 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
Conformal prediction under ambiguous ground truth
Jul 18, 2023



In safety-critical classification tasks, conformal prediction allows to perform rigorous uncertainty quantification by providing confidence sets including the true class with a user-specified probability. This generally assumes the availability of a held-out calibration set with access to ground truth labels. Unfortunately, in many domains, such labels are difficult to obtain and usually approximated by aggregating expert opinions. In fact, this holds true for almost all datasets, including well-known ones such as CIFAR and ImageNet. Applying conformal prediction using such labels underestimates uncertainty. Indeed, when expert opinions are not resolvable, there is inherent ambiguity present in the labels. That is, we do not have ``crisp'', definitive ground truth labels and this uncertainty should be taken into account during calibration. In this paper, we develop a conformal prediction framework for such ambiguous ground truth settings which relies on an approximation of the underlying posterior distribution of labels given inputs. We demonstrate our methodology on synthetic and real datasets, including a case study of skin condition classification in dermatology.
Evaluating AI systems under uncertain ground truth: a case study in dermatology
Jul 05, 2023



For safety, AI systems in health undergo thorough evaluations before deployment, validating their predictions against a ground truth that is assumed certain. However, this is actually not the case and the ground truth may be uncertain. Unfortunately, this is largely ignored in standard evaluation of AI models but can have severe consequences such as overestimating the future performance. To avoid this, we measure the effects of ground truth uncertainty, which we assume decomposes into two main components: annotation uncertainty which stems from the lack of reliable annotations, and inherent uncertainty due to limited observational information. This ground truth uncertainty is ignored when estimating the ground truth by deterministically aggregating annotations, e.g., by majority voting or averaging. In contrast, we propose a framework where aggregation is done using a statistical model. Specifically, we frame aggregation of annotations as posterior inference of so-called plausibilities, representing distributions over classes in a classification setting, subject to a hyper-parameter encoding annotator reliability. Based on this model, we propose a metric for measuring annotation uncertainty and provide uncertainty-adjusted metrics for performance evaluation. We present a case study applying our framework to skin condition classification from images where annotations are provided in the form of differential diagnoses. The deterministic adjudication process called inverse rank normalization (IRN) from previous work ignores ground truth uncertainty in evaluation. Instead, we present two alternative statistical models: a probabilistic version of IRN and a Plackett-Luce-based model. We find that a large portion of the dataset exhibits significant ground truth uncertainty and standard IRN-based evaluation severely over-estimates performance without providing uncertainty estimates.
Perception Test: A Diagnostic Benchmark for Multimodal Video Models
May 23, 2023


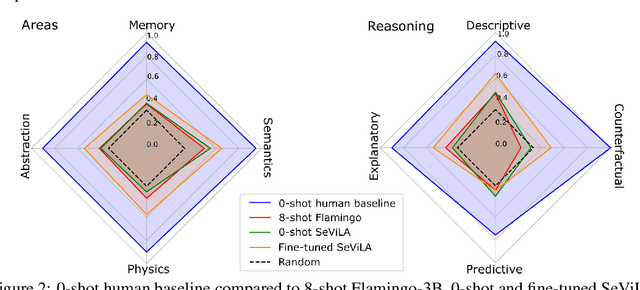
We propose a novel multimodal video benchmark - the Perception Test - to evaluate the perception and reasoning skills of pre-trained multimodal models (e.g. Flamingo, BEiT-3, or GPT-4). Compared to existing benchmarks that focus on computational tasks (e.g. classification, detection or tracking), the Perception Test focuses on skills (Memory, Abstraction, Physics, Semantics) and types of reasoning (descriptive, explanatory, predictive, counterfactual) across video, audio, and text modalities, to provide a comprehensive and efficient evaluation tool. The benchmark probes pre-trained models for their transfer capabilities, in a zero-shot / few-shot or limited finetuning regime. For these purposes, the Perception Test introduces 11.6k real-world videos, 23s average length, designed to show perceptually interesting situations, filmed by around 100 participants worldwide. The videos are densely annotated with six types of labels (multiple-choice and grounded video question-answers, object and point tracks, temporal action and sound segments), enabling both language and non-language evaluations. The fine-tuning and validation splits of the benchmark are publicly available (CC-BY license), in addition to a challenge server with a held-out test split. Human baseline results compared to state-of-the-art video QA models show a significant gap in performance (91.4% vs 43.6%), suggesting that there is significant room for improvement in multimodal video understanding. Dataset, baselines code, and challenge server are available at https://github.com/deepmind/perception_test