 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmplifying human performance in combinatorial competitive programming
Nov 29, 2024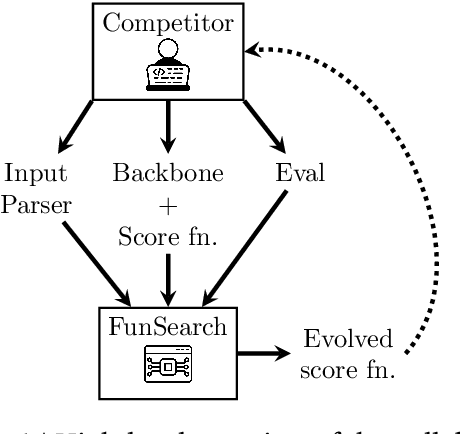

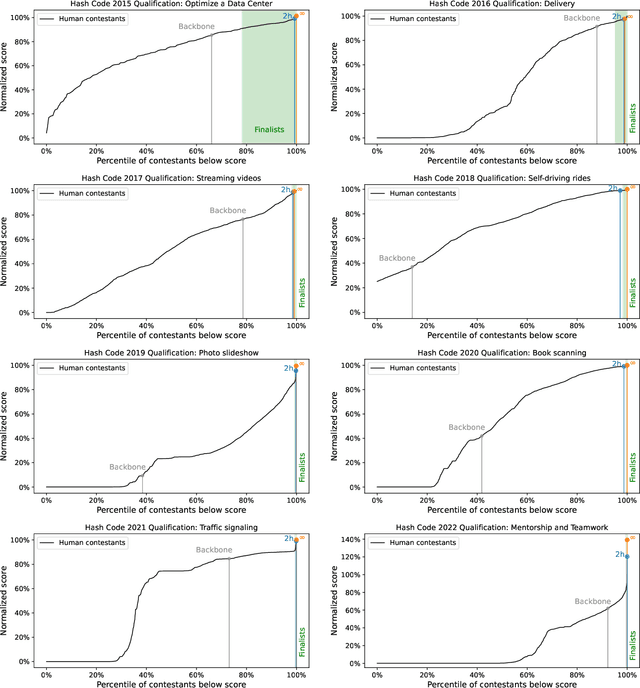
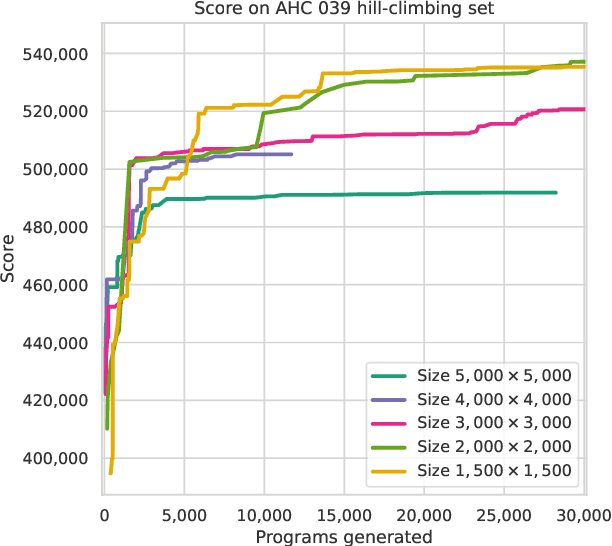
Recent years have seen a significant surge in complex AI systems for competitive programming, capable of performing at admirable levels against human competitors. While steady progress has been made, the highest percentiles still remain out of reach for these methods on standard competition platforms such as Codeforces. Here we instead focus on combinatorial competitive programming, where the target is to find as-good-as-possible solutions to otherwise computationally intractable problems, over specific given inputs. We hypothesise that this scenario offers a unique testbed for human-AI synergy, as human programmers can write a backbone of a heuristic solution, after which AI can be used to optimise the scoring function used by the heuristic. We deploy our approach on previous iterations of Hash Code, a global team programming competition inspired by NP-hard software engineering problems at Google, and we leverage FunSearch to evolve our scoring functions. Our evolved solutions significantly improve the attained scores from their baseline, successfully breaking into the top percentile on all previous Hash Code online qualification rounds, and outperforming the top human teams on several. Our method is also performant on an optimisation problem that featured in a recent held-out AtCoder contest.
