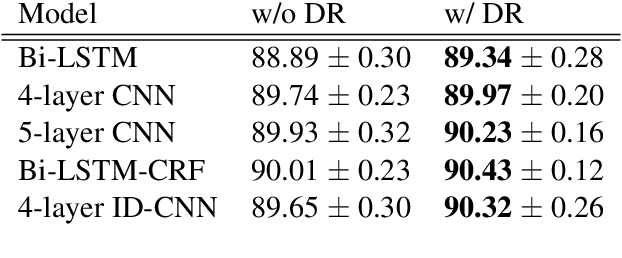
Today when many practitioners run basic NLP on the entire web and large-volume traffic, faster methods are paramount to saving time and energy costs. Recent advances in GPU hardware have led to the emergence of bi-directional LSTMs as a standard method for obtaining per-token vector representations serving as input to labeling tasks such as NER (often followed by prediction in a linear-chain CRF). Though expressive and accurate, these models fail to fully exploit GPU parallelism, limiting their computational efficiency. This paper proposes a faster alternative to Bi-LSTMs for NER: Iterated Dilated Convolutional Neural Networks (ID-CNNs), which have better capacity than traditional CNNs for large context and structured prediction. Unlike LSTMs whose sequential processing on sentences of length N requires O(N) time even in the face of parallelism, ID-CNNs permit fixed-depth convolutions to run in parallel across entire documents. We describe a distinct combination of network structure, parameter sharing and training procedures that enable dramatic 14-20x test-time speedups while retaining accuracy comparable to the Bi-LSTM-CRF. Moreover, ID-CNNs trained to aggregate context from the entire document are even more accurate while maintaining 8x faster test time speeds.
Generalizing to Unseen Entities and Entity Pairs with Row-less Universal Schema
Jan 09, 2017


