 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
On Teacher Hacking in Language Model Distillation
Feb 04, 2025



Post-training of language models (LMs) increasingly relies on the following two stages: (i) knowledge distillation, where the LM is trained to imitate a larger teacher LM, and (ii) reinforcement learning from human feedback (RLHF), where the LM is aligned by optimizing a reward model. In the second RLHF stage, a well-known challenge is reward hacking, where the LM over-optimizes the reward model. Such phenomenon is in line with Goodhart's law and can lead to degraded performance on the true objective. In this paper, we investigate whether a similar phenomenon, that we call teacher hacking, can occur during knowledge distillation. This could arise because the teacher LM is itself an imperfect approximation of the true distribution. To study this, we propose a controlled experimental setup involving: (i) an oracle LM representing the ground-truth distribution, (ii) a teacher LM distilled from the oracle, and (iii) a student LM distilled from the teacher. Our experiments reveal the following insights. When using a fixed offline dataset for distillation, teacher hacking occurs; moreover, we can detect it by observing when the optimization process deviates from polynomial convergence laws. In contrast, employing online data generation techniques effectively mitigates teacher hacking. More precisely, we identify data diversity as the key factor in preventing hacking. Overall, our findings provide a deeper understanding of the benefits and limitations of distillation for building robust and efficient LMs.
Streaming DiLoCo with overlapping communication: Towards a Distributed Free Lunch
Jan 30, 2025Training of large language models (LLMs) is typically distributed across a large number of accelerators to reduce training time. Since internal states and parameter gradients need to be exchanged at each and every single gradient step, all devices need to be co-located using low-latency high-bandwidth communication links to support the required high volume of exchanged bits. Recently, distributed algorithms like DiLoCo have relaxed such co-location constraint: accelerators can be grouped into ``workers'', where synchronizations between workers only occur infrequently. This in turn means that workers can afford being connected by lower bandwidth communication links without affecting learning quality. However, in these methods, communication across workers still requires the same peak bandwidth as before, as the synchronizations require all parameters to be exchanged across all workers. In this paper, we improve DiLoCo in three ways. First, we synchronize only subsets of parameters in sequence, rather than all at once, which greatly reduces peak bandwidth. Second, we allow workers to continue training while synchronizing, which decreases wall clock time. Third, we quantize the data exchanged by workers, which further reduces bandwidth across workers. By properly combining these modifications, we show experimentally that we can distribute training of billion-scale parameters and reach similar quality as before, but reducing required bandwidth by two orders of magnitude.
Diversity-Rewarded CFG Distillation
Oct 08, 2024Generative models are transforming creative domains such as music generation, with inference-time strategies like Classifier-Free Guidance (CFG) playing a crucial role. However, CFG doubles inference cost while limiting originality and diversity across generated contents. In this paper, we introduce diversity-rewarded CFG distillation, a novel finetuning procedure that distills the strengths of CFG while addressing its limitations. Our approach optimises two training objectives: (1) a distillation objective, encouraging the model alone (without CFG) to imitate the CFG-augmented predictions, and (2) an RL objective with a diversity reward, promoting the generation of diverse outputs for a given prompt. By finetuning, we learn model weights with the ability to generate high-quality and diverse outputs, without any inference overhead. This also unlocks the potential of weight-based model merging strategies: by interpolating between the weights of two models (the first focusing on quality, the second on diversity), we can control the quality-diversity trade-off at deployment time, and even further boost performance. We conduct extensive experiments on the MusicLM (Agostinelli et al., 2023) text-to-music generative model, where our approach surpasses CFG in terms of quality-diversity Pareto optimality. According to human evaluators, our finetuned-then-merged model generates samples with higher quality-diversity than the base model augmented with CFG. Explore our generations at https://google-research.github.io/seanet/musiclm/diverse_music/.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Conditioned Language Policy: A General Framework for Steerable Multi-Objective Finetuning
Jul 22, 2024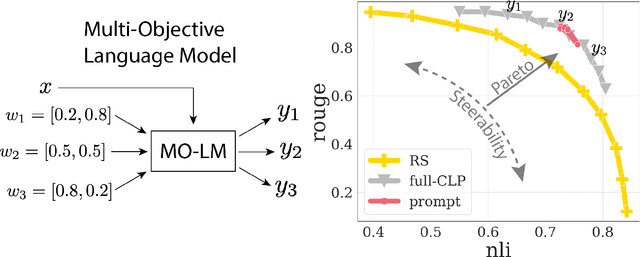
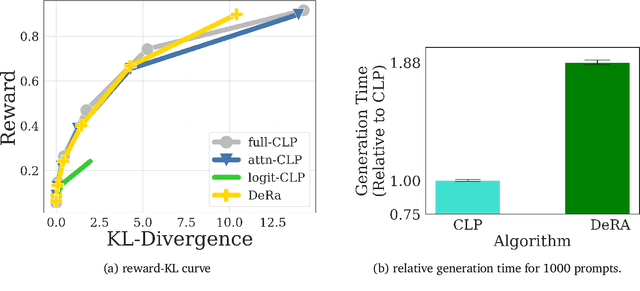
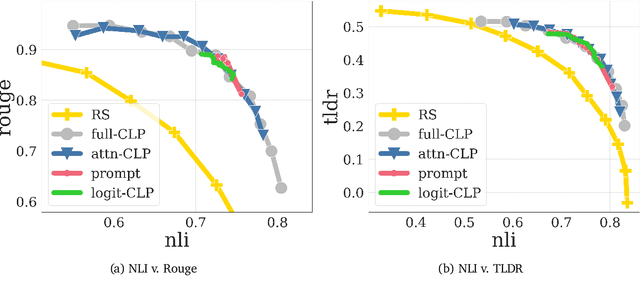
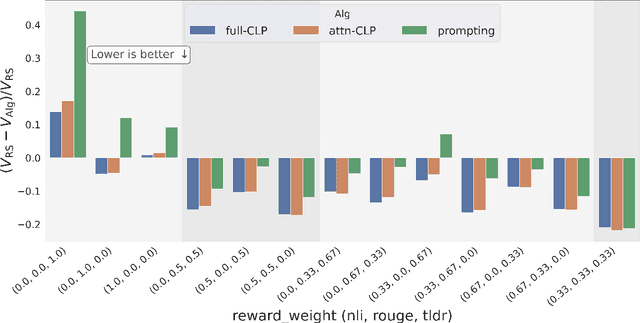
Reward-based finetuning is crucial for aligning language policies with intended behaviors (e.g., creativity and safety). A key challenge here is to develop steerable language models that trade-off multiple (conflicting) objectives in a flexible and efficient manner. This paper presents Conditioned Language Policy (CLP), a general framework for finetuning language models on multiple objectives. Building on techniques from multi-task training and parameter-efficient finetuning, CLP can learn steerable models that effectively trade-off conflicting objectives at inference time. Notably, this does not require training or maintaining multiple models to achieve different trade-offs between the objectives. Through an extensive set of experiments and ablations, we show that the CLP framework learns steerable models that outperform and Pareto-dominate the current state-of-the-art approaches for multi-objective finetuning.
BOND: Aligning LLMs with Best-of-N Distillation
Jul 19, 2024


