 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Guide Towards Interpreting Time-Series Deep Clinical Predictive Models: A Reproducibility Study
Mar 25, 2026Clinical decisions are high-stakes and require explicit justification, making model interpretability essential for auditing deep clinical models prior to deployment. As the ecosystem of model architectures and explainability methods expands, critical questions remain: Do architectural features like attention improve explainability? Do interpretability approaches generalize across clinical tasks? While prior benchmarking efforts exist, they often lack extensibility and reproducibility, and critically, fail to systematically examine how interpretability varies across the interplay of clinical tasks and model architectures. To address these gaps, we present a comprehensive benchmark evaluating interpretability methods across diverse clinical prediction tasks and model architectures. Our analysis reveals that: (1) attention when leveraged properly is a highly efficient approach for faithfully interpreting model predictions; (2) black-box interpreters like KernelSHAP and LIME are computationally infeasible for time-series clinical prediction tasks; and (3) several interpretability approaches are too unreliable to be trustworthy. From our findings, we discuss several guidelines on improving interpretability within clinical predictive pipelines. To support reproducibility and extensibility, we provide our implementations via PyHealth, a well-documented open-source framework: https://github.com/sunlabuiuc/PyHealth.
A Modular LLM Framework for Explainable Price Outlier Detection
Mar 21, 2026Detecting product price outliers is important for retail and e-commerce stores as erroneous or unexpectedly high prices adversely affect competitiveness, revenue, and consumer trust. Classical techniques offer simple thresholds while ignoring the rich semantic relationships among product attributes. We propose an agentic Large Language Model (LLM) framework that treats outlier price flagging as a reasoning task grounded in related product detection and comparison. The system processes the prices of target products in three stages: (i) relevance classification selects price-relevant similar products using product descriptions and attributes; (ii) relative utility assessment evaluates the target product against each similar product along price influencing dimensions (e.g., brand, size, features); (iii) reasoning-based decision aggregates these justifications into an explainable price outlier judgment. The framework attains over 75% agreement with human auditors on a test dataset, and outperforms zero-shot and retrieval based LLM techniques. Ablation studies show the sensitivity of the method to key hyper-parameters and testify on its flexibility to be applied to cases with different accuracy requirement and auditor agreements.
Bridging the Reproducibility Divide: Open Source Software's Role in Standardizing Healthcare AI
Mar 02, 2026Our analysis of recent AI4H publications reveals that, despite a trend toward utilizing open datasets and sharing modeling code, 74% of AI4H papers still rely on private datasets or do not share their code. This is especially concerning in healthcare applications, where trust is essential. Furthermore, inconsistent and poorly documented data preprocessing pipelines result in variable model performance reports, even for identical tasks and datasets, making it challenging to evaluate the true effectiveness of AI models. Despite the challenges posed by the reproducibility crisis, addressing these issues through open practices offers substantial benefits. For instance, while the reproducibility mandate adds extra effort to research and publication, it significantly enhances the impact of the work. Our analysis shows that papers that used both public datasets and shared code received, on average, 110% more citations than those that do neither--more than doubling the citation count. Given the clear benefits of enhancing reproducibility, it is imperative for the AI4H community to take concrete steps to overcome existing barriers. The community should promote open science practices, establish standardized guidelines for data preprocessing, and develop robust benchmarks. Tackling these challenges through open-source development can improve reproducibility, which is essential for ensuring that AI models are safe, effective, and beneficial for patient care. This approach will help build more trustworthy AI systems that can be integrated into healthcare settings, ultimately contributing to better patient outcomes and advancing the field of medicine.
Making Conformal Predictors Robust in Healthcare Settings: a Case Study on EEG Classification
Feb 23, 2026Quantifying uncertainty in clinical predictions is critical for high-stakes diagnosis tasks. Conformal prediction offers a principled approach by providing prediction sets with theoretical coverage guarantees. However, in practice, patient distribution shifts violate the i.i.d. assumptions underlying standard conformal methods, leading to poor coverage in healthcare settings. In this work, we evaluate several conformal prediction approaches on EEG seizure classification, a task with known distribution shift challenges and label uncertainty. We demonstrate that personalized calibration strategies can improve coverage by over 20 percentage points while maintaining comparable prediction set sizes. Our implementation is available via PyHealth, an open-source healthcare AI framework: https://github.com/sunlabuiuc/PyHealth.
PyHealth 2.0: A Comprehensive Open-Source Toolkit for Accessible and Reproducible Clinical Deep Learning
Jan 23, 2026Difficulty replicating baselines, high computational costs, and required domain expertise create persistent barriers to clinical AI research. To address these challenges, we introduce PyHealth 2.0, an enhanced clinical deep learning toolkit that enables predictive modeling in as few as 7 lines of code. PyHealth 2.0 offers three key contributions: (1) a comprehensive toolkit addressing reproducibility and compatibility challenges by unifying 15+ datasets, 20+ clinical tasks, 25+ models, 5+ interpretability methods, and uncertainty quantification including conformal prediction within a single framework that supports diverse clinical data modalities - signals, imaging, and electronic health records - with translation of 5+ medical coding standards; (2) accessibility-focused design accommodating multimodal data and diverse computational resources with up to 39x faster processing and 20x lower memory usage, enabling work from 16GB laptops to production systems; and (3) an active open-source community of 400+ members lowering domain expertise barriers through extensive documentation, reproducible research contributions, and collaborations with academic health systems and industry partners, including multi-language support via RHealth. PyHealth 2.0 establishes an open-source foundation and community advancing accessible, reproducible healthcare AI. Available at pip install pyhealth.