Transformers meet Neural Algorithmic Reasoners
Jun 13, 2024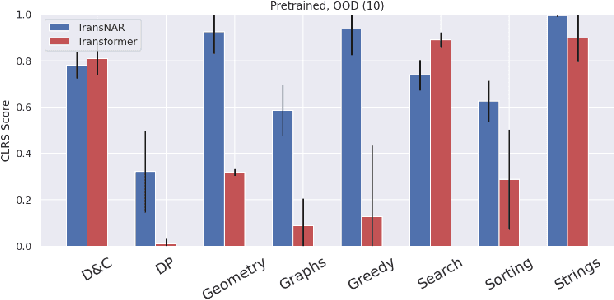
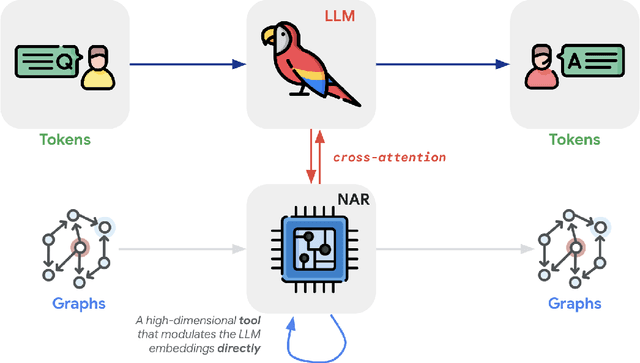
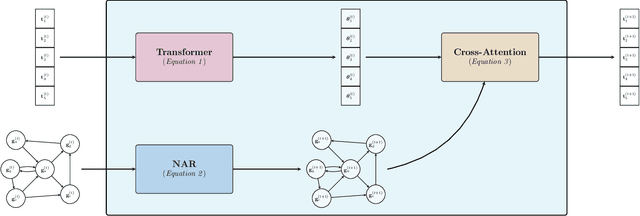
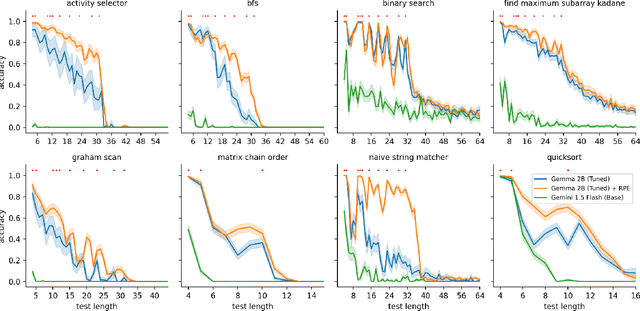
Transformers have revolutionized machine learning with their simple yet effective architecture. Pre-training Transformers on massive text datasets from the Internet has led to unmatched generalization for natural language understanding (NLU) tasks. However, such language models remain fragile when tasked with algorithmic forms of reasoning, where computations must be precise and robust. To address this limitation, we propose a novel approach that combines the Transformer's language understanding with the robustness of graph neural network (GNN)-based neural algorithmic reasoners (NARs). Such NARs proved effective as generic solvers for algorithmic tasks, when specified in graph form. To make their embeddings accessible to a Transformer, we propose a hybrid architecture with a two-phase training procedure, allowing the tokens in the language model to cross-attend to the node embeddings from the NAR. We evaluate our resulting TransNAR model on CLRS-Text, the text-based version of the CLRS-30 benchmark, and demonstrate significant gains over Transformer-only models for algorithmic reasoning, both in and out of distribution.
