 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeed-Forward SceneDINO for Unsupervised Semantic Scene Completion
Jul 08, 2025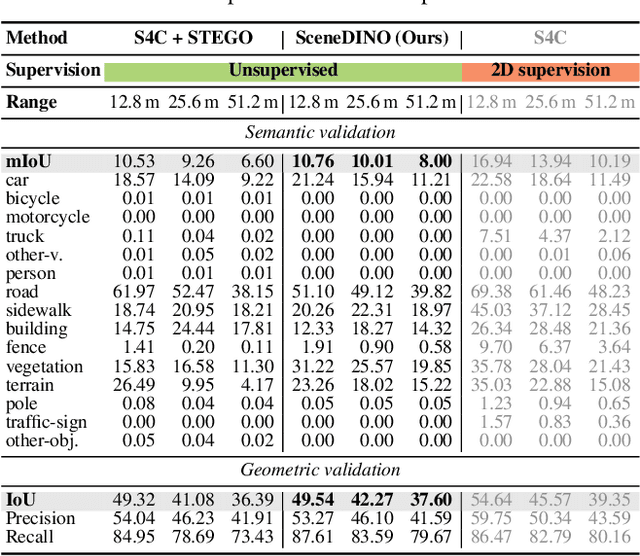
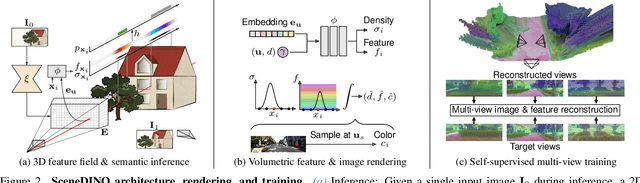

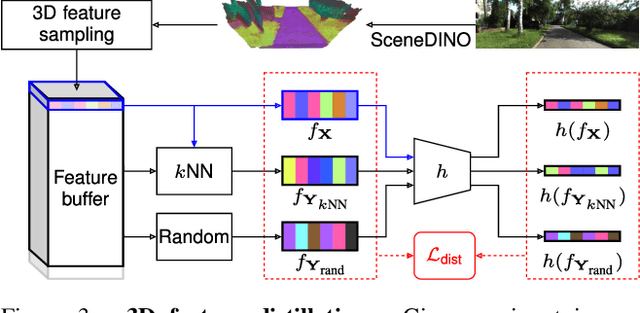
Semantic scene completion (SSC) aims to infer both the 3D geometry and semantics of a scene from single images. In contrast to prior work on SSC that heavily relies on expensive ground-truth annotations, we approach SSC in an unsupervised setting. Our novel method, SceneDINO, adapts techniques from self-supervised representation learning and 2D unsupervised scene understanding to SSC. Our training exclusively utilizes multi-view consistency self-supervision without any form of semantic or geometric ground truth. Given a single input image, SceneDINO infers the 3D geometry and expressive 3D DINO features in a feed-forward manner. Through a novel 3D feature distillation approach, we obtain unsupervised 3D semantics. In both 3D and 2D unsupervised scene understanding, SceneDINO reaches state-of-the-art segmentation accuracy. Linear probing our 3D features matches the segmentation accuracy of a current supervised SSC approach. Additionally, we showcase the domain generalization and multi-view consistency of SceneDINO, taking the first steps towards a strong foundation for single image 3D scene understanding.
Scene-Centric Unsupervised Panoptic Segmentation
Apr 02, 2025Unsupervised panoptic segmentation aims to partition an image into semantically meaningful regions and distinct object instances without training on manually annotated data. In contrast to prior work on unsupervised panoptic scene understanding, we eliminate the need for object-centric training data, enabling the unsupervised understanding of complex scenes. To that end, we present the first unsupervised panoptic method that directly trains on scene-centric imagery. In particular, we propose an approach to obtain high-resolution panoptic pseudo labels on complex scene-centric data, combining visual representations, depth, and motion cues. Utilizing both pseudo-label training and a panoptic self-training strategy yields a novel approach that accurately predicts panoptic segmentation of complex scenes without requiring any human annotations. Our approach significantly improves panoptic quality, e.g., surpassing the recent state of the art in unsupervised panoptic segmentation on Cityscapes by 9.4% points in PQ.
