 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCarbon Connect: An Ecosystem for Sustainable Computing
May 22, 2024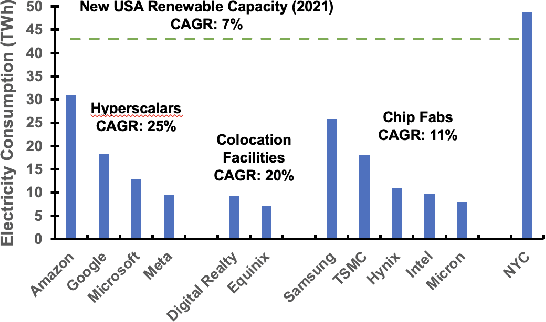
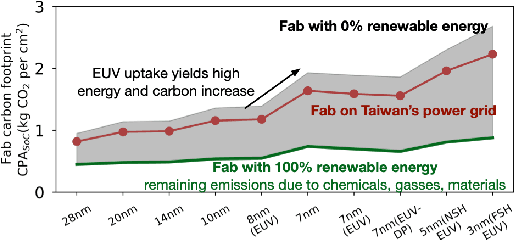
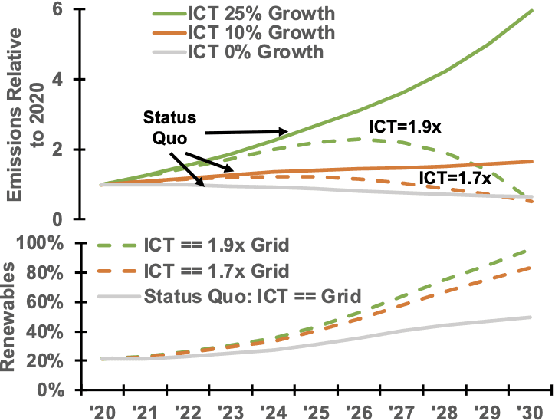
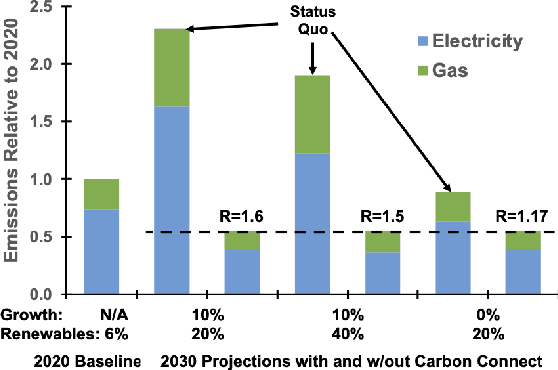
Computing is at a moment of profound opportunity. Emerging applications -- such as capable artificial intelligence, immersive virtual realities, and pervasive sensor systems -- drive unprecedented demand for computer. Despite recent advances toward net zero carbon emissions, the computing industry's gross energy usage continues to rise at an alarming rate, outpacing the growth of new energy installations and renewable energy deployments. A shift towards sustainability is needed to spark a transformation in how computer systems are manufactured, allocated, and consumed. Carbon Connect envisions coordinated research thrusts that produce design and management strategies for sustainable, next-generation computer systems. These strategies must flatten and then reverse growth trajectories for computing power and carbon for society's most rapidly growing applications such as artificial intelligence and virtual spaces. We will require accurate models for carbon accounting in computing technology. For embodied carbon, we must re-think conventional design strategies -- over-provisioned monolithic servers, frequent hardware refresh cycles, custom silicon -- and adopt life-cycle design strategies that more effectively reduce, reuse and recycle hardware at scale. For operational carbon, we must not only embrace renewable energy but also design systems to use that energy more efficiently. Finally, new hardware design and management strategies must be cognizant of economic policy and regulatory landscape, aligning private initiatives with societal goals. Many of these broader goals will require computer scientists to develop deep, enduring collaborations with researchers in economics, law, and industrial ecology to spark change in broader practice.
