 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCuria-2: Scaling Self-Supervised Learning for Radiology Foundation Models
Apr 02, 2026The rapid growth of medical imaging has fueled the development of Foundation Models (FMs) to reduce the growing, unsustainable workload on radiologists. While recent FMs have shown the power of large-scale pre-training to CT and MRI analysis, there remains significant room to optimize how these models learn from complex radiological volumes. Building upon the Curia framework, this work introduces Curia-2, which significantly improves the original pre-training strategy and representation quality to better capture the specificities of radiological data. The proposed methodology enables scaling the architecture up to billion-parameter Vision Transformers, marking a first for multi-modal CT and MRI FMs. Furthermore, we formalize the evaluation of these models by extending and restructuring CuriaBench into two distinct tracks: a 2D track tailored for slice-based vision models and a 3D track for volumetric benchmarking. Our results demonstrate that Curia-2 outperforms all FMs on vision-focused tasks and fairs competitively to vision-language models on clinically complex tasks such as finding detection. Weights will be made publicly available to foster further research.
RadImageNet-VQA: A Large-Scale CT and MRI Dataset for Radiologic Visual Question Answering
Dec 19, 2025



In this work, we introduce RadImageNet-VQA, a large-scale dataset designed to advance radiologic visual question answering (VQA) on CT and MRI exams. Existing medical VQA datasets are limited in scale, dominated by X-ray imaging or biomedical illustrations, and often prone to text-based shortcuts. RadImageNet-VQA is built from expert-curated annotations and provides 750K images paired with 7.5M question-answer samples. It covers three key tasks - abnormality detection, anatomy recognition, and pathology identification - spanning eight anatomical regions and 97 pathology categories, and supports open-ended, closed-ended, and multiple-choice questions. Extensive experiments show that state-of-the-art vision-language models still struggle with fine-grained pathology identification, particularly in open-ended settings and even after fine-tuning. Text-only analysis further reveals that model performance collapses to near-random without image inputs, confirming that RadImageNet-VQA is free from linguistic shortcuts. The full dataset and benchmark are publicly available at https://huggingface.co/datasets/raidium/RadImageNet-VQA.
Boosting Omnidirectional Stereo Matching with a Pre-trained Depth Foundation Model
Mar 30, 2025Omnidirectional depth perception is essential for mobile robotics applications that require scene understanding across a full 360{\deg} field of view. Camera-based setups offer a cost-effective option by using stereo depth estimation to generate dense, high-resolution depth maps without relying on expensive active sensing. However, existing omnidirectional stereo matching approaches achieve only limited depth accuracy across diverse environments, depth ranges, and lighting conditions, due to the scarcity of real-world data. We present DFI-OmniStereo, a novel omnidirectional stereo matching method that leverages a large-scale pre-trained foundation model for relative monocular depth estimation within an iterative optimization-based stereo matching architecture. We introduce a dedicated two-stage training strategy to utilize the relative monocular depth features for our omnidirectional stereo matching before scale-invariant fine-tuning. DFI-OmniStereo achieves state-of-the-art results on the real-world Helvipad dataset, reducing disparity MAE by approximately 16% compared to the previous best omnidirectional stereo method.
DRIVINGVQA: Analyzing Visual Chain-of-Thought Reasoning of Vision Language Models in Real-World Scenarios with Driving Theory Tests
Jan 08, 2025



Large vision-language models (LVLMs) augment language models with visual understanding, enabling multimodal reasoning. However, due to the modality gap between textual and visual data, they often face significant challenges, such as over-reliance on text priors, hallucinations, and limited capacity for complex visual reasoning. Existing benchmarks to evaluate visual reasoning in LVLMs often rely on schematic or synthetic images and on imprecise machine-generated explanations. To bridge the modality gap, we present DrivingVQA, a new benchmark derived from driving theory tests to evaluate visual chain-of-thought reasoning in complex real-world scenarios. It offers 3,931 expert-crafted multiple-choice problems and interleaved explanations grounded with entities relevant to the reasoning process. We leverage this dataset to perform an extensive study of LVLMs' ability to reason about complex visual scenarios. Our experiments reveal that open-source and proprietary LVLMs struggle with visual chain-of-thought reasoning under zero-shot settings. We investigate training strategies that leverage relevant entities to improve visual reasoning. Notably, we observe a performance boost of up to 7\% when reasoning over image tokens of cropped regions tied to these entities.
Helvipad: A Real-World Dataset for Omnidirectional Stereo Depth Estimation
Nov 27, 2024