Boosting Omnidirectional Stereo Matching with a Pre-trained Depth Foundation Model
Mar 30, 2025Omnidirectional depth perception is essential for mobile robotics applications that require scene understanding across a full 360{\deg} field of view. Camera-based setups offer a cost-effective option by using stereo depth estimation to generate dense, high-resolution depth maps without relying on expensive active sensing. However, existing omnidirectional stereo matching approaches achieve only limited depth accuracy across diverse environments, depth ranges, and lighting conditions, due to the scarcity of real-world data. We present DFI-OmniStereo, a novel omnidirectional stereo matching method that leverages a large-scale pre-trained foundation model for relative monocular depth estimation within an iterative optimization-based stereo matching architecture. We introduce a dedicated two-stage training strategy to utilize the relative monocular depth features for our omnidirectional stereo matching before scale-invariant fine-tuning. DFI-OmniStereo achieves state-of-the-art results on the real-world Helvipad dataset, reducing disparity MAE by approximately 16% compared to the previous best omnidirectional stereo method.
Boosting Unsupervised Semantic Segmentation with Principal Mask Proposals
Apr 25, 2024



Unsupervised semantic segmentation aims to automatically partition images into semantically meaningful regions by identifying global categories within an image corpus without any form of annotation. Building upon recent advances in self-supervised representation learning, we focus on how to leverage these large pre-trained models for the downstream task of unsupervised segmentation. We present PriMaPs - Principal Mask Proposals - decomposing images into semantically meaningful masks based on their feature representation. This allows us to realize unsupervised semantic segmentation by fitting class prototypes to PriMaPs with a stochastic expectation-maximization algorithm, PriMaPs-EM. Despite its conceptual simplicity, PriMaPs-EM leads to competitive results across various pre-trained backbone models, including DINO and DINOv2, and across datasets, such as Cityscapes, COCO-Stuff, and Potsdam-3. Importantly, PriMaPs-EM is able to boost results when applied orthogonally to current state-of-the-art unsupervised semantic segmentation pipelines.
A Perspective on Deep Vision Performance with Standard Image and Video Codecs
Apr 18, 2024

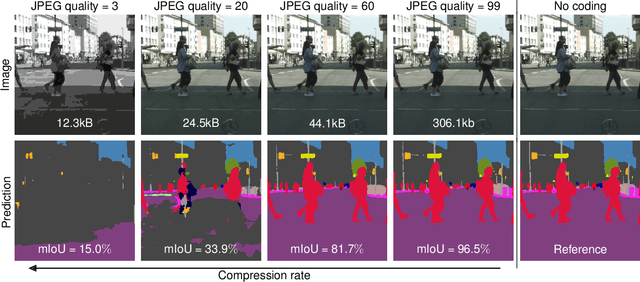
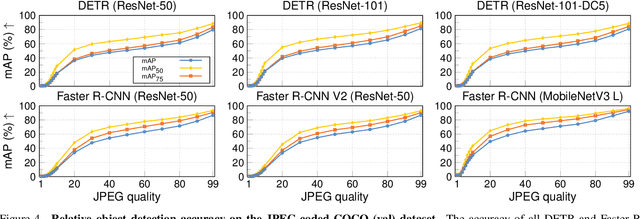
Resource-constrained hardware, such as edge devices or cell phones, often rely on cloud servers to provide the required computational resources for inference in deep vision models. However, transferring image and video data from an edge or mobile device to a cloud server requires coding to deal with network constraints. The use of standardized codecs, such as JPEG or H.264, is prevalent and required to ensure interoperability. This paper aims to examine the implications of employing standardized codecs within deep vision pipelines. We find that using JPEG and H.264 coding significantly deteriorates the accuracy across a broad range of vision tasks and models. For instance, strong compression rates reduce semantic segmentation accuracy by more than 80% in mIoU. In contrast to previous findings, our analysis extends beyond image and action classification to localization and dense prediction tasks, thus providing a more comprehensive perspective.
