 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKinetics: Rethinking Test-Time Scaling Laws
Jun 06, 2025We rethink test-time scaling laws from a practical efficiency perspective, revealing that the effectiveness of smaller models is significantly overestimated. Prior work, grounded in compute-optimality, overlooks critical memory access bottlenecks introduced by inference-time strategies (e.g., Best-of-$N$, long CoTs). Our holistic analysis, spanning models from 0.6B to 32B parameters, reveals a new Kinetics Scaling Law that better guides resource allocation by incorporating both computation and memory access costs. Kinetics Scaling Law suggests that test-time compute is more effective when used on models above a threshold than smaller ones. A key reason is that in TTS, attention, rather than parameter count, emerges as the dominant cost factor. Motivated by this, we propose a new scaling paradigm centered on sparse attention, which lowers per-token cost and enables longer generations and more parallel samples within the same resource budget. Empirically, we show that sparse attention models consistently outperform dense counterparts, achieving over 60 points gains in low-cost regimes and over 5 points gains in high-cost regimes for problem-solving accuracy on AIME, encompassing evaluations on state-of-the-art MoEs. These results suggest that sparse attention is essential and increasingly important with more computing invested, for realizing the full potential of test-time scaling where, unlike training, accuracy has yet to saturate as a function of computation, and continues to improve through increased generation. The code is available at https://github.com/Infini-AI-Lab/Kinetics.
Energy Considerations of Large Language Model Inference and Efficiency Optimizations
Apr 24, 2025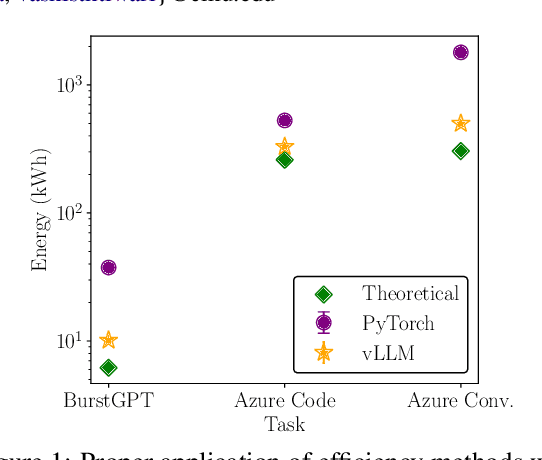
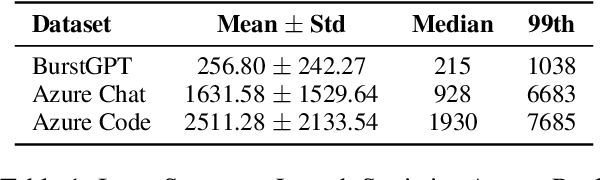
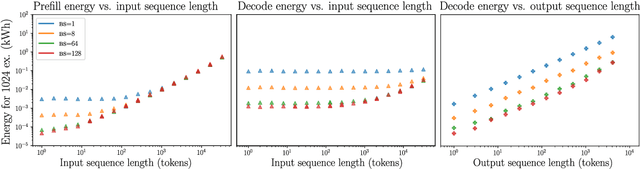

As large language models (LLMs) scale in size and adoption, their computational and environmental costs continue to rise. Prior benchmarking efforts have primarily focused on latency reduction in idealized settings, often overlooking the diverse real-world inference workloads that shape energy use. In this work, we systematically analyze the energy implications of common inference efficiency optimizations across diverse Natural Language Processing (NLP) and generative Artificial Intelligence (AI) workloads, including conversational AI and code generation. We introduce a modeling approach that approximates real-world LLM workflows through a binning strategy for input-output token distributions and batch size variations. Our empirical analysis spans software frameworks, decoding strategies, GPU architectures, online and offline serving settings, and model parallelism configurations. We show that the effectiveness of inference optimizations is highly sensitive to workload geometry, software stack, and hardware accelerators, demonstrating that naive energy estimates based on FLOPs or theoretical GPU utilization significantly underestimate real-world energy consumption. Our findings reveal that the proper application of relevant inference efficiency optimizations can reduce total energy use by up to 73% from unoptimized baselines. These insights provide a foundation for sustainable LLM deployment and inform energy-efficient design strategies for future AI infrastructure.
