 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
BOND: Aligning LLMs with Best-of-N Distillation
Jul 19, 2024


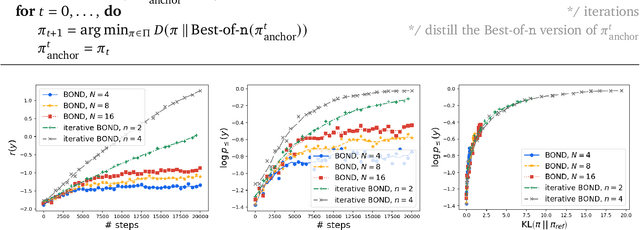
Reinforcement learning from human feedback (RLHF) is a key driver of quality and safety in state-of-the-art large language models. Yet, a surprisingly simple and strong inference-time strategy is Best-of-N sampling that selects the best generation among N candidates. In this paper, we propose Best-of-N Distillation (BOND), a novel RLHF algorithm that seeks to emulate Best-of-N but without its significant computational overhead at inference time. Specifically, BOND is a distribution matching algorithm that forces the distribution of generations from the policy to get closer to the Best-of-N distribution. We use the Jeffreys divergence (a linear combination of forward and backward KL) to balance between mode-covering and mode-seeking behavior, and derive an iterative formulation that utilizes a moving anchor for efficiency. We demonstrate the effectiveness of our approach and several design choices through experiments on abstractive summarization and Gemma models. Aligning Gemma policies with BOND outperforms other RLHF algorithms by improving results on several benchmarks.
Revisiting Gaussian mixture critics in off-policy reinforcement learning: a sample-based approach
Apr 22, 2022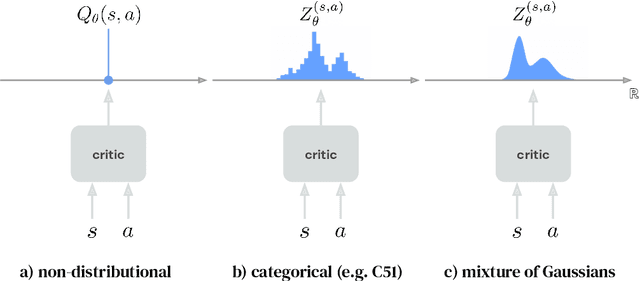
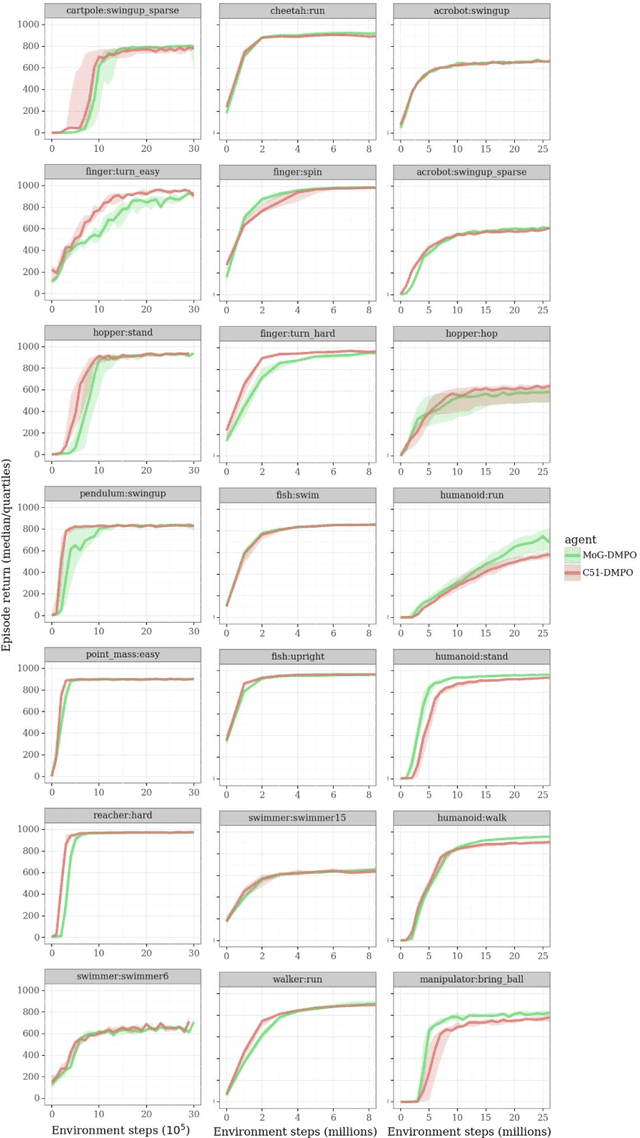
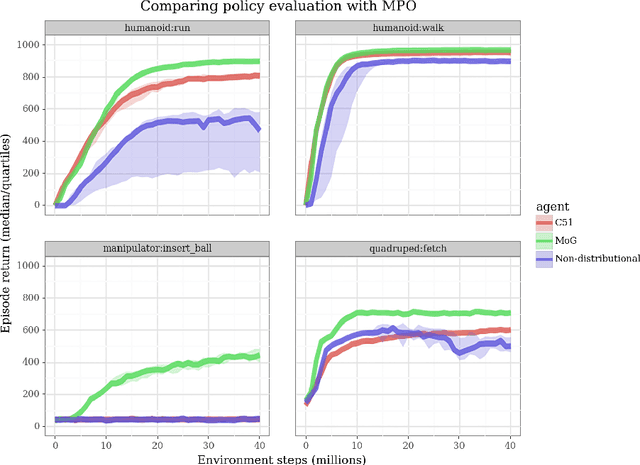
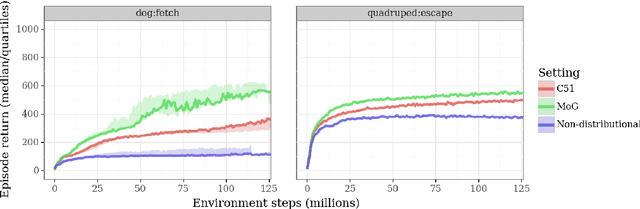
Actor-critic algorithms that make use of distributional policy evaluation have frequently been shown to outperform their non-distributional counterparts on many challenging control tasks. Examples of this behavior include the D4PG and DMPO algorithms as compared to DDPG and MPO, respectively [Barth-Maron et al., 2018; Hoffman et al., 2020]. However, both agents rely on the C51 critic for value estimation.One major drawback of the C51 approach is its requirement of prior knowledge about the minimum andmaximum values a policy can attain as well as the number of bins used, which fixes the resolution ofthe distributional estimate. While the DeepMind control suite of tasks utilizes standardized rewards and episode lengths, thus enabling the entire suite to be solved with a single setting of these hyperparameters, this is often not the case. This paper revisits a natural alternative that removes this requirement, namelya mixture of Gaussians, and a simple sample-based loss function to train it in an off-policy regime. We empirically evaluate its performance on a broad range of continuous control tasks and demonstrate that it eliminates the need for these distributional hyperparameters and achieves state-of-the-art performance on a variety of challenging tasks (e.g. the humanoid, dog, quadruped, and manipulator domains). Finallywe provide an implementation in the Acme agent repository.