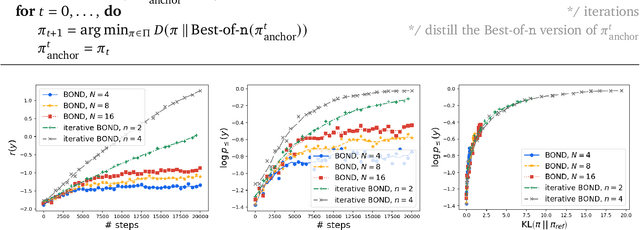
Reinforcement learning from human feedback (RLHF) is a key driver of quality and safety in state-of-the-art large language models. Yet, a surprisingly simple and strong inference-time strategy is Best-of-N sampling that selects the best generation among N candidates. In this paper, we propose Best-of-N Distillation (BOND), a novel RLHF algorithm that seeks to emulate Best-of-N but without its significant computational overhead at inference time. Specifically, BOND is a distribution matching algorithm that forces the distribution of generations from the policy to get closer to the Best-of-N distribution. We use the Jeffreys divergence (a linear combination of forward and backward KL) to balance between mode-covering and mode-seeking behavior, and derive an iterative formulation that utilizes a moving anchor for efficiency. We demonstrate the effectiveness of our approach and several design choices through experiments on abstractive summarization and Gemma models. Aligning Gemma policies with BOND outperforms other RLHF algorithms by improving results on several benchmarks.
WARP: On the Benefits of Weight Averaged Rewarded Policies
Jun 24, 2024



