 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrimming the Long-Tail of Visual World Modeling Evaluation
Jun 23, 2026Physical interactions follow a long-tailed distribution: a set of common and regular interactions dominates human experience and visual data, while a broad spectrum of rare and irregular interactions remains underrepresented. Although recent visual world models, including image and video generation models, achieve impressive realism on existing benchmarks, they primarily focus on simulating common physical interactions. This raises a central question: Do current visual world models internalize and generalize physical principles? In this work, we introduce Tailor-Bench, a benchmark that challenges world models to simulate irregular physical interactions. To enable systematic evaluation, we design three scenario modes that progressively challenge model reasoning: Regular scenarios reflect common tool-task pairs, Unconventional scenarios replace conventional tools with attribute-compatible substitutes to test affordance generalization, and Impossible scenarios introduce attribute-violating tools to probe constraint awareness. Additionally, we design two complementary settings under a unified evaluation protocol: predictive generation requires inferring outcomes without guidance, while descriptive generation specifies the target outcome for faithful realization. Our experimental results reveal a clear long-tail gap in physical world modeling: performance degrades from Regular to Unconventional and Impossible scenarios, indicating limited generalization beyond common interactions. Failure analysis further shows that models rely on superficial visual patterns: image models fail to realize correct state changes, while video models further suffer from temporal inconsistencies.
AdaPlanBench: Evaluating Adaptive Planning in Large Language Model Agents under World and User Constraints
Jun 04, 2026Planning for real-world problems by language models often involves both world and user constraints, which may not be fully specified upfront and are progressively disclosed through interaction. However, existing benchmarks still underexplore adaptive planning under such progressively revealed dual constraints. To address this gap, we introduce AdaPlanBench, a dynamic interactive benchmark for evaluating whether Large Language Model (LLM) agents can adaptively plan and re-plan under progressively revealed world and user constraints. AdaPlanBench is built on 307 household tasks, with a scalable constraint construction pipeline that augments each task with dual constraints. At runtime, agents interact with the environment in a multi-turn protocol where hidden constraints are revealed only when the agent proposes a plan that violates them, requiring iterative plan revision under accumulating feedback. This makes planning challenging, as agents must infer and track constraints from feedback while re-planning effectively. Experiments on ten leading LLMs show that adaptive planning under dual constraints remains challenging, with the best model reaching only 67.75% accuracy. We further observe that performance degrades as more constraints accumulate, with user constraints posing a particularly large challenge and failures often stemming from weaker physical grounding and reduced effectiveness. These results establish AdaPlanBench as a testbed for dual-constrained interactive planning and highlight the challenge of reliable adaptation to dynamically revealed constraints in LLM agents.
Brick-Composer: Using MLLMs for Assembly with Diverse Bricks
Jun 03, 2026We dream of AI agents that can read arbitrary designs and construct real-world objects from reusable building blocks. As a first step toward this vision, we study whether multimodal large language models (MLLMs) possess the visual grounding and spatial reasoning capabilities required for brick assembly. We formulate brick assembly as a sequential decision-making problem, where each step involves two subtasks: brick selection, identifying the target brick from candidate components, and brick pose estimation, predicting where and how the selected brick should be placed. To support this study, we introduce BC-Bench (Brick Construction Benchmark), the first benchmark for evaluating MLLMs on assembly with diverse bricks. Experiments show that current state-of-the-art MLLMs remain far from reliable builders, struggling with fine-grained brick selection and failing at precise pose estimation. To bridge this gap, we propose Brick-Composer, a learning framework that equips MLLMs with assembly skills through three complementary signals: Human Design Sparks, which provide affordance-rich construction demonstrations; World Feedback, which grounds predicted actions in visual and physical consequences; and Synthetic Experience, which scales learning beyond existing object designs. Brick-Composer improves brick selection accuracy by over three times, substantially reduces pose estimation errors, and raises strict step-level assembly success from less than 1% to around 15%. After training, a Qwen-3-8B can correctly compose up to 42% of the steps for a complete object, suggesting that MLLMs can acquire assembly capabilities through targeted, physically grounded learning.