Despite considerable progress in stereo depth estimation, omnidirectional imaging remains underexplored, mainly due to the lack of appropriate data. We introduce Helvipad, a real-world dataset for omnidirectional stereo depth estimation, consisting of 40K frames from video sequences across diverse environments, including crowded indoor and outdoor scenes with diverse lighting conditions. Collected using two 360{\deg} cameras in a top-bottom setup and a LiDAR sensor, the dataset includes accurate depth and disparity labels by projecting 3D point clouds onto equirectangular images. Additionally, we provide an augmented training set with a significantly increased label density by using depth completion. We benchmark leading stereo depth estimation models for both standard and omnidirectional images. The results show that while recent stereo methods perform decently, a significant challenge persists in accurately estimating depth in omnidirectional imaging. To address this, we introduce necessary adaptations to stereo models, achieving improved performance.
Robust Deep Learning for Autonomous Driving
Nov 14, 2022



The last decade's research in artificial intelligence had a significant impact on the advance of autonomous driving. Yet, safety remains a major concern when it comes to deploying such systems in high-risk environments. The objective of this thesis is to develop methodological tools which provide reliable uncertainty estimates for deep neural networks. First, we introduce a new criterion to reliably estimate model confidence: the true class probability (TCP). We show that TCP offers better properties for failure prediction than current uncertainty measures. Since the true class is by essence unknown at test time, we propose to learn TCP criterion from data with an auxiliary model, introducing a specific learning scheme adapted to this context. The relevance of the proposed approach is validated on image classification and semantic segmentation datasets. Then, we extend our learned confidence approach to the task of domain adaptation where it improves the selection of pseudo-labels in self-training methods. Finally, we tackle the challenge of jointly detecting misclassification and out-of-distributions samples by introducing a new uncertainty measure based on evidential models and defined on the simplex.
Take One Gram of Neural Features, Get Enhanced Group Robustness
Aug 26, 2022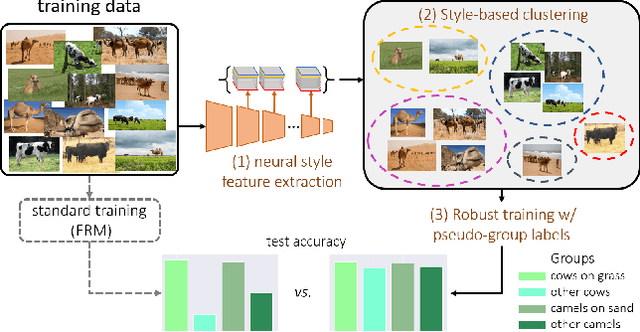
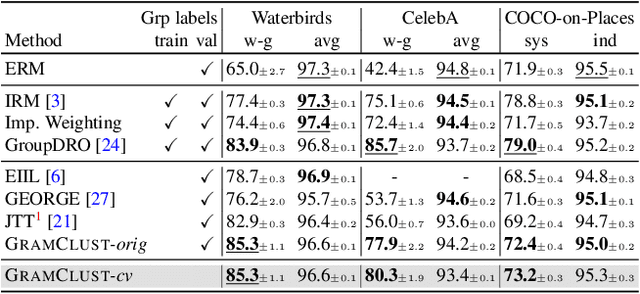
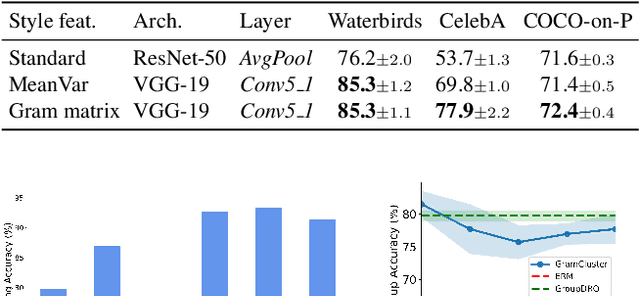