Beyond Text: Characterizing Domain Expert Needs in Document Research
Apr 16, 2025Working with documents is a key part of almost any knowledge work, from contextualizing research in a literature review to reviewing legal precedent. Recently, as their capabilities have expanded, primarily text-based NLP systems have often been billed as able to assist or even automate this kind of work. But to what extent are these systems able to model these tasks as experts conceptualize and perform them now? In this study, we interview sixteen domain experts across two domains to understand their processes of document research, and compare it to the current state of NLP systems. We find that our participants processes are idiosyncratic, iterative, and rely extensively on the social context of a document in addition its content; existing approaches in NLP and adjacent fields that explicitly center the document as an object, rather than as merely a container for text, tend to better reflect our participants' priorities, though they are often less accessible outside their research communities. We call on the NLP community to more carefully consider the role of the document in building useful tools that are accessible, personalizable, iterative, and socially aware.
Structured Extraction of Process Structure Properties Relationships in Materials Science
Apr 04, 2025
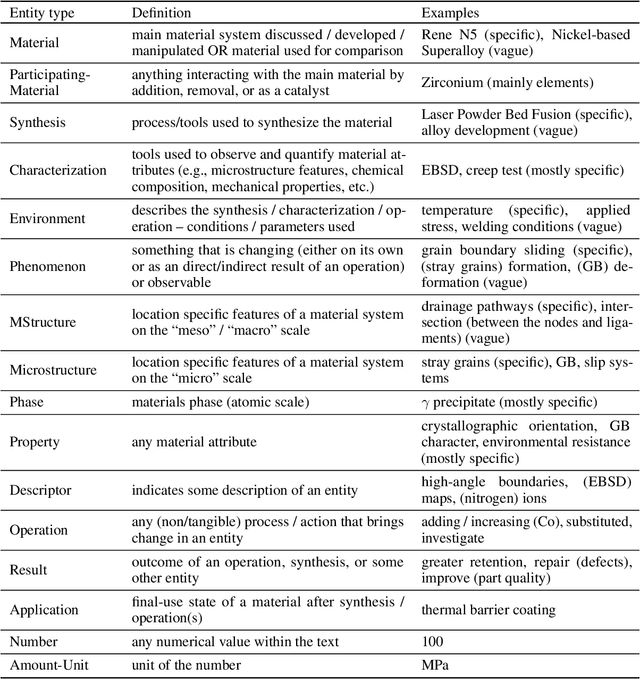
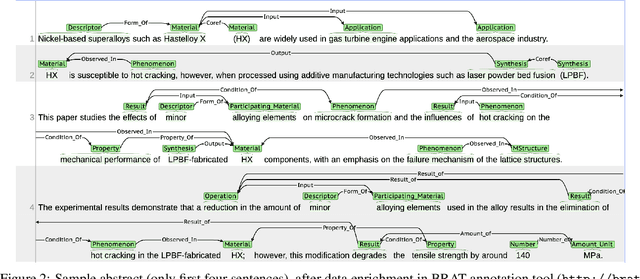
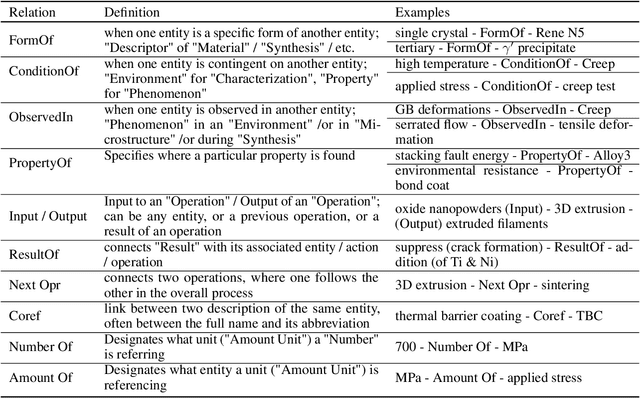
With the advent of large language models (LLMs), the vast unstructured text within millions of academic papers is increasingly accessible for materials discovery, although significant challenges remain. While LLMs offer promising few- and zero-shot learning capabilities, particularly valuable in the materials domain where expert annotations are scarce, general-purpose LLMs often fail to address key materials-specific queries without further adaptation. To bridge this gap, fine-tuning LLMs on human-labeled data is essential for effective structured knowledge extraction. In this study, we introduce a novel annotation schema designed to extract generic process-structure-properties relationships from scientific literature. We demonstrate the utility of this approach using a dataset of 128 abstracts, with annotations drawn from two distinct domains: high-temperature materials (Domain I) and uncertainty quantification in simulating materials microstructure (Domain II). Initially, we developed a conditional random field (CRF) model based on MatBERT, a domain-specific BERT variant, and evaluated its performance on Domain I. Subsequently, we compared this model with a fine-tuned LLM (GPT-4o from OpenAI) under identical conditions. Our results indicate that fine-tuning LLMs can significantly improve entity extraction performance over the BERT-CRF baseline on Domain I. However, when additional examples from Domain II were incorporated, the performance of the BERT-CRF model became comparable to that of the GPT-4o model. These findings underscore the potential of our schema for structured knowledge extraction and highlight the complementary strengths of both modeling approaches.
International AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
Generate to Discriminate: Expert Routing for Continual Learning
Dec 22, 2024In many real-world settings, regulations and economic incentives permit the sharing of models but not data across institutional boundaries. In such scenarios, practitioners might hope to adapt models to new domains, without losing performance on previous domains (so-called catastrophic forgetting). While any single model may struggle to achieve this goal, learning an ensemble of domain-specific experts offers the potential to adapt more closely to each individual institution. However, a core challenge in this context is determining which expert to deploy at test time. In this paper, we propose Generate to Discriminate (G2D), a domain-incremental continual learning method that leverages synthetic data to train a domain-discriminator that routes samples at inference time to the appropriate expert. Surprisingly, we find that leveraging synthetic data in this capacity is more effective than using the samples to \textit{directly} train the downstream classifier (the more common approach to leveraging synthetic data in the lifelong learning literature). We observe that G2D outperforms competitive domain-incremental learning methods on tasks in both vision and language modalities, providing a new perspective on the use of synthetic data in the lifelong learning literature.
Hardware Scaling Trends and Diminishing Returns in Large-Scale Distributed Training
Nov 20, 2024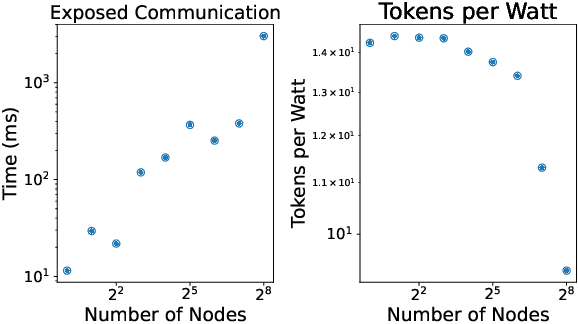

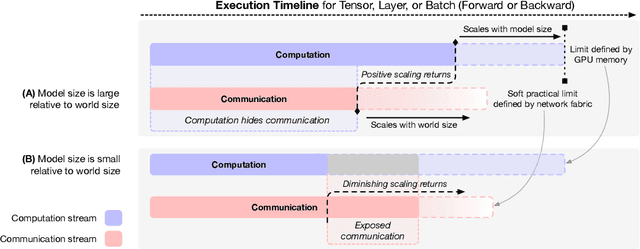
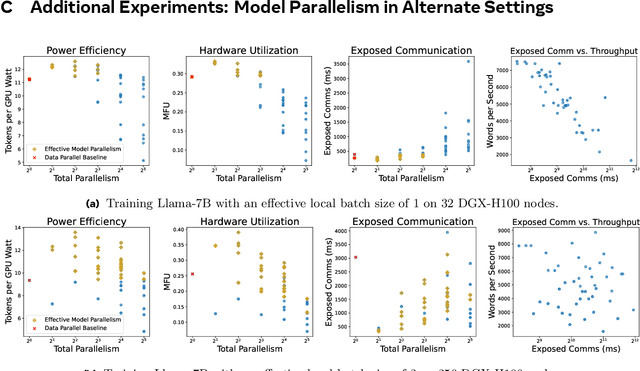
Dramatic increases in the capabilities of neural network models in recent years are driven by scaling model size, training data, and corresponding computational resources. To develop the exceedingly large networks required in modern applications, such as large language models (LLMs), model training is distributed across tens of thousands of hardware accelerators (e.g. GPUs), requiring orchestration of computation and communication across large computing clusters. In this work, we demonstrate that careful consideration of hardware configuration and parallelization strategy is critical for effective (i.e. compute- and cost-efficient) scaling of model size, training data, and total computation. We conduct an extensive empirical study of the performance of large-scale LLM training workloads across model size, hardware configurations, and distributed parallelization strategies. We demonstrate that: (1) beyond certain scales, overhead incurred from certain distributed communication strategies leads parallelization strategies previously thought to be sub-optimal in fact become preferable; and (2) scaling the total number of accelerators for large model training quickly yields diminishing returns even when hardware and parallelization strategies are properly optimized, implying poor marginal performance per additional unit of power or GPU-hour.