Beyond Label Attention: Transparency in Language Models for Automated Medical Coding via Dictionary Learning
Oct 31, 2024



Medical coding, the translation of unstructured clinical text into standardized medical codes, is a crucial but time-consuming healthcare practice. Though large language models (LLM) could automate the coding process and improve the efficiency of such tasks, interpretability remains paramount for maintaining patient trust. Current efforts in interpretability of medical coding applications rely heavily on label attention mechanisms, which often leads to the highlighting of extraneous tokens irrelevant to the ICD code. To facilitate accurate interpretability in medical language models, this paper leverages dictionary learning that can efficiently extract sparsely activated representations from dense language model embeddings in superposition. Compared with common label attention mechanisms, our model goes beyond token-level representations by building an interpretable dictionary which enhances the mechanistic-based explanations for each ICD code prediction, even when the highlighted tokens are medically irrelevant. We show that dictionary features can steer model behavior, elucidate the hidden meanings of upwards of 90% of medically irrelevant tokens, and are human interpretable.
DILA: Dictionary Label Attention for Mechanistic Interpretability in High-dimensional Multi-label Medical Coding Prediction
Sep 16, 2024



Predicting high-dimensional or extreme multilabels, such as in medical coding, requires both accuracy and interpretability. Existing works often rely on local interpretability methods, failing to provide comprehensive explanations of the overall mechanism behind each label prediction within a multilabel set. We propose a mechanistic interpretability module called DIctionary Label Attention (\method) that disentangles uninterpretable dense embeddings into a sparse embedding space, where each nonzero element (a dictionary feature) represents a globally learned medical concept. Through human evaluations, we show that our sparse embeddings are more human understandable than its dense counterparts by at least 50 percent. Our automated dictionary feature identification pipeline, leveraging large language models (LLMs), uncovers thousands of learned medical concepts by examining and summarizing the highest activating tokens for each dictionary feature. We represent the relationships between dictionary features and medical codes through a sparse interpretable matrix, enhancing the mechanistic and global understanding of the model's predictions while maintaining competitive performance and scalability without extensive human annotation.
If LLM Is the Wizard, Then Code Is the Wand: A Survey on How Code Empowers Large Language Models to Serve as Intelligent Agents
Jan 08, 2024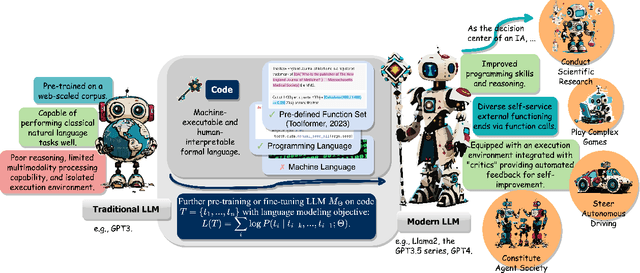
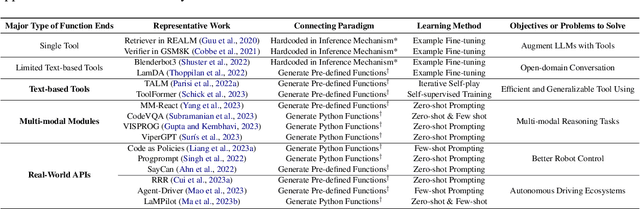
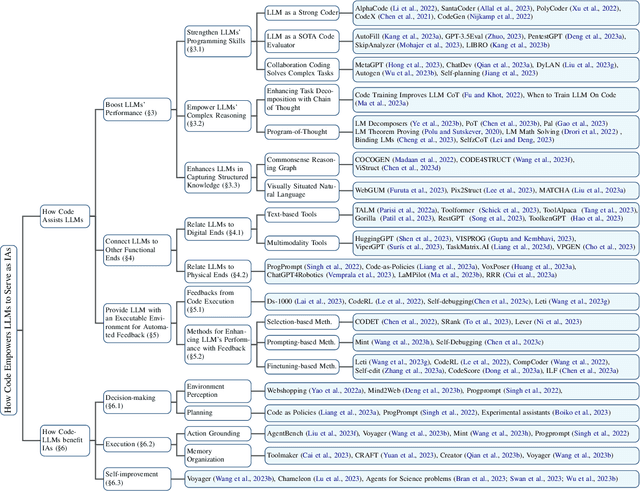

The prominent large language models (LLMs) of today differ from past language models not only in size, but also in the fact that they are trained on a combination of natural language and formal language (code). As a medium between humans and computers, code translates high-level goals into executable steps, featuring standard syntax, logical consistency, abstraction, and modularity. In this survey, we present an overview of the various benefits of integrating code into LLMs' training data. Specifically, beyond enhancing LLMs in code generation, we observe that these unique properties of code help (i) unlock the reasoning ability of LLMs, enabling their applications to a range of more complex natural language tasks; (ii) steer LLMs to produce structured and precise intermediate steps, which can then be connected to external execution ends through function calls; and (iii) take advantage of code compilation and execution environment, which also provides diverse feedback for model improvement. In addition, we trace how these profound capabilities of LLMs, brought by code, have led to their emergence as intelligent agents (IAs) in situations where the ability to understand instructions, decompose goals, plan and execute actions, and refine from feedback are crucial to their success on downstream tasks. Finally, we present several key challenges and future directions of empowering LLMs with code.