The CLRS-Text Algorithmic Reasoning Language Benchmark
Jun 06, 2024

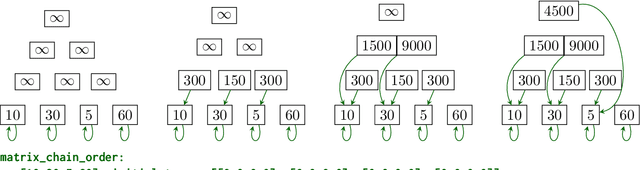
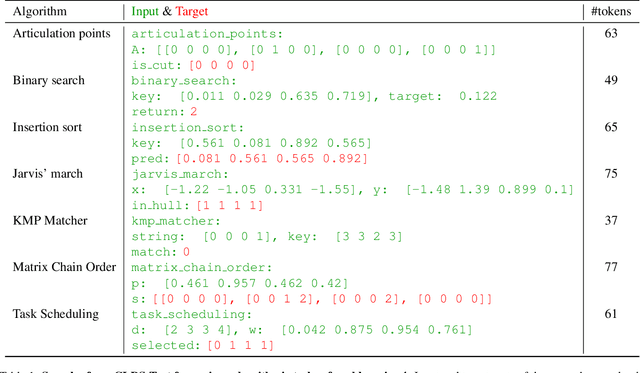
Eliciting reasoning capabilities from language models (LMs) is a critical direction on the path towards building intelligent systems. Most recent studies dedicated to reasoning focus on out-of-distribution performance on procedurally-generated synthetic benchmarks, bespoke-built to evaluate specific skills only. This trend makes results hard to transfer across publications, slowing down progress. Three years ago, a similar issue was identified and rectified in the field of neural algorithmic reasoning, with the advent of the CLRS benchmark. CLRS is a dataset generator comprising graph execution traces of classical algorithms from the Introduction to Algorithms textbook. Inspired by this, we propose CLRS-Text -- a textual version of these algorithmic traces. Out of the box, CLRS-Text is capable of procedurally generating trace data for thirty diverse, challenging algorithmic tasks across any desirable input distribution, while offering a standard pipeline in which any additional algorithmic tasks may be created in the benchmark. We fine-tune and evaluate various LMs as generalist executors on this benchmark, validating prior work and revealing a novel, interesting challenge for the LM reasoning community. Our code is available at https://github.com/google-deepmind/clrs/tree/master/clrs/_src/clrs_text.
Perception Test: A Diagnostic Benchmark for Multimodal Video Models
May 23, 2023


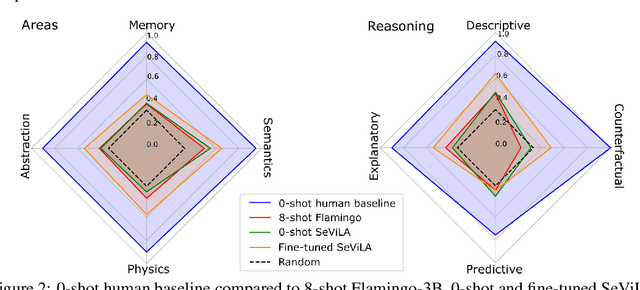
We propose a novel multimodal video benchmark - the Perception Test - to evaluate the perception and reasoning skills of pre-trained multimodal models (e.g. Flamingo, BEiT-3, or GPT-4). Compared to existing benchmarks that focus on computational tasks (e.g. classification, detection or tracking), the Perception Test focuses on skills (Memory, Abstraction, Physics, Semantics) and types of reasoning (descriptive, explanatory, predictive, counterfactual) across video, audio, and text modalities, to provide a comprehensive and efficient evaluation tool. The benchmark probes pre-trained models for their transfer capabilities, in a zero-shot / few-shot or limited finetuning regime. For these purposes, the Perception Test introduces 11.6k real-world videos, 23s average length, designed to show perceptually interesting situations, filmed by around 100 participants worldwide. The videos are densely annotated with six types of labels (multiple-choice and grounded video question-answers, object and point tracks, temporal action and sound segments), enabling both language and non-language evaluations. The fine-tuning and validation splits of the benchmark are publicly available (CC-BY license), in addition to a challenge server with a held-out test split. Human baseline results compared to state-of-the-art video QA models show a significant gap in performance (91.4% vs 43.6%), suggesting that there is significant room for improvement in multimodal video understanding. Dataset, baselines code, and challenge server are available at https://github.com/deepmind/perception_test
TT-SDF2PC: Registration of Point Cloud and Compressed SDF Directly in the Memory-Efficient Tensor Train Domain
Apr 11, 2023



This paper addresses the following research question: ``can one compress a detailed 3D representation and use it directly for point cloud registration?''. Map compression of the scene can be achieved by the tensor train (TT) decomposition of the signed distance function (SDF) representation. It regulates the amount of data reduced by the so-called TT-ranks. Using this representation we have proposed an algorithm, the TT-SDF2PC, that is capable of directly registering a PC to the compressed SDF by making use of efficient calculations of its derivatives in the TT domain, saving computations and memory. We compare TT-SDF2PC with SOTA local and global registration methods in a synthetic dataset and a real dataset and show on par performance while requiring significantly less resources.