Advancing Creative Physical Intelligence in Large Multimodal Models
May 25, 2026Large multimodal models (LMMs) have rapidly advanced in perception and reasoning; however, it remains unclear whether these capabilities generalize to discovering visually grounded solutions in open-ended environments, beyond pattern recognition. In such settings, intelligence requires more than answering well-posed questions: it involves identifying how elements in a scene can be repurposed in non-obvious yet physically feasible ways. This form of creative problem-solving is central to human intelligence, but remains largely untested in current benchmarks. To evaluate this ability, we introduce MM-CreativityBench, a benchmark for affordance-grounded creative tool use in visually rich, physically constrained environments. Each instance presents a scenario image with structured views of candidate entities and their parts, enabling fine-grained, interactive evaluation of how models iteratively inspect the scene, identify relevant affordances, and compose visually and physically grounded solutions. Our experiments show that current LMMs often fall short, not due to lack of generative capability, but because they do not sustain grounded exploration. Models often overlook relevant entities, under-examine critical parts, or hallucinate attributes not grounded in the image. Motivated by this failure mode, we propose affordance-grounded alignment, which casts creative tool use as a preference learning problem. Using Direct Preference Optimization, we encourage models to prefer attribute-affordance reasoning grounded in visual evidence over hallucinated alternatives. In addition, we incorporate supervision derived from an affordance knowledge base to guide broader entity exploration and multi-turn planning. Our results show consistent gains in selecting the correct entities and parts, while substantially reducing hallucination and grounding-related errors.
EgoForge: Goal-Directed Egocentric World Simulator
Mar 20, 2026Generative world models have shown promise for simulating dynamic environments, yet egocentric video remains challenging due to rapid viewpoint changes, frequent hand-object interactions, and goal-directed procedures whose evolution depends on latent human intent. Existing approaches either focus on hand-centric instructional synthesis with limited scene evolution, perform static view translation without modeling action dynamics, or rely on dense supervision, such as camera trajectories, long video prefixes, synchronized multicamera capture, etc. In this work, we introduce EgoForge, an egocentric goal-directed world simulator that generates coherent, first-person video rollouts from minimal static inputs: a single egocentric image, a high-level instruction, and an optional auxiliary exocentric view. To improve intent alignment and temporal consistency, we propose VideoDiffusionNFT, a trajectory-level reward-guided refinement that optimizes goal completion, temporal causality, scene consistency, and perceptual fidelity during diffusion sampling. Extensive experiments show EgoForge achieves consistent gains in semantic alignment, geometric stability, and motion fidelity over strong baselines, and robust performance in real-world smart-glasses experiments.
OSExpert: Computer-Use Agents Learning Professional Skills via Exploration
Mar 09, 2026General-purpose computer-use agents have shown impressive performance across diverse digital environments. However, our new benchmark, OSExpert-Eval, indicates they remain far less helpful than human experts. Although inference-time scaling enables adaptation, these agents complete complex tasks inefficiently with degraded performance, transfer poorly to unseen UIs, and struggle with fine-grained action sequences. To solve the problem, we introduce a GUI-based depth-first search (GUI-DFS) exploration algorithm to comprehensively explore and verify an environment's unit functions. The agent then exploits compositionality between unit skills to self-construct a curriculum for composite tasks. To support fine-grained actions, we curate a database of action primitives for agents to discover during exploration; these are saved as a skill set once the exploration is complete. We use the learned skills to improve the agent's performance and efficiency by (1) enriching agents with ready-to-use procedural knowledge, allowing them to plan only once for long trajectories and generate accurate actions, and (2) enabling them to end inference-time scaling earlier by realizing their boundary of capabilities. Extensive experiments show that our environment-learned agent takes a meaningful step toward expert-level computer use, achieving a around 20 percent performance gain on OSExpert-Eval and closing the efficiency gap to humans by around 80 percent
Toward Cognitive Supersensing in Multimodal Large Language Model
Feb 02, 2026Multimodal Large Language Models (MLLMs) have achieved remarkable success in open-vocabulary perceptual tasks, yet their ability to solve complex cognitive problems remains limited, especially when visual details are abstract and require visual memory. Current approaches primarily scale Chain-of-Thought (CoT) reasoning in the text space, even when language alone is insufficient for clear and structured reasoning, and largely neglect visual reasoning mechanisms analogous to the human visuospatial sketchpad and visual imagery. To mitigate this deficiency, we introduce Cognitive Supersensing, a novel training paradigm that endows MLLMs with human-like visual imagery capabilities by integrating a Latent Visual Imagery Prediction (LVIP) head that jointly learns sequences of visual cognitive latent embeddings and aligns them with the answer, thereby forming vision-based internal reasoning chains. We further introduce a reinforcement learning stage that optimizes text reasoning paths based on this grounded visual latent. To evaluate the cognitive capabilities of MLLMs, we present CogSense-Bench, a comprehensive visual question answering (VQA) benchmark assessing five cognitive dimensions. Extensive experiments demonstrate that MLLMs trained with Cognitive Supersensing significantly outperform state-of-the-art baselines on CogSense-Bench and exhibit superior generalization on out-of-domain mathematics and science VQA benchmarks, suggesting that internal visual imagery is potentially key to bridging the gap between perceptual recognition and cognitive understanding. We will open-source the CogSense-Bench and our model weights.
