 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoE3D: A Mixture-of-Experts Module for 3D Reconstruction
Jan 08, 2026MoE3D is a mixture-of-experts module designed to sharpen depth boundaries and mitigate flying-point artifacts (highlighted in red) of existing feed-forward 3D reconstruction models (left side). MoE3D predicts multiple candidate depth maps and fuses them via dynamic weighting (visualized by MoE weights on the right side). When integrated with a pre-trained 3D reconstruction backbone such as VGGT, it substantially enhances reconstruction quality with minimal additional computational overhead. Best viewed digitally.
Generative Spatiotemporal Data Augmentation
Dec 14, 2025We explore spatiotemporal data augmentation using video foundation models to diversify both camera viewpoints and scene dynamics. Unlike existing approaches based on simple geometric transforms or appearance perturbations, our method leverages off-the-shelf video diffusion models to generate realistic 3D spatial and temporal variations from a given image dataset. Incorporating these synthesized video clips as supplemental training data yields consistent performance gains in low-data settings, such as UAV-captured imagery where annotations are scarce. Beyond empirical improvements, we provide practical guidelines for (i) choosing an appropriate spatiotemporal generative setup, (ii) transferring annotations to synthetic frames, and (iii) addressing disocclusion - regions newly revealed and unlabeled in generated views. Experiments on COCO subsets and UAV-captured datasets show that, when applied judiciously, spatiotemporal augmentation broadens the data distribution along axes underrepresented by traditional and prior generative methods, offering an effective lever for improving model performance in data-scarce regimes.
VideoPDE: Unified Generative PDE Solving via Video Inpainting Diffusion Models
Jun 16, 2025We present a unified framework for solving partial differential equations (PDEs) using video-inpainting diffusion transformer models. Unlike existing methods that devise specialized strategies for either forward or inverse problems under full or partial observation, our approach unifies these tasks under a single, flexible generative framework. Specifically, we recast PDE-solving as a generalized inpainting problem, e.g., treating forward prediction as inferring missing spatiotemporal information of future states from initial conditions. To this end, we design a transformer-based architecture that conditions on arbitrary patterns of known data to infer missing values across time and space. Our method proposes pixel-space video diffusion models for fine-grained, high-fidelity inpainting and conditioning, while enhancing computational efficiency through hierarchical modeling. Extensive experiments show that our video inpainting-based diffusion model offers an accurate and versatile solution across a wide range of PDEs and problem setups, outperforming state-of-the-art baselines.
SIR-DIFF: Sparse Image Sets Restoration with Multi-View Diffusion Model
Mar 18, 2025The computer vision community has developed numerous techniques for digitally restoring true scene information from single-view degraded photographs, an important yet extremely ill-posed task. In this work, we tackle image restoration from a different perspective by jointly denoising multiple photographs of the same scene. Our core hypothesis is that degraded images capturing a shared scene contain complementary information that, when combined, better constrains the restoration problem. To this end, we implement a powerful multi-view diffusion model that jointly generates uncorrupted views by extracting rich information from multi-view relationships. Our experiments show that our multi-view approach outperforms existing single-view image and even video-based methods on image deblurring and super-resolution tasks. Critically, our model is trained to output 3D consistent images, making it a promising tool for applications requiring robust multi-view integration, such as 3D reconstruction or pose estimation.
LIFT-GS: Cross-Scene Render-Supervised Distillation for 3D Language Grounding
Feb 27, 2025Our approach to training 3D vision-language understanding models is to train a feedforward model that makes predictions in 3D, but never requires 3D labels and is supervised only in 2D, using 2D losses and differentiable rendering. The approach is new for vision-language understanding. By treating the reconstruction as a ``latent variable'', we can render the outputs without placing unnecessary constraints on the network architecture (e.g. can be used with decoder-only models). For training, only need images and camera pose, and 2D labels. We show that we can even remove the need for 2D labels by using pseudo-labels from pretrained 2D models. We demonstrate this to pretrain a network, and we finetune it for 3D vision-language understanding tasks. We show this approach outperforms baselines/sota for 3D vision-language grounding, and also outperforms other 3D pretraining techniques. Project page: https://liftgs.github.io.
Taming Feed-forward Reconstruction Models as Latent Encoders for 3D Generative Models
Jan 04, 2025



Recent AI-based 3D content creation has largely evolved along two paths: feed-forward image-to-3D reconstruction approaches and 3D generative models trained with 2D or 3D supervision. In this work, we show that existing feed-forward reconstruction methods can serve as effective latent encoders for training 3D generative models, thereby bridging these two paradigms. By reusing powerful pre-trained reconstruction models, we avoid computationally expensive encoder network training and obtain rich 3D latent features for generative modeling for free. However, the latent spaces of reconstruction models are not well-suited for generative modeling due to their unstructured nature. To enable flow-based model training on these latent features, we develop post-processing pipelines, including protocols to standardize the features and spatial weighting to concentrate on important regions. We further incorporate a 2D image space perceptual rendering loss to handle the high-dimensional latent spaces. Finally, we propose a multi-stream transformer-based rectified flow architecture to achieve linear scaling and high-quality text-conditioned 3D generation. Our framework leverages the advancements of feed-forward reconstruction models to enhance the scalability of 3D generative modeling, achieving both high computational efficiency and state-of-the-art performance in text-to-3D generation.