Laser: Latent Set Representations for 3D Generative Modeling
Jan 13, 2023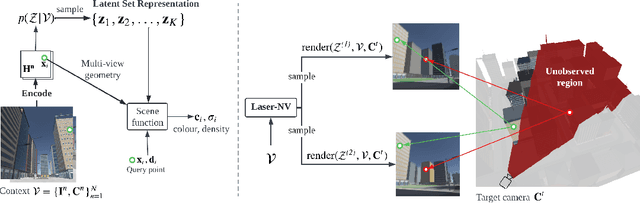
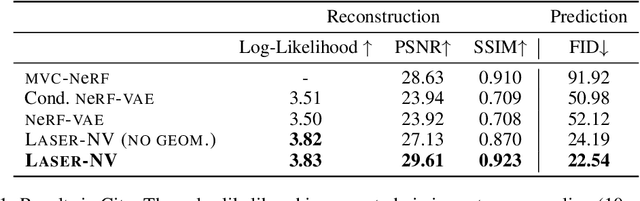


NeRF provides unparalleled fidelity of novel view synthesis: rendering a 3D scene from an arbitrary viewpoint. NeRF requires training on a large number of views that fully cover a scene, which limits its applicability. While these issues can be addressed by learning a prior over scenes in various forms, previous approaches have been either applied to overly simple scenes or struggling to render unobserved parts. We introduce Laser-NV: a generative model which achieves high modelling capacity, and which is based on a set-valued latent representation modelled by normalizing flows. Similarly to previous amortized approaches, Laser-NV learns structure from multiple scenes and is capable of fast, feed-forward inference from few views. To encourage higher rendering fidelity and consistency with observed views, Laser-NV further incorporates a geometry-informed attention mechanism over the observed views. Laser-NV further produces diverse and plausible completions of occluded parts of a scene while remaining consistent with observations. Laser-NV shows state-of-the-art novel-view synthesis quality when evaluated on ShapeNet and on a novel simulated City dataset, which features high uncertainty in the unobserved regions of the scene.
TAP-Vid: A Benchmark for Tracking Any Point in a Video
Nov 07, 2022Generic motion understanding from video involves not only tracking objects, but also perceiving how their surfaces deform and move. This information is useful to make inferences about 3D shape, physical properties and object interactions. While the problem of tracking arbitrary physical points on surfaces over longer video clips has received some attention, no dataset or benchmark for evaluation existed, until now. In this paper, we first formalize the problem, naming it tracking any point (TAP). We introduce a companion benchmark, TAP-Vid, which is composed of both real-world videos with accurate human annotations of point tracks, and synthetic videos with perfect ground-truth point tracks. Central to the construction of our benchmark is a novel semi-automatic crowdsourced pipeline which uses optical flow estimates to compensate for easier, short-term motion like camera shake, allowing annotators to focus on harder sections of video. We validate our pipeline on synthetic data and propose a simple end-to-end point tracking model TAP-Net, showing that it outperforms all prior methods on our benchmark when trained on synthetic data.
A Generalized Lottery Ticket Hypothesis
Jul 26, 2021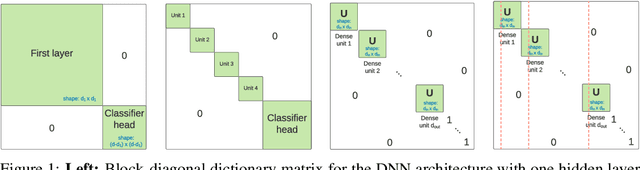
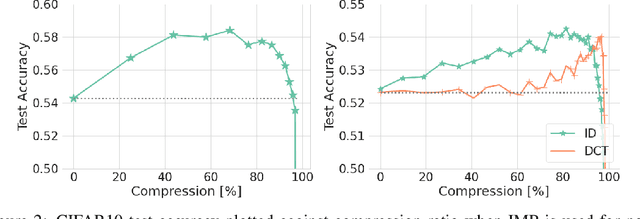


We introduce a generalization to the lottery ticket hypothesis in which the notion of "sparsity" is relaxed by choosing an arbitrary basis in the space of parameters. We present evidence that the original results reported for the canonical basis continue to hold in this broader setting. We describe how structured pruning methods, including pruning units or factorizing fully-connected layers into products of low-rank matrices, can be cast as particular instances of this "generalized" lottery ticket hypothesis. The investigations reported here are preliminary and are provided to encourage further research along this direction.
