 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Optimistic Games for Combinatorial Bayesian Optimization with Application to Protein Design
Sep 27, 2024Bayesian optimization (BO) is a powerful framework to optimize black-box expensive-to-evaluate functions via sequential interactions. In several important problems (e.g. drug discovery, circuit design, neural architecture search, etc.), though, such functions are defined over large $\textit{combinatorial and unstructured}$ spaces. This makes existing BO algorithms not feasible due to the intractable maximization of the acquisition function over these domains. To address this issue, we propose $\textbf{GameOpt}$, a novel game-theoretical approach to combinatorial BO. $\textbf{GameOpt}$ establishes a cooperative game between the different optimization variables, and selects points that are game $\textit{equilibria}$ of an upper confidence bound acquisition function. These are stable configurations from which no variable has an incentive to deviate$-$ analog to local optima in continuous domains. Crucially, this allows us to efficiently break down the complexity of the combinatorial domain into individual decision sets, making $\textbf{GameOpt}$ scalable to large combinatorial spaces. We demonstrate the application of $\textbf{GameOpt}$ to the challenging $\textit{protein design}$ problem and validate its performance on four real-world protein datasets. Each protein can take up to $20^{X}$ possible configurations, where $X$ is the length of a protein, making standard BO methods infeasible. Instead, our approach iteratively selects informative protein configurations and very quickly discovers highly active protein variants compared to other baselines.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
BOND: Aligning LLMs with Best-of-N Distillation
Jul 19, 2024


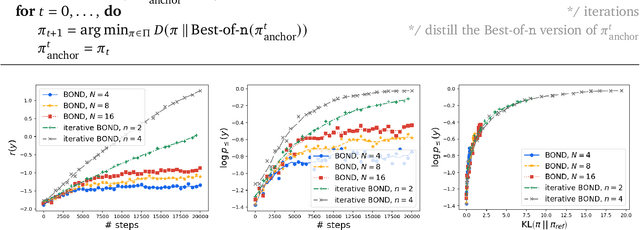
Reinforcement learning from human feedback (RLHF) is a key driver of quality and safety in state-of-the-art large language models. Yet, a surprisingly simple and strong inference-time strategy is Best-of-N sampling that selects the best generation among N candidates. In this paper, we propose Best-of-N Distillation (BOND), a novel RLHF algorithm that seeks to emulate Best-of-N but without its significant computational overhead at inference time. Specifically, BOND is a distribution matching algorithm that forces the distribution of generations from the policy to get closer to the Best-of-N distribution. We use the Jeffreys divergence (a linear combination of forward and backward KL) to balance between mode-covering and mode-seeking behavior, and derive an iterative formulation that utilizes a moving anchor for efficiency. We demonstrate the effectiveness of our approach and several design choices through experiments on abstractive summarization and Gemma models. Aligning Gemma policies with BOND outperforms other RLHF algorithms by improving results on several benchmarks.
WARP: On the Benefits of Weight Averaged Rewarded Policies
Jun 24, 2024



Reinforcement learning from human feedback (RLHF) aligns large language models (LLMs) by encouraging their generations to have high rewards, using a reward model trained on human preferences. To prevent the forgetting of pre-trained knowledge, RLHF usually incorporates a KL regularization; this forces the policy to remain close to its supervised fine-tuned initialization, though it hinders the reward optimization. To tackle the trade-off between KL and reward, in this paper we introduce a novel alignment strategy named Weight Averaged Rewarded Policies (WARP). WARP merges policies in the weight space at three distinct stages. First, it uses the exponential moving average of the policy as a dynamic anchor in the KL regularization. Second, it applies spherical interpolation to merge independently fine-tuned policies into a new enhanced one. Third, it linearly interpolates between this merged model and the initialization, to recover features from pre-training. This procedure is then applied iteratively, with each iteration's final model used as an advanced initialization for the next, progressively refining the KL-reward Pareto front, achieving superior rewards at fixed KL. Experiments with GEMMA policies validate that WARP improves their quality and alignment, outperforming other open-source LLMs.
Group Robust Preference Optimization in Reward-free RLHF
May 30, 2024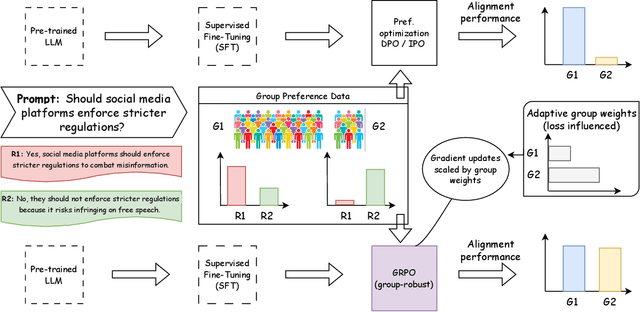
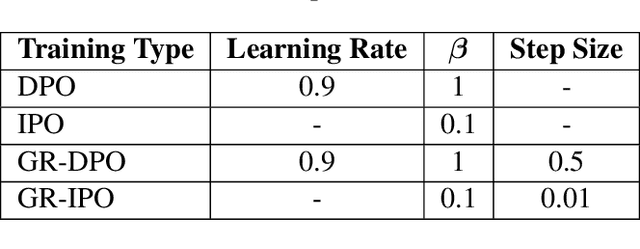
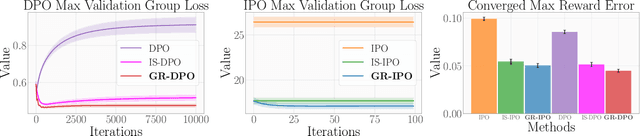