Cocoon: Robust Multi-Modal Perception with Uncertainty-Aware Sensor Fusion
Oct 16, 2024
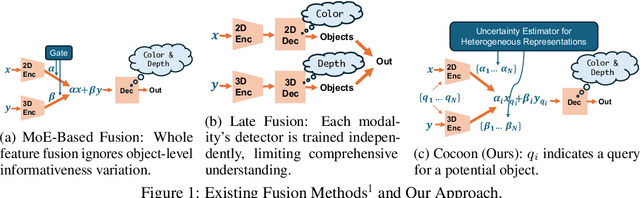
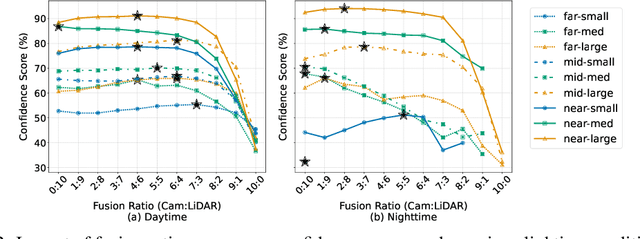
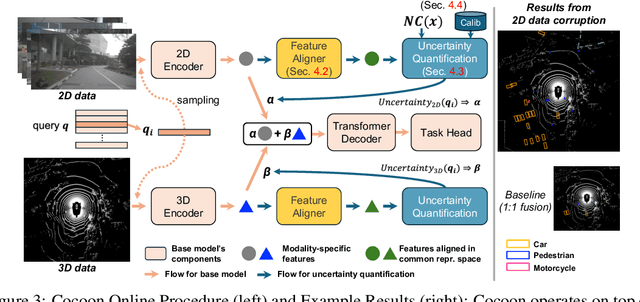
An important paradigm in 3D object detection is the use of multiple modalities to enhance accuracy in both normal and challenging conditions, particularly for long-tail scenarios. To address this, recent studies have explored two directions of adaptive approaches: MoE-based adaptive fusion, which struggles with uncertainties arising from distinct object configurations, and late fusion for output-level adaptive fusion, which relies on separate detection pipelines and limits comprehensive understanding. In this work, we introduce Cocoon, an object- and feature-level uncertainty-aware fusion framework. The key innovation lies in uncertainty quantification for heterogeneous representations, enabling fair comparison across modalities through the introduction of a feature aligner and a learnable surrogate ground truth, termed feature impression. We also define a training objective to ensure that their relationship provides a valid metric for uncertainty quantification. Cocoon consistently outperforms existing static and adaptive methods in both normal and challenging conditions, including those with natural and artificial corruptions. Furthermore, we show the validity and efficacy of our uncertainty metric across diverse datasets.
This&That: Language-Gesture Controlled Video Generation for Robot Planning
Jul 08, 2024We propose a robot learning method for communicating, planning, and executing a wide range of tasks, dubbed This&That. We achieve robot planning for general tasks by leveraging the power of video generative models trained on internet-scale data containing rich physical and semantic context. In this work, we tackle three fundamental challenges in video-based planning: 1) unambiguous task communication with simple human instructions, 2) controllable video generation that respects user intents, and 3) translating visual planning into robot actions. We propose language-gesture conditioning to generate videos, which is both simpler and clearer than existing language-only methods, especially in complex and uncertain environments. We then suggest a behavioral cloning design that seamlessly incorporates the video plans. This&That demonstrates state-of-the-art effectiveness in addressing the above three challenges, and justifies the use of video generation as an intermediate representation for generalizable task planning and execution. Project website: https://cfeng16.github.io/this-and-that/.
