 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Biological Data into Autonomous Remote Sensing Systems for In Situ Imageomics: A Case Study for Kenyan Animal Behavior Sensing with Unmanned Aerial Vehicles (UAVs)
Jul 23, 2024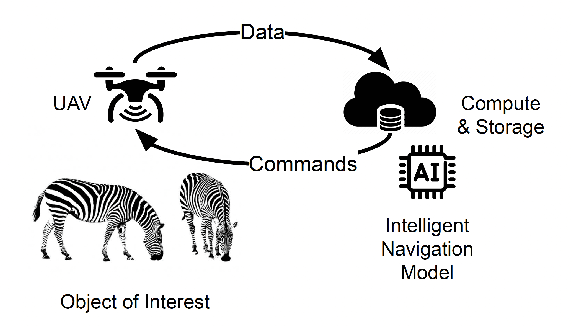



In situ imageomics leverages machine learning techniques to infer biological traits from images collected in the field, or in situ, to study individuals organisms, groups of wildlife, and whole ecosystems. Such datasets provide real-time social and environmental context to inferred biological traits, which can enable new, data-driven conservation and ecosystem management. The development of machine learning techniques to extract biological traits from images are impeded by the volume and quality data required to train these models. Autonomous, unmanned aerial vehicles (UAVs), are well suited to collect in situ imageomics data as they can traverse remote terrain quickly to collect large volumes of data with greater consistency and reliability compared to manually piloted UAV missions. However, little guidance exists on optimizing autonomous UAV missions for the purposes of remote sensing for conservation and biodiversity monitoring. The UAV video dataset curated by KABR: In-Situ Dataset for Kenyan Animal Behavior Recognition from Drone Videos required three weeks to collect, a time-consuming and expensive endeavor. Our analysis of KABR revealed that a third of the videos gathered were unusable for the purposes of inferring wildlife behavior. We analyzed the flight telemetry data from portions of UAV videos that were usable for inferring wildlife behavior, and demonstrate how these insights can be integrated into an autonomous remote sensing system to track wildlife in real time. Our autonomous remote sensing system optimizes the UAV's actions to increase the yield of usable data, and matches the flight path of an expert pilot with an 87% accuracy rate, representing an 18.2% improvement in accuracy over previously proposed methods.
Carbon Connect: An Ecosystem for Sustainable Computing
May 22, 2024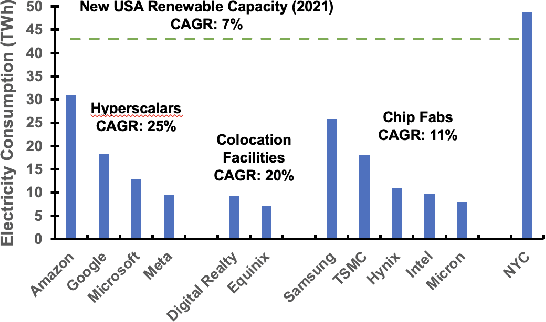
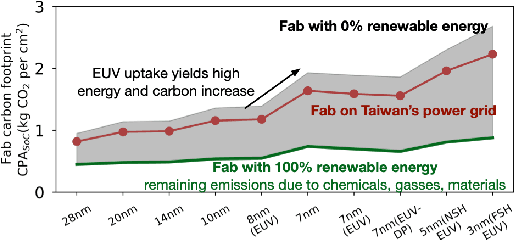
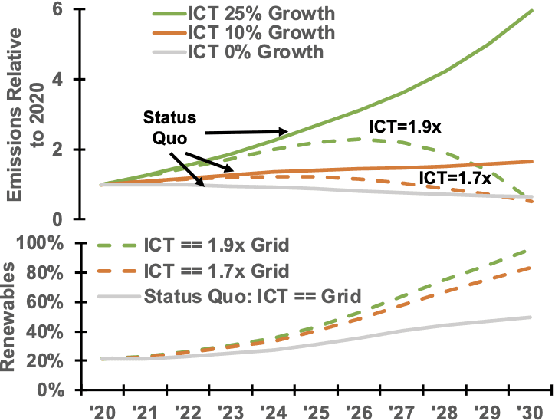
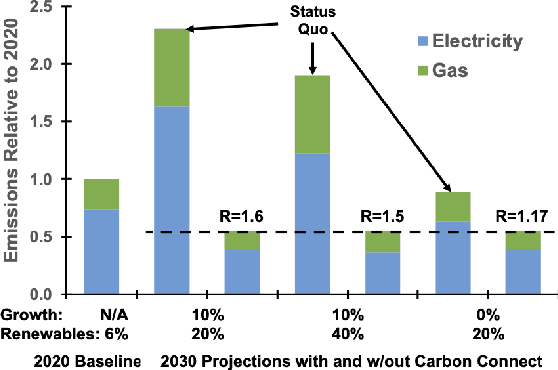
