 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatically Differentiable Nonlinear Tensor Networks (ADNTNs) for Exponential Compression of Deep Neural Networks
May 28, 2026We study Automatically Differentiable Nonlinear Tensor Networks (ADNTNs), a family of structured weight generators whose compact core tensors are trained end-to-end by reverse-mode automatic differentiation (AD). The approach can be viewed as a natural extension of low-rank adaptation and tensor factorisation: instead of using one low-rank matrix update, an ADNTN builds a large weight tensor through a hierarchy of small cores, nonlinear activations, and optional lateral mixing tensors. The paper focuses on three architectures: Tree Tensor Networks (TTNs), augmented TTNs (aTTNs) with boundary disentanglers, and Multi-scale Entanglement Renormalisation Ansatze (MERA). The formulation supports nonlinear activations, task-aware objectives, batching, and hardware-aware execution schedules. At the same time, the paper keeps a clear distinction between \emph{differentiating} a contraction program and making contraction free: AD does not remove the cost of large intermediates, poor contraction orders, or exact contraction of general loopy tensor networks. Extensive simulations on AlexNet and VGG-16 layers show per-layer compression ratios from roughly $2000\times$ to $77000\times$ in the studied settings, with accuracy often matching the dense baseline and, in several VGG-16 cases, improving it. These results are encouraging rather than final: they suggest that ADNTNs are a promising, mathematically structured, and hardware-aware route toward much smaller neural networks, provided that optimisation, contraction schedules, and deployment kernels are designed together.
A New Tensor Network: Tubal Tensor Train and Its Applications
Mar 11, 2026We introduce the tubal tensor train (TTT) decomposition, a tensor-network model that combines the t-product algebra of the tensor singular value decomposition (T-SVD) with the low-order core structure of the tensor train (TT) format. For an order-$(N+1)$ tensor with a distinguished tube mode, the proposed representation consists of two third-order boundary cores and $N-2$ fourth-order interior cores linked through the t-product. As a result, for bounded tubal ranks, the storage scales linearly with the number of modes, in contrast to direct high-order extensions of T-SVD. We present two computational strategies: a sequential fixed-rank construction, called TTT-SVD, and a Fourier-slice alternating scheme based on the alternating two-cores update (ATCU). We also state a TT-SVD-type error bound for TTT-SVD and illustrate the practical performance of the proposed model on image compression, video compression, tensor completion, and hyperspectral imaging.
Group Entropies and Mirror Duality: A Class of Flexible Mirror Descent Updates for Machine Learning
Mar 09, 2026We introduce a comprehensive theoretical and algorithmic framework that bridges formal group theory and group entropies with modern machine learning, paving the way for an infinite, flexible family of Mirror Descent (MD) optimization algorithms. Our approach exploits the rich structure of group entropies, which are generalized entropic functionals governed by group composition laws, encompassing and significantly extending all trace-form entropies such as the Shannon, Tsallis, and Kaniadakis families. By leveraging group-theoretical mirror maps (or link functions) in MD, expressed via multi-parametric generalized logarithms and their inverses (group exponentials), we achieve highly flexible and adaptable MD updates that can be tailored to diverse data geometries and statistical distributions. To this end, we introduce the notion of \textit{mirror duality}, which allows us to seamlessly switch or interchange group-theoretical link functions with their inverses, subject to specific learning rate constraints. By tuning or learning the hyperparameters of the group logarithms enables us to adapt the model to the statistical properties of the training distribution, while simultaneously ensuring desirable convergence characteristics via fine-tuning. This generality not only provides greater flexibility and improved convergence properties, but also opens new perspectives for applications in machine learning and deep learning by expanding the design of regularizers and natural gradient algorithms. We extensively evaluate the validity, robustness, and performance of the proposed updates on large-scale, simplex-constrained quadratic programming problems.