DiffusionPDE: Generative PDE-Solving Under Partial Observation
Jun 25, 2024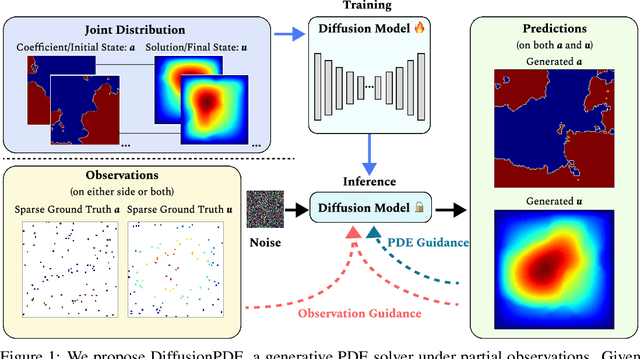
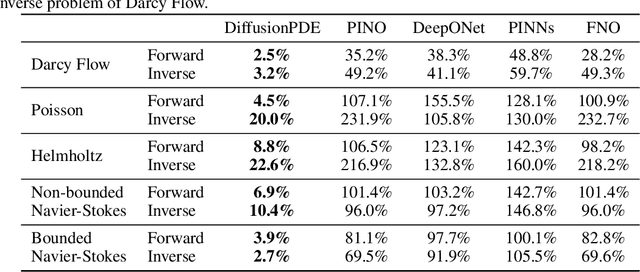
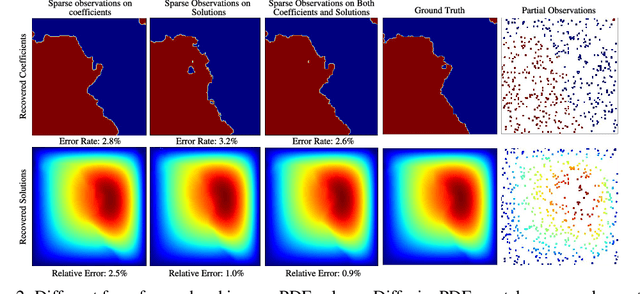

We introduce a general framework for solving partial differential equations (PDEs) using generative diffusion models. In particular, we focus on the scenarios where we do not have the full knowledge of the scene necessary to apply classical solvers. Most existing forward or inverse PDE approaches perform poorly when the observations on the data or the underlying coefficients are incomplete, which is a common assumption for real-world measurements. In this work, we propose DiffusionPDE that can simultaneously fill in the missing information and solve a PDE by modeling the joint distribution of the solution and coefficient spaces. We show that the learned generative priors lead to a versatile framework for accurately solving a wide range of PDEs under partial observation, significantly outperforming the state-of-the-art methods for both forward and inverse directions.
TC4D: Trajectory-Conditioned Text-to-4D Generation
Apr 11, 2024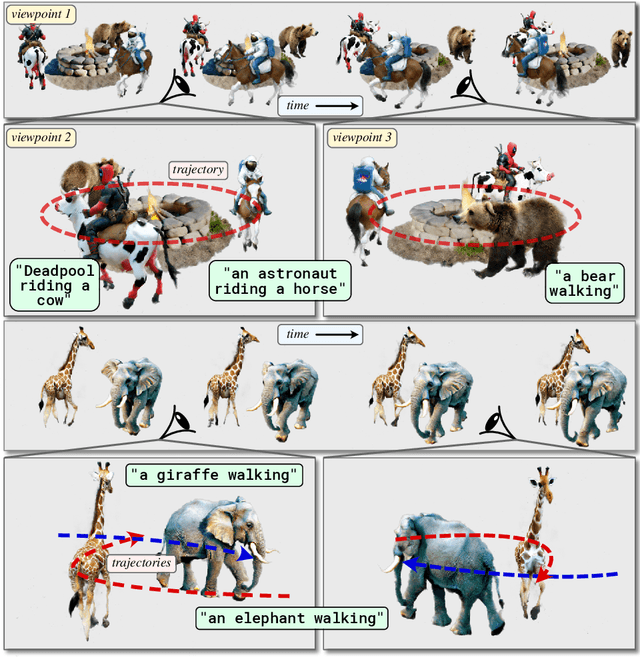
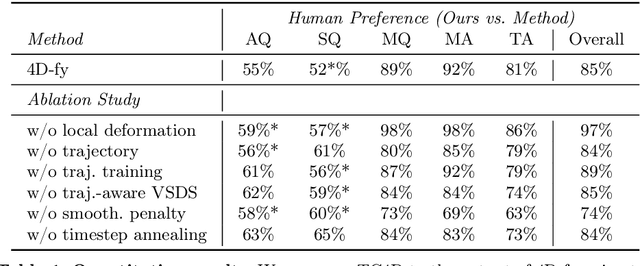

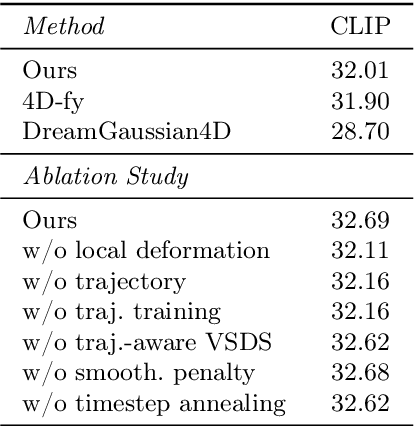
Recent techniques for text-to-4D generation synthesize dynamic 3D scenes using supervision from pre-trained text-to-video models. However, existing representations for motion, such as deformation models or time-dependent neural representations, are limited in the amount of motion they can generate-they cannot synthesize motion extending far beyond the bounding box used for volume rendering. The lack of a more flexible motion model contributes to the gap in realism between 4D generation methods and recent, near-photorealistic video generation models. Here, we propose TC4D: trajectory-conditioned text-to-4D generation, which factors motion into global and local components. We represent the global motion of a scene's bounding box using rigid transformation along a trajectory parameterized by a spline. We learn local deformations that conform to the global trajectory using supervision from a text-to-video model. Our approach enables the synthesis of scenes animated along arbitrary trajectories, compositional scene generation, and significant improvements to the realism and amount of generated motion, which we evaluate qualitatively and through a user study. Video results can be viewed on our website: https://sherwinbahmani.github.io/tc4d.