 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Self-adaptation: Enhancing Generalization with a Single Sample
Paper and Code
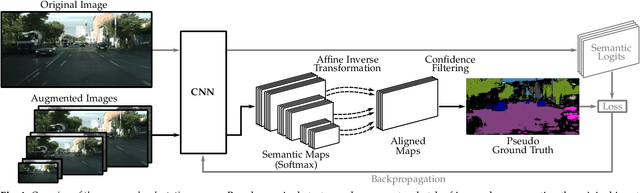


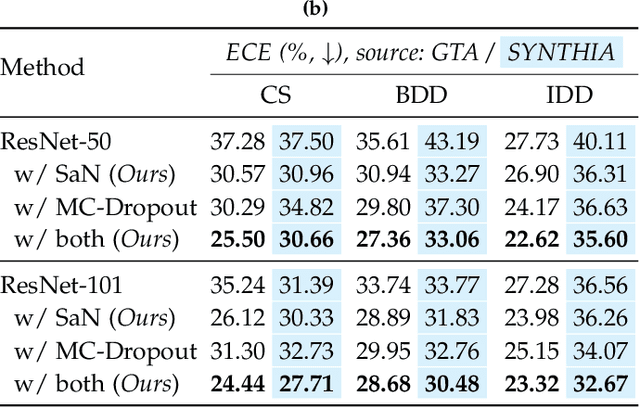
Despite years of research, out-of-domain generalization remains a critical weakness of deep networks for semantic segmentation. Previous studies relied on the assumption of a static model, i.e. once the training process is complete, model parameters remain fixed at test time. In this work, we challenge this premise with a self-adaptive approach for semantic segmentation that adjusts the inference process to each input sample. Self-adaptation operates on two levels. First, it employs a self-supervised loss that customizes the parameters of convolutional layers in the network to the input image. Second, in Batch Normalization layers, self-adaptation approximates the mean and the variance of the entire test data, which is assumed unavailable. It achieves this by interpolating between the training and the reference distribution derived from a single test sample. To empirically analyze our self-adaptive inference strategy, we develop and follow a rigorous evaluation protocol that addresses serious limitations of previous work. Our extensive analysis leads to a surprising conclusion: Using a standard training procedure, self-adaptation significantly outperforms strong baselines and sets new state-of-the-art accuracy on multi-domain benchmarks. Our study suggests that self-adaptive inference may complement the established practice of model regularization at training time for improving deep network generalization to out-of-domain data.