Reinforcement learning from human feedback (RLHF) aligns large language models (LLMs) by encouraging their generations to have high rewards, using a reward model trained on human preferences. To prevent the forgetting of pre-trained knowledge, RLHF usually incorporates a KL regularization; this forces the policy to remain close to its supervised fine-tuned initialization, though it hinders the reward optimization. To tackle the trade-off between KL and reward, in this paper we introduce a novel alignment strategy named Weight Averaged Rewarded Policies (WARP). WARP merges policies in the weight space at three distinct stages. First, it uses the exponential moving average of the policy as a dynamic anchor in the KL regularization. Second, it applies spherical interpolation to merge independently fine-tuned policies into a new enhanced one. Third, it linearly interpolates between this merged model and the initialization, to recover features from pre-training. This procedure is then applied iteratively, with each iteration's final model used as an advanced initialization for the next, progressively refining the KL-reward Pareto front, achieving superior rewards at fixed KL. Experiments with GEMMA policies validate that WARP improves their quality and alignment, outperforming other open-source LLMs.
WARM: On the Benefits of Weight Averaged Reward Models
Jan 22, 2024Aligning large language models (LLMs) with human preferences through reinforcement learning (RLHF) can lead to reward hacking, where LLMs exploit failures in the reward model (RM) to achieve seemingly high rewards without meeting the underlying objectives. We identify two primary challenges when designing RMs to mitigate reward hacking: distribution shifts during the RL process and inconsistencies in human preferences. As a solution, we propose Weight Averaged Reward Models (WARM), first fine-tuning multiple RMs, then averaging them in the weight space. This strategy follows the observation that fine-tuned weights remain linearly mode connected when sharing the same pre-training. By averaging weights, WARM improves efficiency compared to the traditional ensembling of predictions, while improving reliability under distribution shifts and robustness to preference inconsistencies. Our experiments on summarization tasks, using best-of-N and RL methods, shows that WARM improves the overall quality and alignment of LLM predictions; for example, a policy RL fine-tuned with WARM has a 79.4% win rate against a policy RL fine-tuned with a single RM.
Recycling diverse models for out-of-distribution generalization
Dec 20, 2022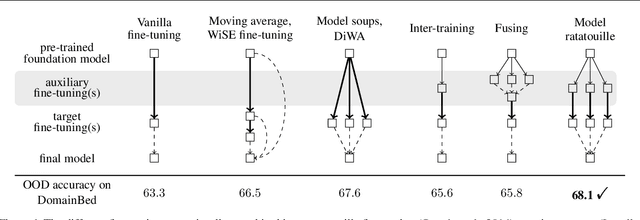

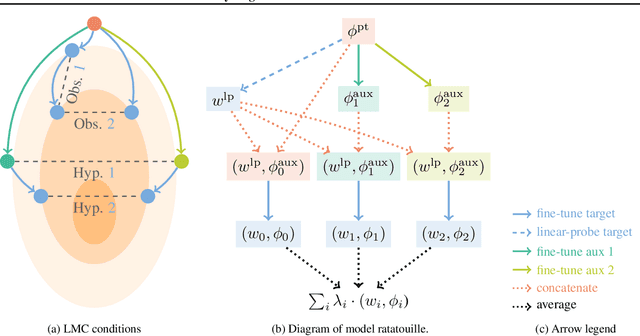

Foundation models are redefining how AI systems are built. Practitioners now follow a standard procedure to build their machine learning solutions: download a copy of a foundation model, and fine-tune it using some in-house data about the target task of interest. Consequently, the Internet is swarmed by a handful of foundation models fine-tuned on many diverse tasks. Yet, these individual fine-tunings often lack strong generalization and exist in isolation without benefiting from each other. In our opinion, this is a missed opportunity, as these specialized models contain diverse features. Based on this insight, we propose model recycling, a simple strategy that leverages multiple fine-tunings of the same foundation model on diverse auxiliary tasks, and repurposes them as rich and diverse initializations for the target task. Specifically, model recycling fine-tunes in parallel each specialized model on the target task, and then averages the weights of all target fine-tunings into a final model. Empirically, we show that model recycling maximizes model diversity by benefiting from diverse auxiliary tasks, and achieves a new state of the art on the reference DomainBed benchmark for out-of-distribution generalization. Looking forward, model recycling is a contribution to the emerging paradigm of updatable machine learning where, akin to open-source software development, the community collaborates to incrementally and reliably update machine learning models.