Knowledge distillation: A good teacher is patient and consistent
Jun 09, 2021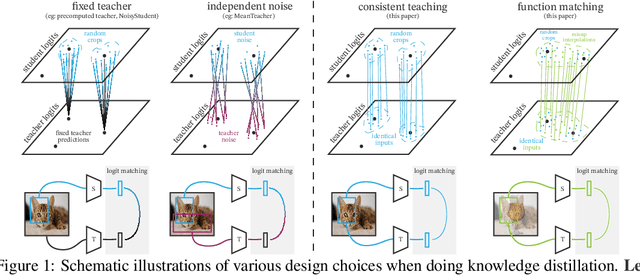
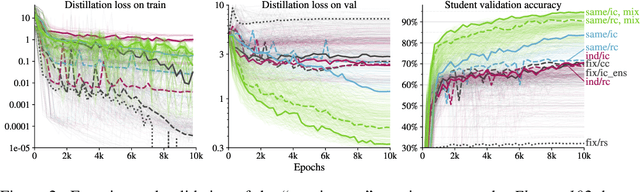

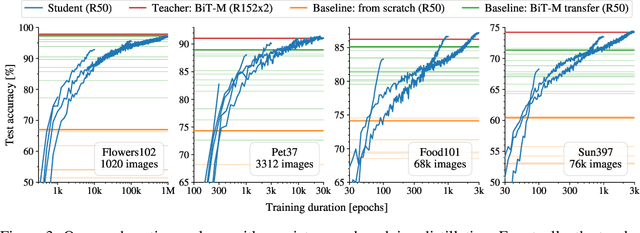
There is a growing discrepancy in computer vision between large-scale models that achieve state-of-the-art performance and models that are affordable in practical applications. In this paper we address this issue and significantly bridge the gap between these two types of models. Throughout our empirical investigation we do not aim to necessarily propose a new method, but strive to identify a robust and effective recipe for making state-of-the-art large scale models affordable in practice. We demonstrate that, when performed correctly, knowledge distillation can be a powerful tool for reducing the size of large models without compromising their performance. In particular, we uncover that there are certain implicit design choices, which may drastically affect the effectiveness of distillation. Our key contribution is the explicit identification of these design choices, which were not previously articulated in the literature. We back up our findings by a comprehensive empirical study, demonstrate compelling results on a wide range of vision datasets and, in particular, obtain a state-of-the-art ResNet-50 model for ImageNet, which achieves 82.8\% top-1 accuracy.
Towards Understanding Normalization in Neural ODEs
Apr 27, 2020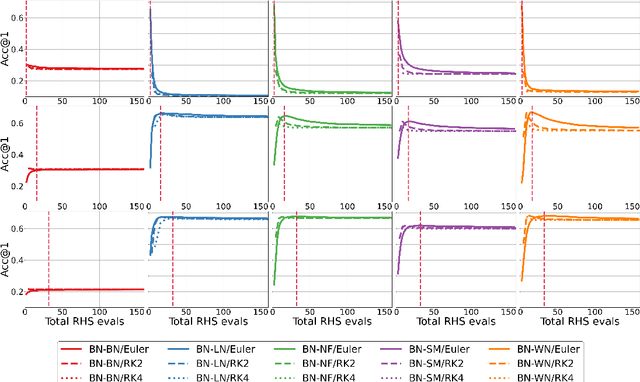
Normalization is an important and vastly investigated technique in deep learning. However, its role for Ordinary Differential Equation based networks (neural ODEs) is still poorly understood. This paper investigates how different normalization techniques affect the performance of neural ODEs. Particularly, we show that it is possible to achieve 93% accuracy in the CIFAR-10 classification task, and to the best of our knowledge, this is the highest reported accuracy among neural ODEs tested on this problem.