Multimodal Policy Internalization for Conversational Agents
Oct 10, 2025Modern conversational agents like ChatGPT and Alexa+ rely on predefined policies specifying metadata, response styles, and tool-usage rules. As these LLM-based systems expand to support diverse business and user queries, such policies, often implemented as in-context prompts, are becoming increasingly complex and lengthy, making faithful adherence difficult and imposing large fixed computational costs. With the rise of multimodal agents, policies that govern visual and multimodal behaviors are critical but remain understudied. Prior prompt-compression work mainly shortens task templates and demonstrations, while existing policy-alignment studies focus only on text-based safety rules. We introduce Multimodal Policy Internalization (MPI), a new task that internalizes reasoning-intensive multimodal policies into model parameters, enabling stronger policy-following without including the policy during inference. MPI poses unique data and algorithmic challenges. We build two datasets spanning synthetic and real-world decision-making and tool-using tasks and propose TriMPI, a three-stage training framework. TriMPI first injects policy knowledge via continual pretraining, then performs supervised finetuning, and finally applies PolicyRollout, a GRPO-style reinforcement learning extension that augments rollouts with policy-aware responses for grounded exploration. TriMPI achieves notable gains in end-to-end accuracy, generalization, and robustness to forgetting. As the first work on multimodal policy internalization, we provide datasets, training recipes, and comprehensive evaluations to foster future research. Project page: https://mikewangwzhl.github.io/TriMPI.
Effective Gaussian Management for High-fidelity Object Reconstruction
Sep 16, 2025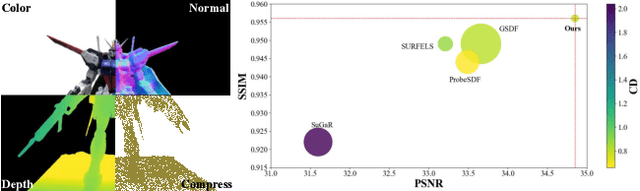
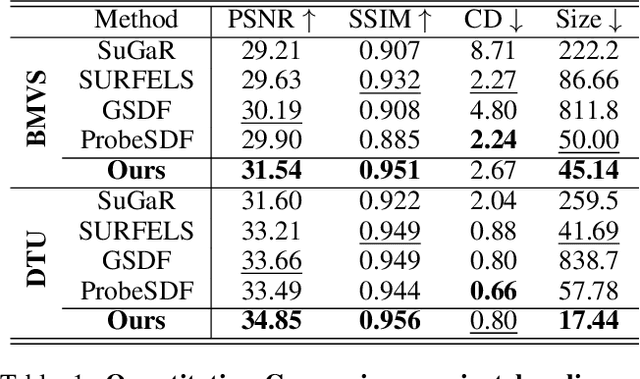
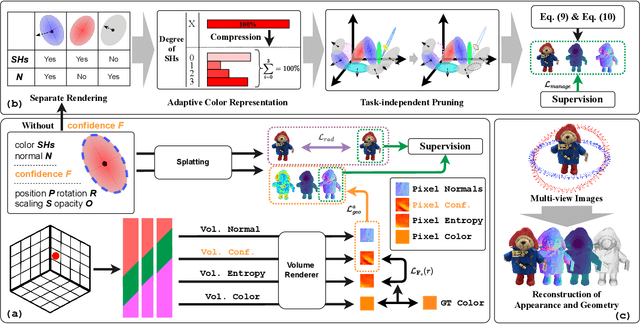
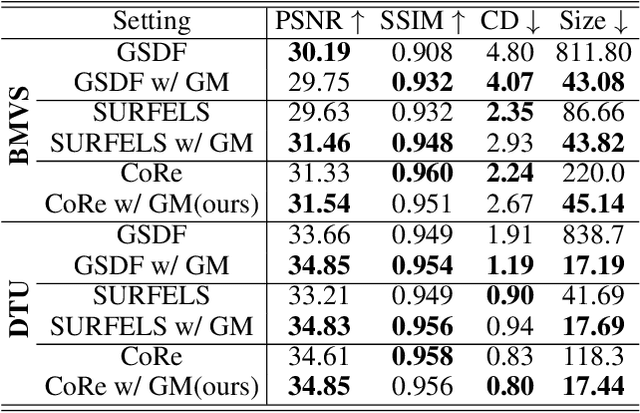
This paper proposes an effective Gaussian management approach for high-fidelity object reconstruction. Departing from recent Gaussian Splatting (GS) methods that employ indiscriminate attribute assignment, our approach introduces a novel densification strategy that dynamically activates spherical harmonics (SHs) or normals under the supervision of a surface reconstruction module, which effectively mitigates the gradient conflicts caused by dual supervision and achieves superior reconstruction results. To further improve representation efficiency, we develop a lightweight Gaussian representation that adaptively adjusts the SH orders of each Gaussian based on gradient magnitudes and performs task-decoupled pruning to remove Gaussian with minimal impact on a reconstruction task without sacrificing others, which balances the representational capacity with parameter quantity. Notably, our management approach is model-agnostic and can be seamlessly integrated into other frameworks, enhancing performance while reducing model size. Extensive experiments demonstrate that our approach consistently outperforms state-of-the-art approaches in both reconstruction quality and efficiency, achieving superior performance with significantly fewer parameters.