Computing is at a moment of profound opportunity. Emerging applications -- such as capable artificial intelligence, immersive virtual realities, and pervasive sensor systems -- drive unprecedented demand for computer. Despite recent advances toward net zero carbon emissions, the computing industry's gross energy usage continues to rise at an alarming rate, outpacing the growth of new energy installations and renewable energy deployments. A shift towards sustainability is needed to spark a transformation in how computer systems are manufactured, allocated, and consumed. Carbon Connect envisions coordinated research thrusts that produce design and management strategies for sustainable, next-generation computer systems. These strategies must flatten and then reverse growth trajectories for computing power and carbon for society's most rapidly growing applications such as artificial intelligence and virtual spaces. We will require accurate models for carbon accounting in computing technology. For embodied carbon, we must re-think conventional design strategies -- over-provisioned monolithic servers, frequent hardware refresh cycles, custom silicon -- and adopt life-cycle design strategies that more effectively reduce, reuse and recycle hardware at scale. For operational carbon, we must not only embrace renewable energy but also design systems to use that energy more efficiently. Finally, new hardware design and management strategies must be cognizant of economic policy and regulatory landscape, aligning private initiatives with societal goals. Many of these broader goals will require computer scientists to develop deep, enduring collaborations with researchers in economics, law, and industrial ecology to spark change in broader practice.
A Case for Dataset Specific Profiling
Aug 01, 2022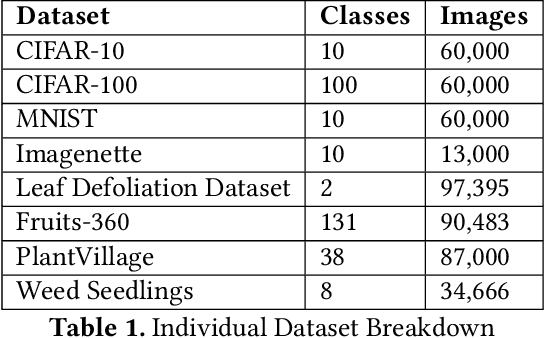
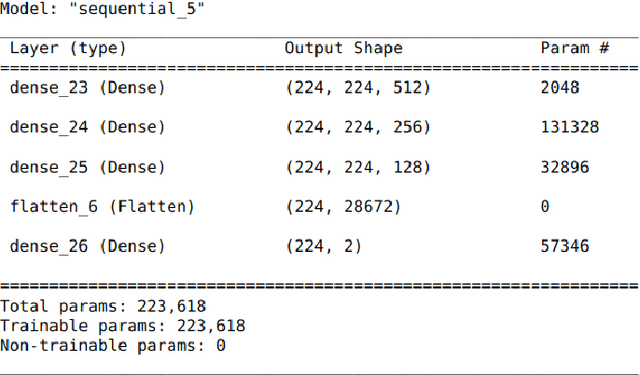
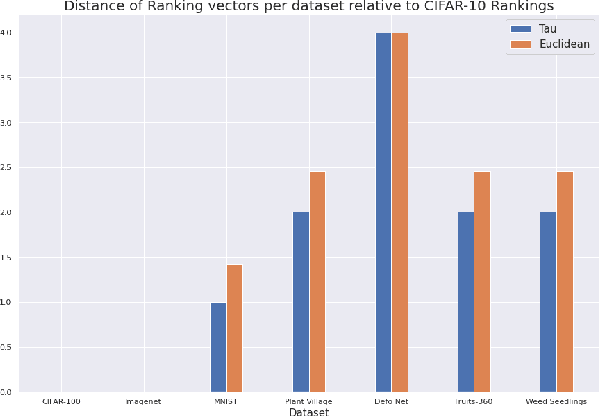
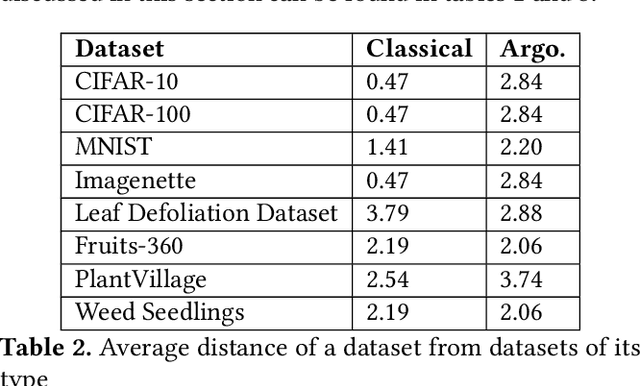
Data-driven science is an emerging paradigm where scientific discoveries depend on the execution of computational AI models against rich, discipline-specific datasets. With modern machine learning frameworks, anyone can develop and execute computational models that reveal concepts hidden in the data that could enable scientific applications. For important and widely used datasets, computing the performance of every computational model that can run against a dataset is cost prohibitive in terms of cloud