A deep learning framework for jointly extracting spectra and source-count distributions in astronomy
Jan 06, 2024Astronomical observations typically provide three-dimensional maps, encoding the distribution of the observed flux in (1) the two angles of the celestial sphere and (2) energy/frequency. An important task regarding such maps is to statistically characterize populations of point sources too dim to be individually detected. As the properties of a single dim source will be poorly constrained, instead one commonly studies the population as a whole, inferring a source-count distribution (SCD) that describes the number density of sources as a function of their brightness. Statistical and machine learning methods for recovering SCDs exist; however, they typically entirely neglect spectral information associated with the energy distribution of the flux. We present a deep learning framework able to jointly reconstruct the spectra of different emission components and the SCD of point-source populations. In a proof-of-concept example, we show that our method accurately extracts even complex-shaped spectra and SCDs from simulated maps.
Stochastic Super-resolution of Cosmological Simulations with Denoising Diffusion Models
Oct 10, 2023In recent years, deep learning models have been successfully employed for augmenting low-resolution cosmological simulations with small-scale information, a task known as "super-resolution". So far, these cosmological super-resolution models have relied on generative adversarial networks (GANs), which can achieve highly realistic results, but suffer from various shortcomings (e.g. low sample diversity). We introduce denoising diffusion models as a powerful generative model for super-resolving cosmic large-scale structure predictions (as a first proof-of-concept in two dimensions). To obtain accurate results down to small scales, we develop a new "filter-boosted" training approach that redistributes the importance of different scales in the pixel-wise training objective. We demonstrate that our model not only produces convincing super-resolution images and power spectra consistent at the percent level, but is also able to reproduce the diversity of small-scale features consistent with a given low-resolution simulation. This enables uncertainty quantification for the generated small-scale features, which is critical for the usefulness of such super-resolution models as a viable surrogate model for cosmic structure formation.
Semantic Self-adaptation: Enhancing Generalization with a Single Sample
Aug 10, 2022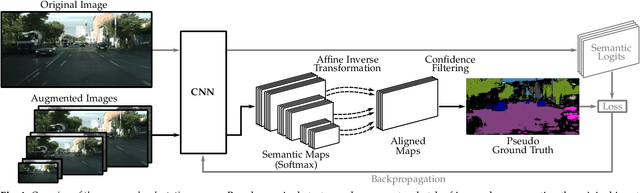


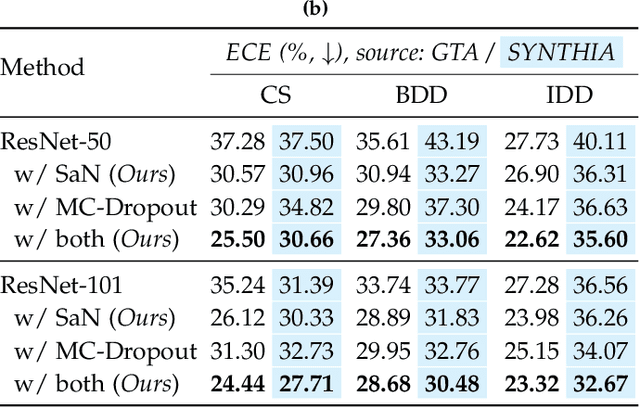
Despite years of research, out-of-domain generalization remains a critical weakness of deep networks for semantic segmentation. Previous studies relied on the assumption of a static model, i.e. once the training process is complete, model parameters remain fixed at test time. In this work, we challenge this premise with a self-adaptive approach for semantic segmentation that adjusts the inference process to each input sample. Self-adaptation operates on two levels. First, it employs a self-supervised loss that customizes the parameters of convolutional layers in the network to the input image. Second, in Batch Normalization layers, self-adaptation approximates the mean and the variance of the entire test data, which is assumed unavailable. It achieves this by interpolating between the training and the reference distribution derived from a single test sample. To empirically analyze our self-adaptive inference strategy, we develop and follow a rigorous evaluation protocol that addresses serious limitations of previous work. Our extensive analysis leads to a surprising conclusion: Using a standard training procedure, self-adaptation significantly outperforms strong baselines and sets new state-of-the-art accuracy on multi-domain benchmarks. Our study suggests that self-adaptive inference may complement the established practice of model regularization at training time for improving deep network generalization to out-of-domain data.