 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLyra 2.0: Explorable Generative 3D Worlds
Apr 14, 2026Recent advances in video generation enable a new paradigm for 3D scene creation: generating camera-controlled videos that simulate scene walkthroughs, then lifting them to 3D via feed-forward reconstruction techniques. This generative reconstruction approach combines the visual fidelity and creative capacity of video models with 3D outputs ready for real-time rendering and simulation. Scaling to large, complex environments requires 3D-consistent video generation over long camera trajectories with large viewpoint changes and location revisits, a setting where current video models degrade quickly. Existing methods for long-horizon generation are fundamentally limited by two forms of degradation: spatial forgetting and temporal drifting. As exploration proceeds, previously observed regions fall outside the model's temporal context, forcing the model to hallucinate structures when revisited. Meanwhile, autoregressive generation accumulates small synthesis errors over time, gradually distorting scene appearance and geometry. We present Lyra 2.0, a framework for generating persistent, explorable 3D worlds at scale. To address spatial forgetting, we maintain per-frame 3D geometry and use it solely for information routing -- retrieving relevant past frames and establishing dense correspondences with the target viewpoints -- while relying on the generative prior for appearance synthesis. To address temporal drifting, we train with self-augmented histories that expose the model to its own degraded outputs, teaching it to correct drift rather than propagate it. Together, these enable substantially longer and 3D-consistent video trajectories, which we leverage to fine-tune feed-forward reconstruction models that reliably recover high-quality 3D scenes.
Grow with the Flow: 4D Reconstruction of Growing Plants with Gaussian Flow Fields
Feb 09, 2026Modeling the time-varying 3D appearance of plants during their growth poses unique challenges: unlike many dynamic scenes, plants generate new geometry over time as they expand, branch, and differentiate. Recent motion modeling techniques are ill-suited to this problem setting. For example, deformation fields cannot introduce new geometry, and 4D Gaussian splatting constrains motion to a linear trajectory in space and time and cannot track the same set of Gaussians over time. Here, we introduce a 3D Gaussian flow field representation that models plant growth as a time-varying derivative over Gaussian parameters -- position, scale, orientation, color, and opacity -- enabling nonlinear and continuous-time growth dynamics. To initialize a sufficient set of Gaussian primitives, we reconstruct the mature plant and learn a process of reverse growth, effectively simulating the plant's developmental history in reverse. Our approach achieves superior image quality and geometric accuracy compared to prior methods on multi-view timelapse datasets of plant growth, providing a new approach for appearance modeling of growing 3D structures.
MVP4D: Multi-View Portrait Video Diffusion for Animatable 4D Avatars
Oct 14, 2025Digital human avatars aim to simulate the dynamic appearance of humans in virtual environments, enabling immersive experiences across gaming, film, virtual reality, and more. However, the conventional process for creating and animating photorealistic human avatars is expensive and time-consuming, requiring large camera capture rigs and significant manual effort from professional 3D artists. With the advent of capable image and video generation models, recent methods enable automatic rendering of realistic animated avatars from a single casually captured reference image of a target subject. While these techniques significantly lower barriers to avatar creation and offer compelling realism, they lack constraints provided by multi-view information or an explicit 3D representation. So, image quality and realism degrade when rendered from viewpoints that deviate strongly from the reference image. Here, we build a video model that generates animatable multi-view videos of digital humans based on a single reference image and target expressions. Our model, MVP4D, is based on a state-of-the-art pre-trained video diffusion model and generates hundreds of frames simultaneously from viewpoints varying by up to 360 degrees around a target subject. We show how to distill the outputs of this model into a 4D avatar that can be rendered in real-time. Our approach significantly improves the realism, temporal consistency, and 3D consistency of generated avatars compared to previous methods.
AC3D: Analyzing and Improving 3D Camera Control in Video Diffusion Transformers
Dec 02, 2024



Numerous works have recently integrated 3D camera control into foundational text-to-video models, but the resulting camera control is often imprecise, and video generation quality suffers. In this work, we analyze camera motion from a first principles perspective, uncovering insights that enable precise 3D camera manipulation without compromising synthesis quality. First, we determine that motion induced by camera movements in videos is low-frequency in nature. This motivates us to adjust train and test pose conditioning schedules, accelerating training convergence while improving visual and motion quality. Then, by probing the representations of an unconditional video diffusion transformer, we observe that they implicitly perform camera pose estimation under the hood, and only a sub-portion of their layers contain the camera information. This suggested us to limit the injection of camera conditioning to a subset of the architecture to prevent interference with other video features, leading to 4x reduction of training parameters, improved training speed and 10% higher visual quality. Finally, we complement the typical dataset for camera control learning with a curated dataset of 20K diverse dynamic videos with stationary cameras. This helps the model disambiguate the difference between camera and scene motion, and improves the dynamics of generated pose-conditioned videos. We compound these findings to design the Advanced 3D Camera Control (AC3D) architecture, the new state-of-the-art model for generative video modeling with camera control.
SG-I2V: Self-Guided Trajectory Control in Image-to-Video Generation
Nov 07, 2024