Predictive performance of machine learning models trained with empirical risk minimization (ERM) can degrade considerably under distribution shifts. The presence of spurious correlations in training datasets leads ERM-trained models to display high loss when evaluated on minority groups not presenting such correlations. Extensive attempts have been made to develop methods improving worst-group robustness. However, they require group information for each training input or at least, a validation set with group labels to tune their hyperparameters, which may be expensive to get or unknown a priori. In this paper, we address the challenge of improving group robustness without group annotation during training or validation. To this end, we propose to partition the training dataset into groups based on Gram matrices of features extracted by an ``identification'' model and to apply robust optimization based on these pseudo-groups. In the realistic context where no group labels are available, our experiments show that our approach not only improves group robustness over ERM but also outperforms all recent baselines
Confidence Estimation via Auxiliary Models
Dec 11, 2020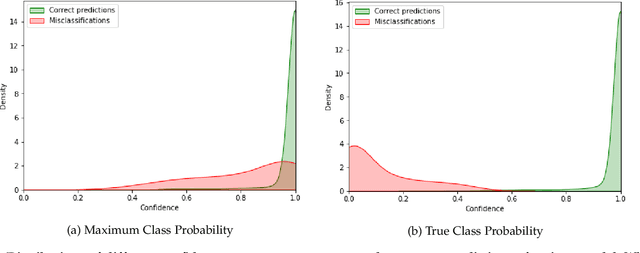
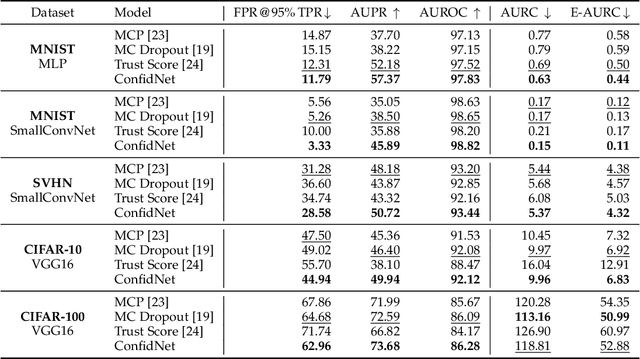
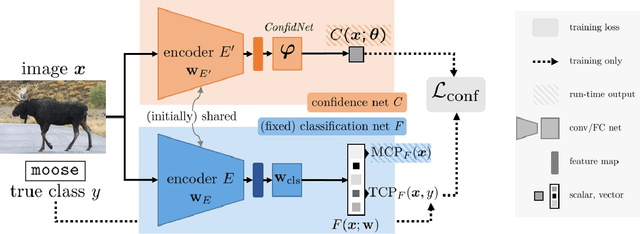