ISACL: Internal State Analyzer for Copyrighted Training Data Leakage
Aug 25, 2025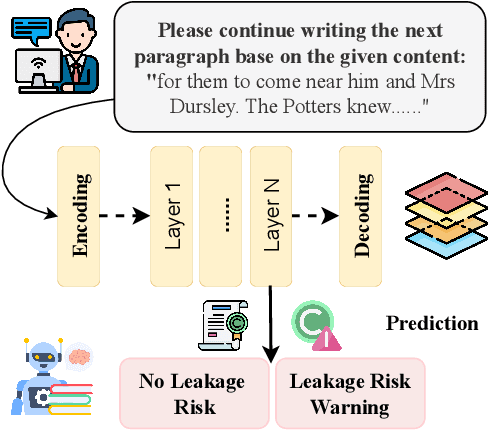
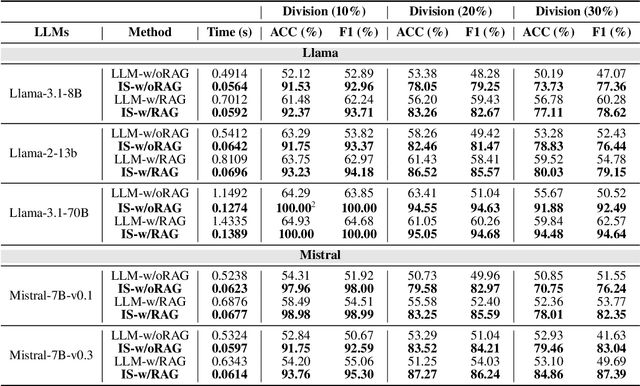
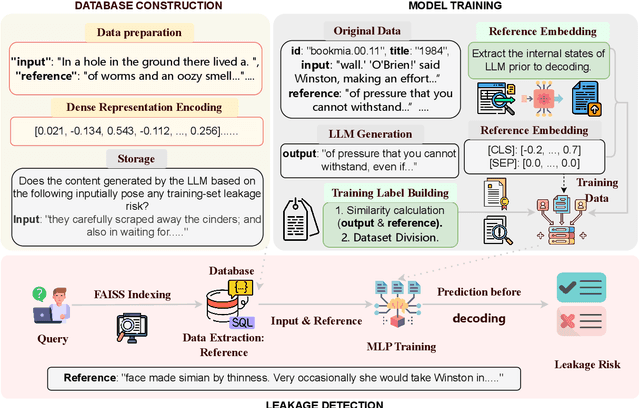
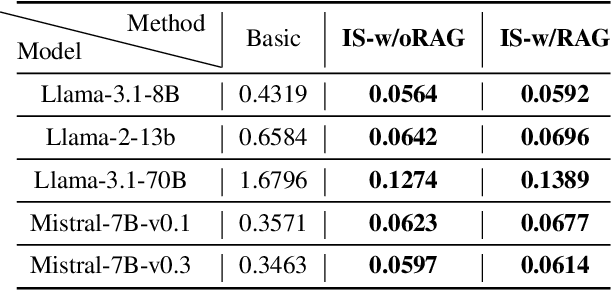
Large Language Models (LLMs) have revolutionized Natural Language Processing (NLP) but pose risks of inadvertently exposing copyrighted or proprietary data, especially when such data is used for training but not intended for distribution. Traditional methods address these leaks only after content is generated, which can lead to the exposure of sensitive information. This study introduces a proactive approach: examining LLMs' internal states before text generation to detect potential leaks. By using a curated dataset of copyrighted materials, we trained a neural network classifier to identify risks, allowing for early intervention by stopping the generation process or altering outputs to prevent disclosure. Integrated with a Retrieval-Augmented Generation (RAG) system, this framework ensures adherence to copyright and licensing requirements while enhancing data privacy and ethical standards. Our results show that analyzing internal states effectively mitigates the risk of copyrighted data leakage, offering a scalable solution that fits smoothly into AI workflows, ensuring compliance with copyright regulations while maintaining high-quality text generation. The implementation is available on GitHub.\footnote{https://github.com/changhu73/Internal_states_leakage}