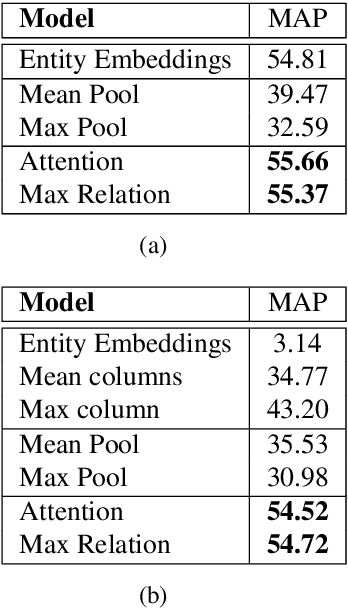
Universal schema predicts the types of entities and relations in a knowledge base (KB) by jointly embedding the union of all available schema types---not only types from multiple structured databases (such as Freebase or Wikipedia infoboxes), but also types expressed as textual patterns from raw text. This prediction is typically modeled as a matrix completion problem, with one type per column, and either one or two entities per row (in the case of entity types or binary relation types, respectively). Factorizing this sparsely observed matrix yields a learned vector embedding for each row and each column. In this paper we explore the problem of making predictions for entities or entity-pairs unseen at training time (and hence without a pre-learned row embedding). We propose an approach having no per-row parameters at all; rather we produce a row vector on the fly using a learned aggregation function of the vectors of the observed columns for that row. We experiment with various aggregation functions, including neural network attention models. Our approach can be understood as a natural language database, in that questions about KB entities are answered by attending to textual or database evidence. In experiments predicting both relations and entity types, we demonstrate that despite having an order of magnitude fewer parameters than traditional universal schema, we can match the accuracy of the traditional model, and more importantly, we can now make predictions about unseen rows with nearly the same accuracy as rows available at training time.
Row-less Universal Schema
Apr 21, 2016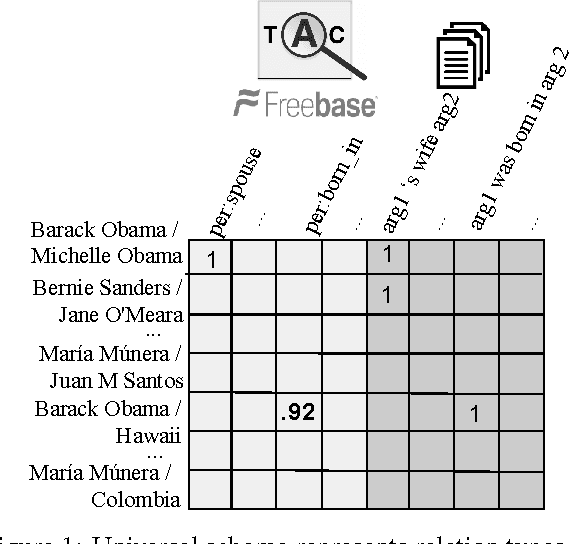
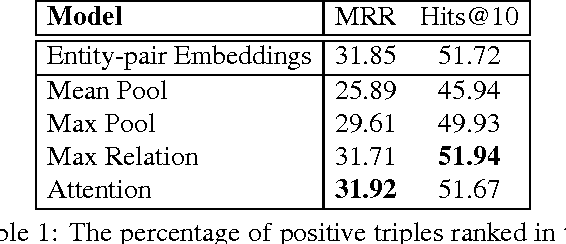
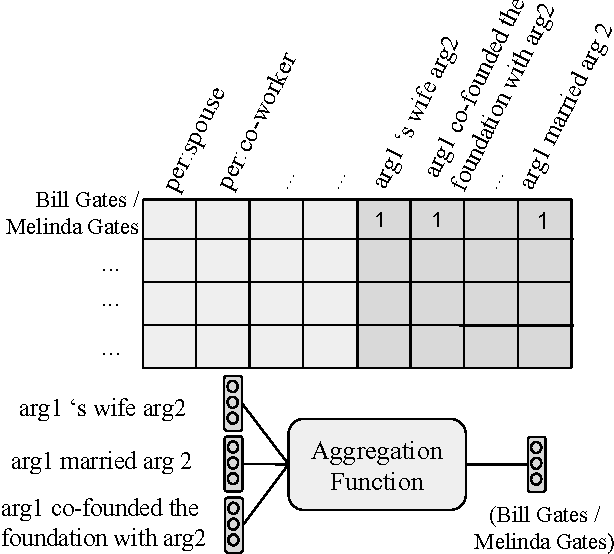
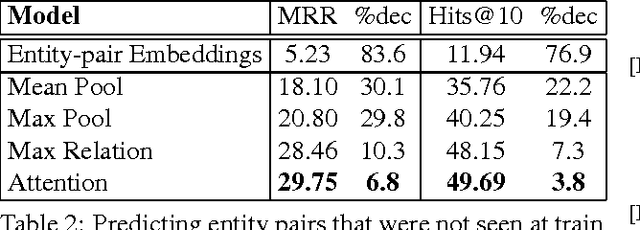
Universal schema jointly embeds knowledge bases and textual patterns to reason about entities and relations for automatic knowledge base construction and information extraction. In the past, entity pairs and relations were represented as learned vectors with compatibility determined by a scoring function, limiting generalization to unseen text patterns and entities. Recently, 'column-less' versions of Universal Schema have used compositional pattern encoders to generalize to all text patterns. In this work we take the next step and propose a 'row-less' model of universal schema, removing explicit entity pair representations. Instead of learning vector representations for each entity pair in our training set, we treat an entity pair as a function of its relation types. In experimental results on the FB15k-237 benchmark we demonstrate that we can match the performance of a comparable model with explicit entity pair representations using a model of attention over relation types. We further demonstrate that the model per- forms with nearly the same accuracy on entity pairs never seen during training.
Multilingual Relation Extraction using Compositional Universal Schema
Mar 03, 2016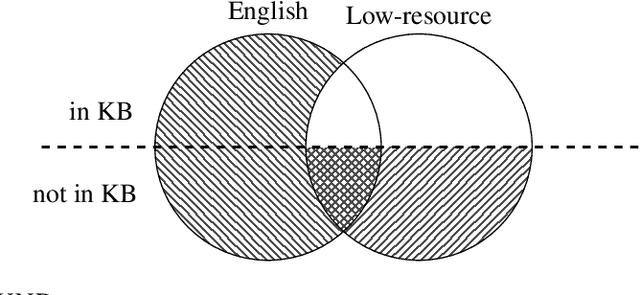

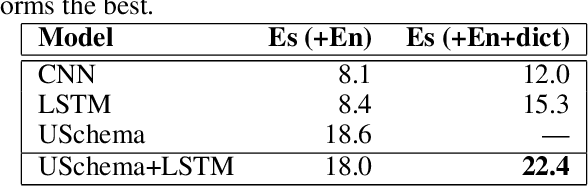

Universal schema builds a knowledge base (KB) of entities and relations by jointly embedding all relation types from input KBs as well as textual patterns expressing relations from raw text. In most previous applications of universal schema, each textual pattern is represented as a single embedding, preventing generalization to unseen patterns. Recent work employs a neural network to capture patterns' compositional semantics, providing generalization to all possible input text. In response, this paper introduces significant further improvements to the coverage and flexibility of universal schema relation extraction: predictions for entities unseen in training and multilingual transfer learning to domains with no annotation. We evaluate our model through extensive experiments on the English and Spanish TAC KBP benchmark, outperforming the top system from TAC 2013 slot-filling using no handwritten patterns or additional annotation. We also consider a multilingual setting in which English training data entities overlap with the seed KB, but Spanish text does not. Despite having no annotation for Spanish data, we train an accurate predictor, with additional improvements obtained by tying word embeddings across languages. Furthermore, we find that multilingual training improves English relation extraction accuracy. Our approach is thus suited to broad-coverage automated knowledge base construction in a variety of languages and domains.