Adapting large language models (LLMs) for specific tasks usually involves fine-tuning through reinforcement learning with human feedback (RLHF) on preference data. While these data often come from diverse labelers' groups (e.g., different demographics, ethnicities, company teams, etc.), traditional RLHF approaches adopt a "one-size-fits-all" approach, i.e., they indiscriminately assume and optimize a single preference model, thus not being robust to unique characteristics and needs of the various groups. To address this limitation, we propose a novel Group Robust Preference Optimization (GRPO) method to align LLMs to individual groups' preferences robustly. Our approach builds upon reward-free direct preference optimization methods, but unlike previous approaches, it seeks a robust policy which maximizes the worst-case group performance. To achieve this, GRPO adaptively and sequentially weights the importance of different groups, prioritizing groups with worse cumulative loss. We theoretically study the feasibility of GRPO and analyze its convergence for the log-linear policy class. By fine-tuning LLMs with GRPO using diverse group-based global opinion data, we significantly improved performance for the worst-performing groups, reduced loss imbalances across groups, and improved probability accuracies compared to non-robust baselines.
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
Apr 11, 2024



We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
DockGame: Cooperative Games for Multimeric Rigid Protein Docking
Oct 09, 2023Protein interactions and assembly formation are fundamental to most biological processes. Predicting the assembly structure from constituent proteins -- referred to as the protein docking task -- is thus a crucial step in protein design applications. Most traditional and deep learning methods for docking have focused mainly on binary docking, following either a search-based, regression-based, or generative modeling paradigm. In this paper, we focus on the less-studied multimeric (i.e., two or more proteins) docking problem. We introduce DockGame, a novel game-theoretic framework for docking -- we view protein docking as a cooperative game between proteins, where the final assembly structure(s) constitute stable equilibria w.r.t. the underlying game potential. Since we do not have access to the true potential, we consider two approaches - i) learning a surrogate game potential guided by physics-based energy functions and computing equilibria by simultaneous gradient updates, and ii) sampling from the Gibbs distribution of the true potential by learning a diffusion generative model over the action spaces (rotations and translations) of all proteins. Empirically, on the Docking Benchmark 5.5 (DB5.5) dataset, DockGame has much faster runtimes than traditional docking methods, can generate multiple plausible assembly structures, and achieves comparable performance to existing binary docking baselines, despite solving the harder task of coordinating multiple protein chains.
Distributionally Robust Model-based Reinforcement Learning with Large State Spaces
Sep 05, 2023Three major challenges in reinforcement learning are the complex dynamical systems with large state spaces, the costly data acquisition processes, and the deviation of real-world dynamics from the training environment deployment. To overcome these issues, we study distributionally robust Markov decision processes with continuous state spaces under the widely used Kullback-Leibler, chi-square, and total variation uncertainty sets. We propose a model-based approach that utilizes Gaussian Processes and the maximum variance reduction algorithm to efficiently learn multi-output nominal transition dynamics, leveraging access to a generative model (i.e., simulator). We further demonstrate the statistical sample complexity of the proposed method for different uncertainty sets. These complexity bounds are independent of the number of states and extend beyond linear dynamics, ensuring the effectiveness of our approach in identifying near-optimal distributionally-robust policies. The proposed method can be further combined with other model-free distributionally robust reinforcement learning methods to obtain a near-optimal robust policy. Experimental results demonstrate the robustness of our algorithm to distributional shifts and its superior performance in terms of the number of samples needed.