Spontaneous Spatial Cognition Emerges during Egocentric Video Viewing through Non-invasive BCI
Jul 16, 2025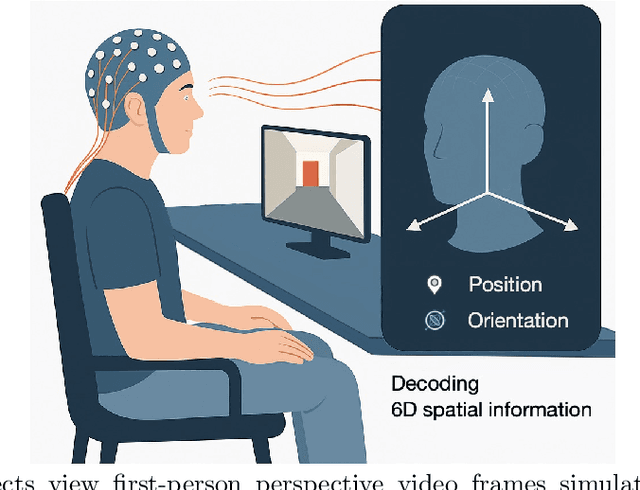

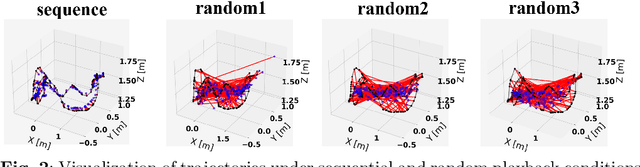

Humans possess a remarkable capacity for spatial cognition, allowing for self-localization even in novel or unfamiliar environments. While hippocampal neurons encoding position and orientation are well documented, the large-scale neural dynamics supporting spatial representation, particularly during naturalistic, passive experience, remain poorly understood. Here, we demonstrate for the first time that non-invasive brain-computer interfaces (BCIs) based on electroencephalography (EEG) can decode spontaneous, fine-grained egocentric 6D pose, comprising three-dimensional position and orientation, during passive viewing of egocentric video. Despite EEG's limited spatial resolution and high signal noise, we find that spatially coherent visual input (i.e., continuous and structured motion) reliably evokes decodable spatial representations, aligning with participants' subjective sense of spatial engagement. Decoding performance further improves when visual input is presented at a frame rate of 100 ms per image, suggesting alignment with intrinsic neural temporal dynamics. Using gradient-based backpropagation through a neural decoding model, we identify distinct EEG channels contributing to position -- and orientation specific -- components, revealing a distributed yet complementary neural encoding scheme. These findings indicate that the brain's spatial systems operate spontaneously and continuously, even under passive conditions, challenging traditional distinctions between active and passive spatial cognition. Our results offer a non-invasive window into the automatic construction of egocentric spatial maps and advance our understanding of how the human mind transforms everyday sensory experience into structured internal representations.
Mirror Descent and Novel Exponentiated Gradient Algorithms Using Trace-Form Entropies and Deformed Logarithms
Mar 11, 2025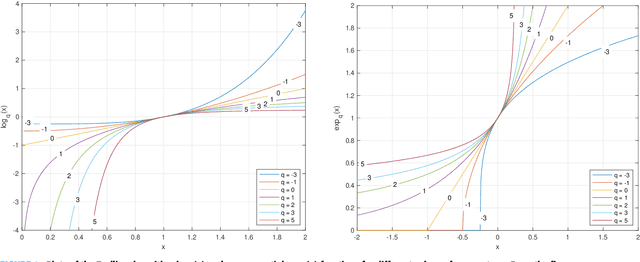
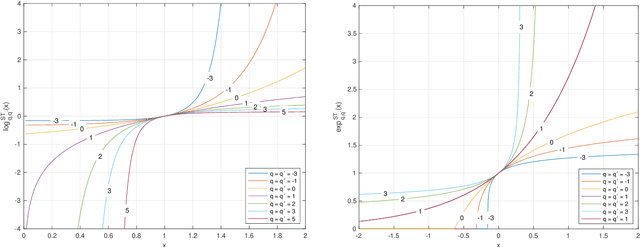
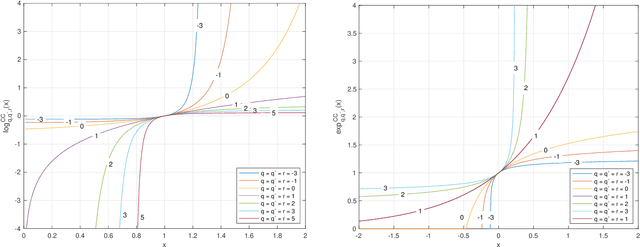
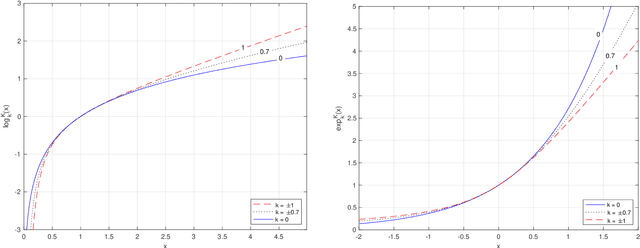