Methods for image-to-video generation have achieved impressive, photo-realistic quality. However, adjusting specific elements in generated videos, such as object motion or camera movement, is often a tedious process of trial and error, e.g., involving re-generating videos with different random seeds. Recent techniques address this issue by fine-tuning a pre-trained model to follow conditioning signals, such as bounding boxes or point trajectories. Yet, this fine-tuning procedure can be computationally expensive, and it requires datasets with annotated object motion, which can be difficult to procure. In this work, we introduce SG-I2V, a framework for controllable image-to-video generation that is self-guided$\unicode{x2013}$offering zero-shot control by relying solely on the knowledge present in a pre-trained image-to-video diffusion model without the need for fine-tuning or external knowledge. Our zero-shot method outperforms unsupervised baselines while being competitive with supervised models in terms of visual quality and motion fidelity.
VD3D: Taming Large Video Diffusion Transformers for 3D Camera Control
Jul 17, 2024



Modern text-to-video synthesis models demonstrate coherent, photorealistic generation of complex videos from a text description. However, most existing models lack fine-grained control over camera movement, which is critical for downstream applications related to content creation, visual effects, and 3D vision. Recently, new methods demonstrate the ability to generate videos with controllable camera poses these techniques leverage pre-trained U-Net-based diffusion models that explicitly disentangle spatial and temporal generation. Still, no existing approach enables camera control for new, transformer-based video diffusion models that process spatial and temporal information jointly. Here, we propose to tame video transformers for 3D camera control using a ControlNet-like conditioning mechanism that incorporates spatiotemporal camera embeddings based on Plucker coordinates. The approach demonstrates state-of-the-art performance for controllable video generation after fine-tuning on the RealEstate10K dataset. To the best of our knowledge, our work is the first to enable camera control for transformer-based video diffusion models.
TC4D: Trajectory-Conditioned Text-to-4D Generation
Apr 11, 2024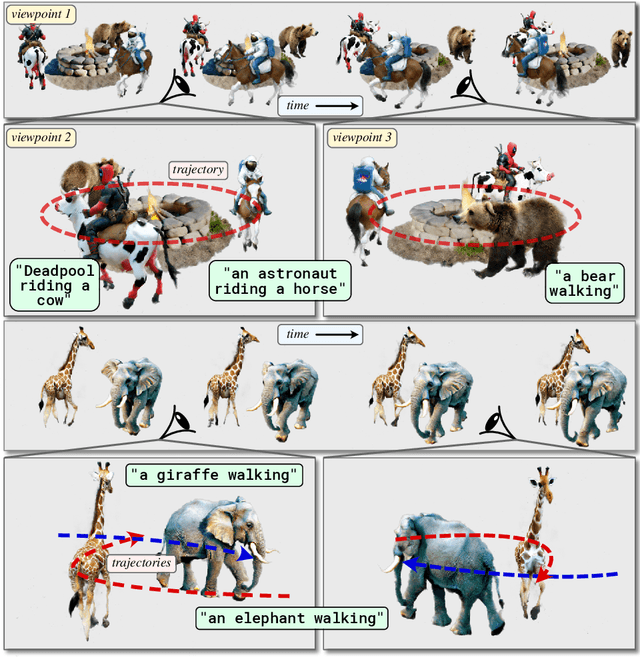
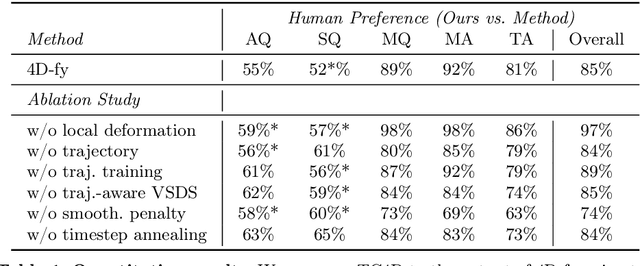