A Case for Dataset Specific Profiling
Aug 01, 2022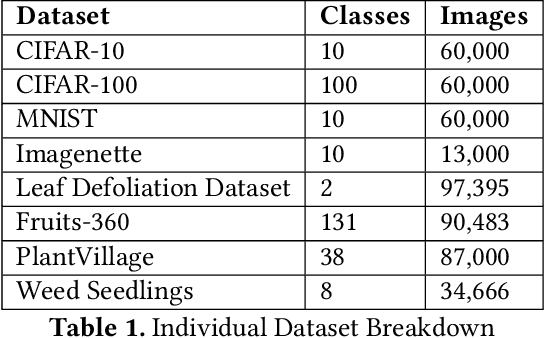
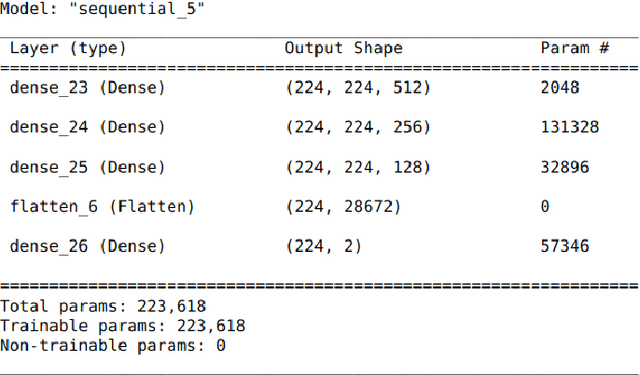
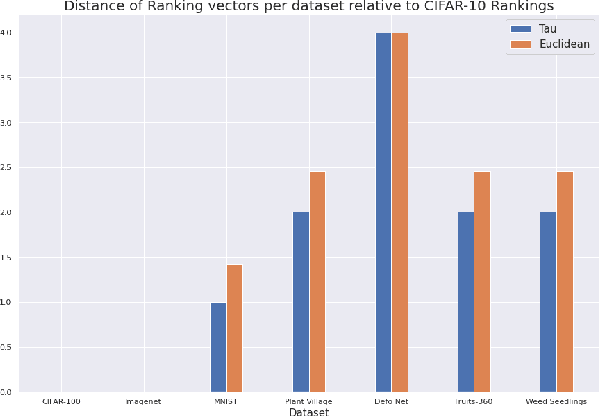
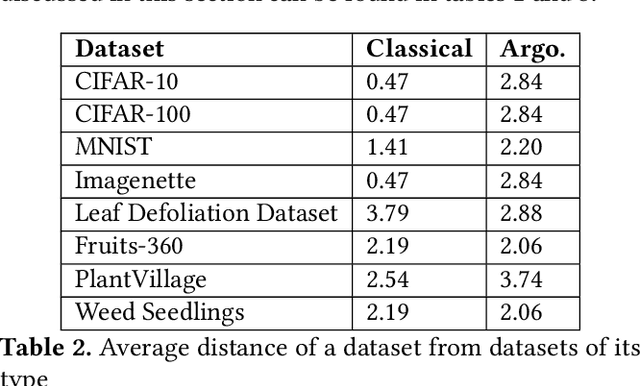
Data-driven science is an emerging paradigm where scientific discoveries depend on the execution of computational AI models against rich, discipline-specific datasets. With modern machine learning frameworks, anyone can develop and execute computational models that reveal concepts hidden in the data that could enable scientific applications. For important and widely used datasets, computing the performance of every computational model that can run against a dataset is cost prohibitive in terms of cloud resources. Benchmarking approaches used in practice use representative datasets to infer performance without actually executing models. While practicable, these approaches limit extensive dataset profiling to a few datasets and introduce bias that favors models suited for representative datasets. As a result, each dataset's unique characteristics are left unexplored and subpar models are selected based on inference from generalized datasets. This necessitates a new paradigm that introduces dataset profiling into the model selection process. To demonstrate the need for dataset-specific profiling, we answer two questions:(1) Can scientific datasets significantly permute the rank order of computational models compared to widely used representative datasets? (2) If so, could lightweight model execution improve benchmarking accuracy? Taken together, the answers to these questions lay the foundation for a new dataset-aware benchmarking paradigm.