Reliably quantifying the confidence of deep neural classifiers is a challenging yet fundamental requirement for deploying such models in safety-critical applications. In this paper, we introduce a novel target criterion for model confidence, namely the true class probability (TCP). We show that TCP offers better properties for confidence estimation than standard maximum class probability (MCP). Since the true class is by essence unknown at test time, we propose to learn TCP criterion from data with an auxiliary model, introducing a specific learning scheme adapted to this context. We evaluate our approach on the task of failure prediction and of self-training with pseudo-labels for domain adaptation, which both necessitate effective confidence estimates. Extensive experiments are conducted for validating the relevance of the proposed approach in each task. We study various network architectures and experiment with small and large datasets for image classification and semantic segmentation. In every tested benchmark, our approach outperforms strong baselines.
Addressing Failure Prediction by Learning Model Confidence
Oct 26, 2019
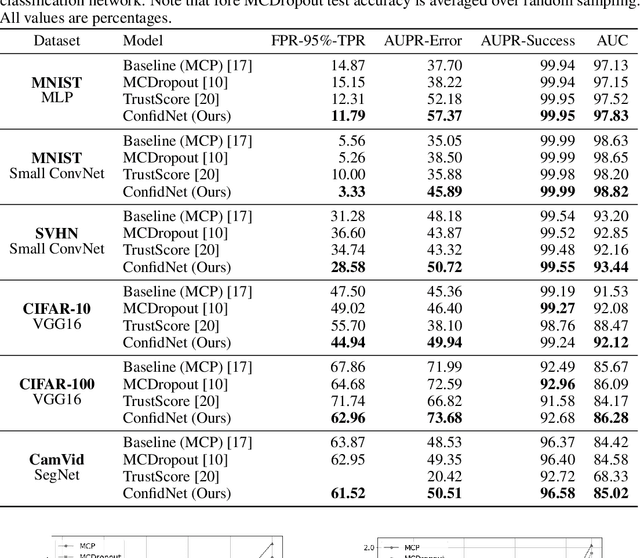
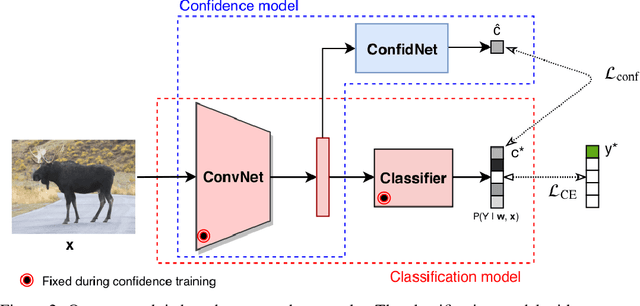
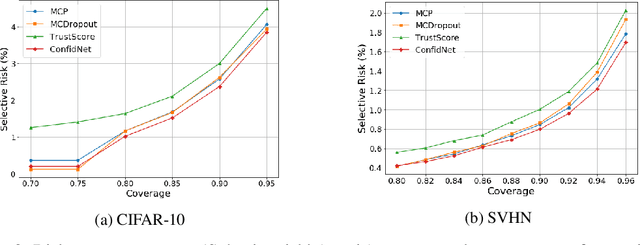
Assessing reliably the confidence of a deep neural network and predicting its failures is of primary importance for the practical deployment of these models. In this paper, we propose a new target criterion for model confidence, corresponding to the True Class Probability (TCP). We show how using the TCP is more suited than relying on the classic Maximum Class Probability (MCP). We provide in addition theoretical guarantees for TCP in the context of failure prediction. Since the true class is by essence unknown at test time, we propose to learn TCP criterion on the training set, introducing a specific learning scheme adapted to this context. Extensive experiments are conducted for validating the relevance of the proposed approach. We study various network architectures, small and large scale datasets for image classification and semantic segmentation. We show that our approach consistently outperforms several strong methods, from MCP to Bayesian uncertainty, as well as recent approaches specifically designed for failure prediction.
Leveraging Weakly Annotated Data for Fashion Image Retrieval and Label Prediction
Sep 27, 2017

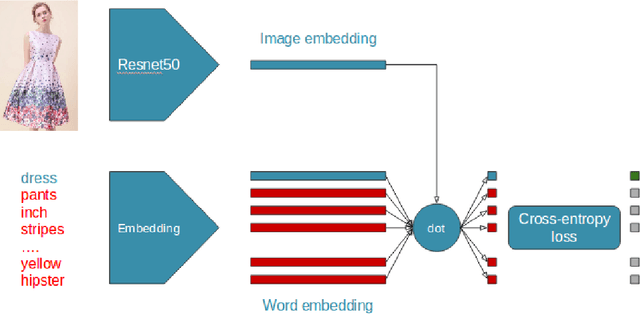

In this paper, we present a method to learn a visual representation adapted for e-commerce products. Based on weakly supervised learning, our model learns from noisy datasets crawled on e-commerce website catalogs and does not require any manual labeling. We show that our representation can be used for downward classification tasks over clothing categories with different levels of granularity. We also demonstrate that the learnt representation is suitable for image retrieval. We achieve nearly state-of-art results on the DeepFashion In-Shop Clothes Retrieval and Categories Attributes Prediction tasks, without using the provided training set.