 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Specific Fine-tuning of Denoising Sequence-to-Sequence Models for Natural Language Summarization
Apr 06, 2022
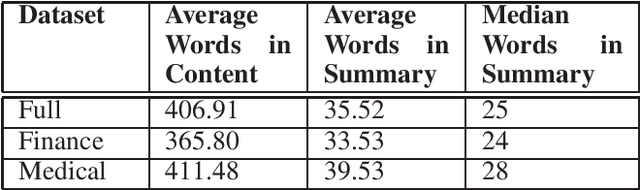
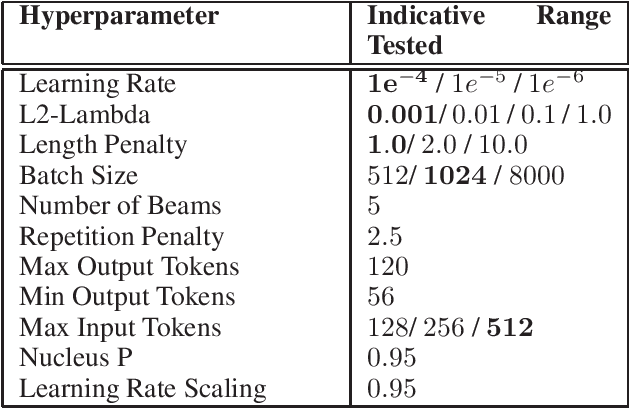

Summarization of long-form text data is a problem especially pertinent in knowledge economy jobs such as medicine and finance, that require continuously remaining informed on a sophisticated and evolving body of knowledge. As such, isolating and summarizing key content automatically using Natural Language Processing (NLP) techniques holds the potential for extensive time savings in these industries. We explore applications of a state-of-the-art NLP model (BART), and explore strategies for tuning it to optimal performance using data augmentation and various fine-tuning strategies. We show that our end-to-end fine-tuning approach can result in a 5-6\% absolute ROUGE-1 improvement over an out-of-the-box pre-trained BART summarizer when tested on domain specific data, and make available our end-to-end pipeline to achieve these results on finance, medical, or other user-specified domains.
Attending to All Mention Pairs for Full Abstract Biological Relation Extraction
Nov 15, 2017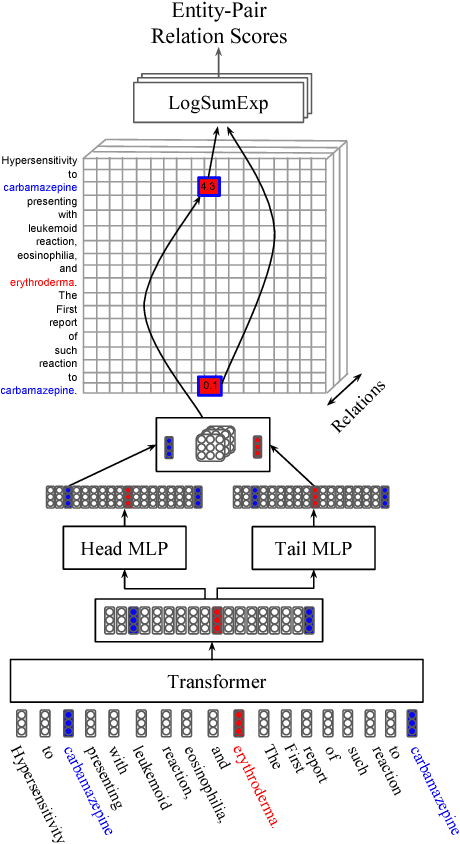
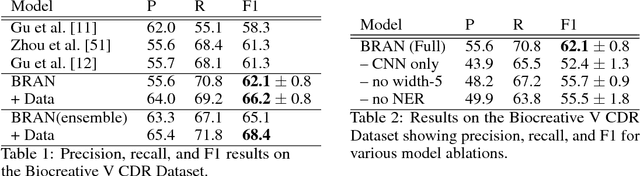
Most work in relation extraction forms a prediction by looking at a short span of text within a single sentence containing a single entity pair mention. However, many relation types, particularly in biomedical text, are expressed across sentences or require a large context to disambiguate. We propose a model to consider all mention and entity pairs simultaneously in order to make a prediction. We encode full paper abstracts using an efficient self-attention encoder and form pairwise predictions between all mentions with a bi-affine operation. An entity-pair wise pooling aggregates mention pair scores to make a final prediction while alleviating training noise by performing within document multi-instance learning. We improve our model's performance by jointly training the model to predict named entities and adding an additional corpus of weakly labeled data. We demonstrate our model's effectiveness by achieving the state of the art on the Biocreative V Chemical Disease Relation dataset for models without KB resources, outperforming ensembles of models which use hand-crafted features and additional linguistic resources.