Label conditioned segmentation
Mar 17, 2022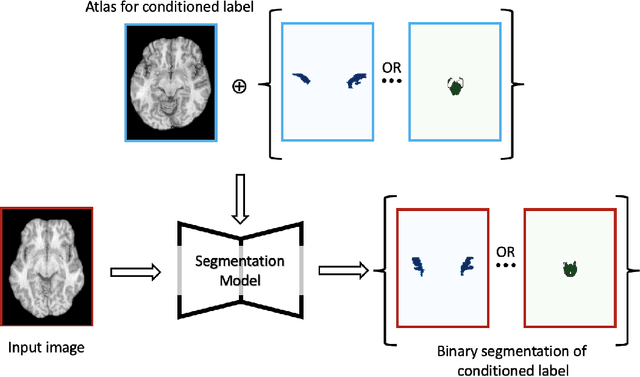
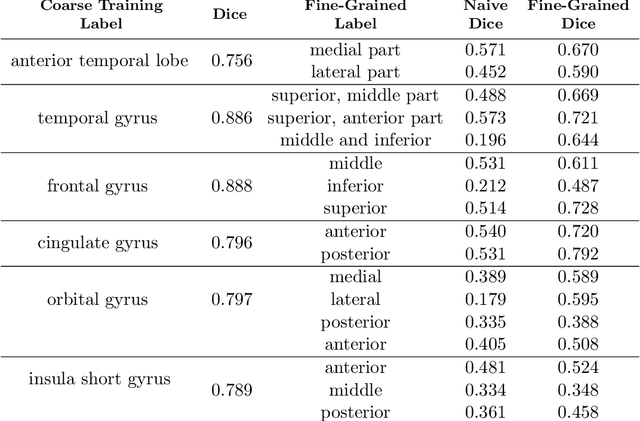
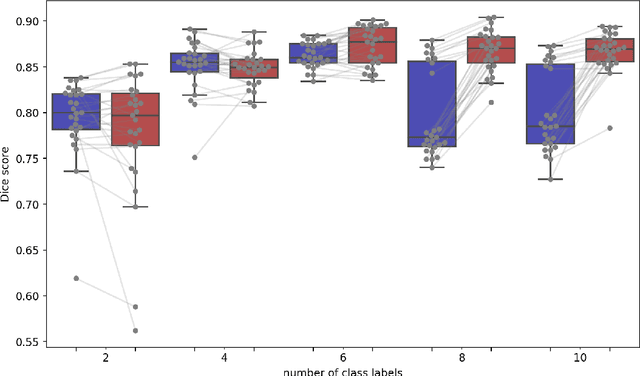
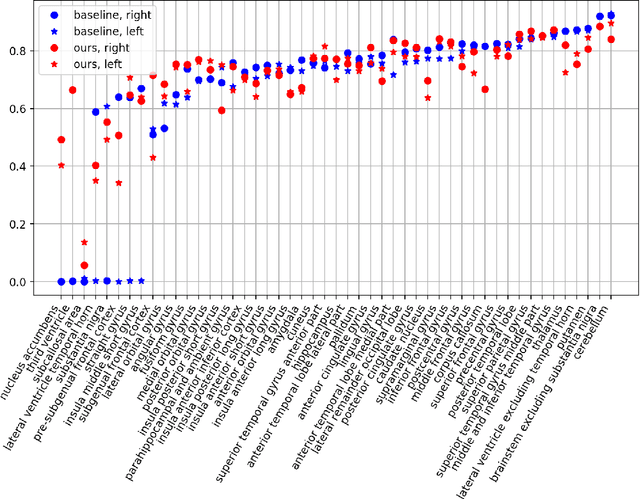
Semantic segmentation is an important task in computer vision that is often tackled with convolutional neural networks (CNNs). A CNN learns to produce pixel-level predictions through training on pairs of images and their corresponding ground-truth segmentation labels. For segmentation tasks with multiple classes, the standard approach is to use a network that computes a multi-channel probabilistic segmentation map, with each channel representing one class. In applications where the image grid size (e.g., when it is a 3D volume) and/or the number of labels is relatively large, the standard (baseline) approach can become prohibitively expensive for our computational resources. In this paper, we propose a simple yet effective method to address this challenge. In our approach, the segmentation network produces a single-channel output, while being conditioned on a single class label, which determines the output class of the network. Our method, called label conditioned segmentation (LCS), can be used to segment images with a very large number of classes, which might be infeasible for the baseline approach. We also demonstrate in the experiments that label conditioning can improve the accuracy of a given backbone architecture, likely, thanks to its parameter efficiency. Finally, as we show in our results, an LCS model can produce previously unseen fine-grained labels during inference time, when only coarse labels were available during training. We provide all of our code here: https://github.com/tym002/Label-conditioned-segmentation