resources. Benchmarking approaches used in practice use representative datasets to infer performance without actually executing models. While practicable, these approaches limit extensive dataset profiling to a few datasets and introduce bias that favors models suited for representative datasets. As a result, each dataset's unique characteristics are left unexplored and subpar models are selected based on inference from generalized datasets. This necessitates a new paradigm that introduces dataset profiling into the model selection process. To demonstrate the need for dataset-specific profiling, we answer two questions:(1) Can scientific datasets significantly permute the rank order of computational models compared to widely used representative datasets? (2) If so, could lightweight model execution improve benchmarking accuracy? Taken together, the answers to these questions lay the foundation for a new dataset-aware benchmarking paradigm.
Topic words analysis based on LDA model
May 15, 2014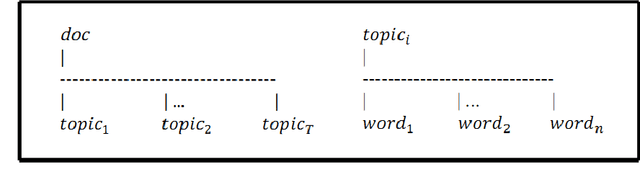
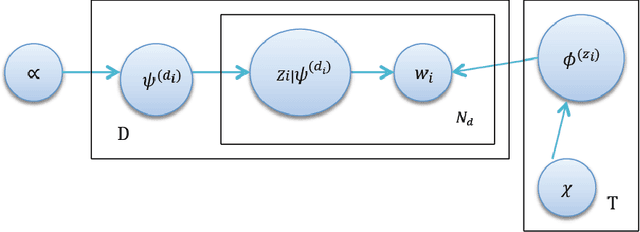
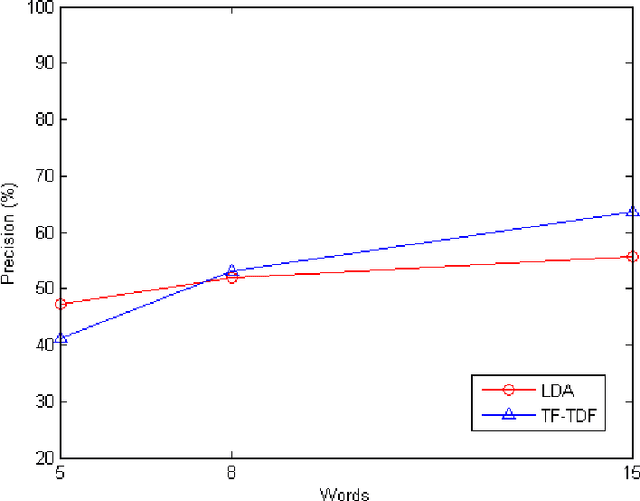
Social network analysis (SNA), which is a research field describing and modeling the social connection of a certain group of people, is popular among network services. Our topic words analysis project is a SNA method to visualize the topic words among emails from Obama.com to accounts registered in Columbus, Ohio. Based on Latent Dirichlet Allocation (LDA) model, a popular topic model of SNA, our project characterizes the preference of senders for target group of receptors. Gibbs sampling is used to estimate topic and word distribution. Our training and testing data are emails from the carbon-free server Datagreening.com. We use parallel computing tool BashReduce for word processing and generate related words under each latent topic to discovers typical information of political news sending specially to local Columbus receptors. Running on two instances using paralleling tool BashReduce, our project contributes almost 30% speedup processing the raw contents, comparing with processing contents on one instance locally. Also, the experimental result shows that the LDA model applied in our project provides precision rate 53.96% higher than TF-IDF model finding target words, on the condition that appropriate size of topic words list is selected.