Gradient Localization Improves Lifelong Pretraining of Language Models
Nov 07, 2024Large Language Models (LLMs) trained on web-scale text corpora have been shown to capture world knowledge in their parameters. However, the mechanism by which language models store different types of knowledge is poorly understood. In this work, we examine two types of knowledge relating to temporally sensitive entities and demonstrate that each type is localized to different sets of parameters within the LLMs. We hypothesize that the lack of consideration of the locality of knowledge in existing continual learning methods contributes to both: the failed uptake of new information, and catastrophic forgetting of previously learned information. We observe that sequences containing references to updated and newly mentioned entities exhibit larger gradient norms in a subset of layers. We demonstrate that targeting parameter updates to these relevant layers can improve the performance of continually pretraining on language containing temporal drift.
Collage: Decomposable Rapid Prototyping for Information Extraction on Scientific PDFs
Oct 30, 2024



Recent years in NLP have seen the continued development of domain-specific information extraction tools for scientific documents, alongside the release of increasingly multimodal pretrained transformer models. While the opportunity for scientists outside of NLP to evaluate and apply such systems to their own domains has never been clearer, these models are difficult to compare: they accept different input formats, are often black-box and give little insight into processing failures, and rarely handle PDF documents, the most common format of scientific publication. In this work, we present Collage, a tool designed for rapid prototyping, visualization, and evaluation of different information extraction models on scientific PDFs. Collage allows the use and evaluation of any HuggingFace token classifier, several LLMs, and multiple other task-specific models out of the box, and provides extensible software interfaces to accelerate experimentation with new models. Further, we enable both developers and users of NLP-based tools to inspect, debug, and better understand modeling pipelines by providing granular views of intermediate states of processing. We demonstrate our system in the context of information extraction to assist with literature review in materials science.
Scalable Data Ablation Approximations for Language Models through Modular Training and Merging
Oct 21, 2024


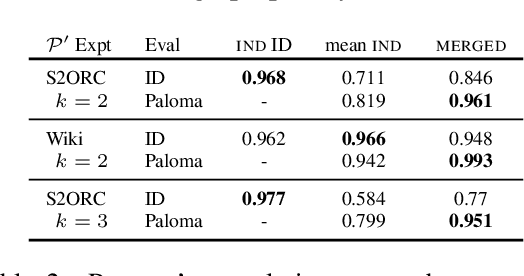
Training data compositions for Large Language Models (LLMs) can significantly affect their downstream performance. However, a thorough data ablation study exploring large sets of candidate data mixtures is typically prohibitively expensive since the full effect is seen only after training the models; this can lead practitioners to settle for sub-optimal data mixtures. We propose an efficient method for approximating data ablations which trains individual models on subsets of a training corpus and reuses them across evaluations of combinations of subsets. In continued pre-training experiments, we find that, given an arbitrary evaluation set, the perplexity score of a single model trained on a candidate set of data is strongly correlated with perplexity scores of parameter averages of models trained on distinct partitions of that data. From this finding, we posit that researchers and practitioners can conduct inexpensive simulations of data ablations by maintaining a pool of models that were each trained on partitions of a large training corpus, and assessing candidate data mixtures by evaluating parameter averages of combinations of these models. This approach allows for substantial improvements in amortized training efficiency -- scaling only linearly with respect to new data -- by enabling reuse of previous training computation, opening new avenues for improving model performance through rigorous, incremental data assessment and mixing.