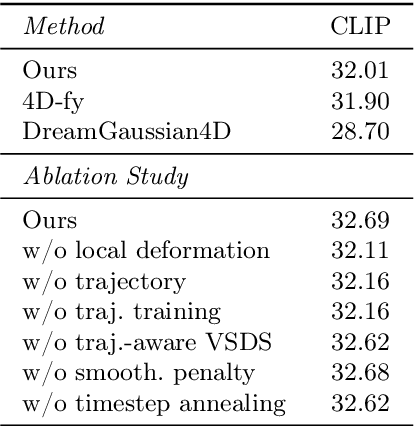
Recent techniques for text-to-4D generation synthesize dynamic 3D scenes using supervision from pre-trained text-to-video models. However, existing representations for motion, such as deformation models or time-dependent neural representations, are limited in the amount of motion they can generate-they cannot synthesize motion extending far beyond the bounding box used for volume rendering. The lack of a more flexible motion model contributes to the gap in realism between 4D generation methods and recent, near-photorealistic video generation models. Here, we propose TC4D: trajectory-conditioned text-to-4D generation, which factors motion into global and local components. We represent the global motion of a scene's bounding box using rigid transformation along a trajectory parameterized by a spline. We learn local deformations that conform to the global trajectory using supervision from a text-to-video model. Our approach enables the synthesis of scenes animated along arbitrary trajectories, compositional scene generation, and significant improvements to the realism and amount of generated motion, which we evaluate qualitatively and through a user study. Video results can be viewed on our website: https://sherwinbahmani.github.io/tc4d.
4D-fy: Text-to-4D Generation Using Hybrid Score Distillation Sampling
Nov 29, 2023Recent breakthroughs in text-to-4D generation rely on pre-trained text-to-image and text-to-video models to generate dynamic 3D scenes. However, current text-to-4D methods face a three-way tradeoff between the quality of scene appearance, 3D structure, and motion. For example, text-to-image models and their 3D-aware variants are trained on internet-scale image datasets and can be used to produce scenes with realistic appearance and 3D structure -- but no motion. Text-to-video models are trained on relatively smaller video datasets and can produce scenes with motion, but poorer appearance and 3D structure. While these models have complementary strengths, they also have opposing weaknesses, making it difficult to combine them in a way that alleviates this three-way tradeoff. Here, we introduce hybrid score distillation sampling, an alternating optimization procedure that blends supervision signals from multiple pre-trained diffusion models and incorporates benefits of each for high-fidelity text-to-4D generation. Using hybrid SDS, we demonstrate synthesis of 4D scenes with compelling appearance, 3D structure, and motion.
CC3D: Layout-Conditioned Generation of Compositional 3D Scenes
Mar 21, 2023


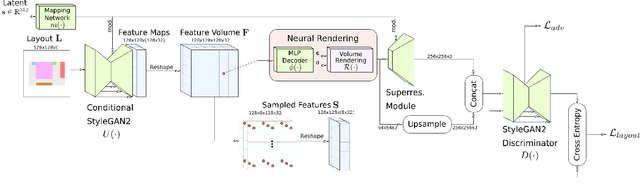
In this work, we introduce CC3D, a conditional generative model that synthesizes complex 3D scenes conditioned on 2D semantic scene layouts, trained using single-view images. Different from most existing 3D GANs that limit their applicability to aligned single objects, we focus on generating complex scenes with multiple objects, by modeling the compositional nature of 3D scenes. By devising a 2D layout-based approach for 3D synthesis and implementing a new 3D field representation with a stronger geometric inductive bias, we have created a 3D GAN that is both efficient and of high quality, while allowing for a more controllable generation process. Our evaluations on synthetic 3D-FRONT and real-world KITTI-360 datasets demonstrate that our model generates scenes of improved visual and geometric quality in comparison to previous works.
Semantic Self-adaptation: Enhancing Generalization with a Single Sample
Aug 10, 2022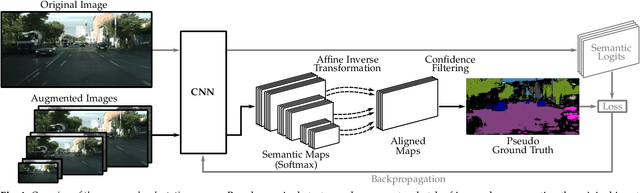


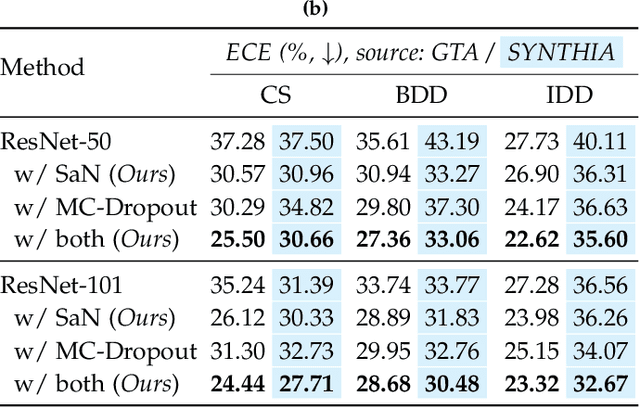
Despite years of research, out-of-domain generalization remains a critical weakness of deep networks for semantic segmentation. Previous studies relied on the assumption of a static model, i.e. once the training process is complete, model parameters remain fixed at test time. In this work, we challenge this premise with a self-adaptive approach for semantic segmentation that adjusts the inference process to each input sample. Self-adaptation operates on two levels. First, it employs a self-supervised loss that customizes the parameters of convolutional layers in the network to the input image. Second, in Batch Normalization layers, self-adaptation approximates the mean and the variance of the entire test data, which is assumed unavailable. It achieves this by interpolating between the training and the reference distribution derived from a single test sample. To empirically analyze our self-adaptive inference strategy, we develop and follow a rigorous evaluation protocol that addresses serious limitations of previous work. Our extensive analysis leads to a surprising conclusion: Using a standard training procedure, self-adaptation significantly outperforms strong baselines and sets new state-of-the-art accuracy on multi-domain benchmarks. Our study suggests that self-adaptive inference may complement the established practice of model regularization at training time for improving deep network generalization to out-of-domain data.