In this paper we propose and investigate a wide class of Mirror Descent updates (MD) and associated novel Generalized Exponentiated Gradient (GEG) algorithms by exploiting various trace-form entropies and associated deformed logarithms and their inverses - deformed (generalized) exponential functions. The proposed algorithms can be considered as extension of entropic MD and generalization of multiplicative updates. In the literature, there exist nowadays over fifty mathematically well defined generalized entropies, so impossible to exploit all of them in one research paper. So we focus on a few selected most popular entropies and associated logarithms like the Tsallis, Kaniadakis and Sharma-Taneja-Mittal and some of their extension like Tempesta or Kaniadakis-Scarfone entropies. The shape and properties of the deformed logarithms and their inverses are tuned by one or more hyperparameters. By learning these hyperparameters, we can adapt to distribution of training data, which can be designed to the specific geometry of the optimization problem, leading to potentially faster convergence and better performance. The using generalized entropies and associated deformed logarithms in the Bregman divergence, used as a regularization term, provides some new insight into exponentiated gradient descent updates.
VQ-Flow: Taming Normalizing Flows for Multi-Class Anomaly Detection via Hierarchical Vector Quantization
Sep 02, 2024
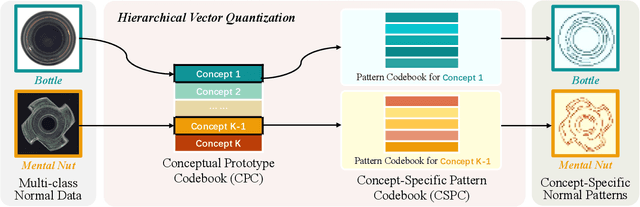
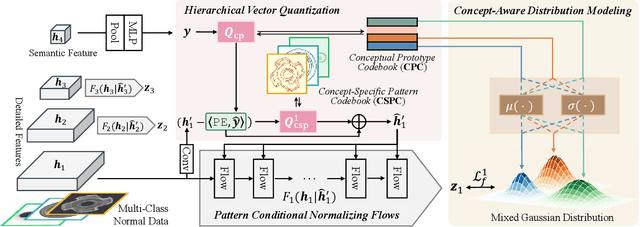
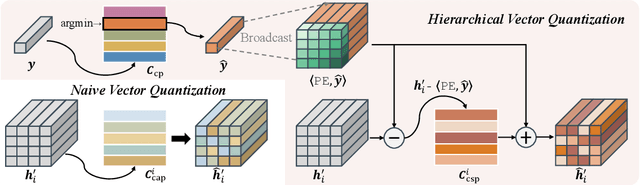
Normalizing flows, a category of probabilistic models famed for their capabilities in modeling complex data distributions, have exhibited remarkable efficacy in unsupervised anomaly detection. This paper explores the potential of normalizing flows in multi-class anomaly detection, wherein the normal data is compounded with multiple classes without providing class labels. Through the integration of vector quantization (VQ), we empower the flow models to distinguish different concepts of multi-class normal data in an unsupervised manner, resulting in a novel flow-based unified method, named VQ-Flow. Specifically, our VQ-Flow leverages hierarchical vector quantization to estimate two relative codebooks: a Conceptual Prototype Codebook (CPC) for concept distinction and its concomitant Concept-Specific Pattern Codebook (CSPC) to capture concept-specific normal patterns. The flow models in VQ-Flow are conditioned on the concept-specific patterns captured in CSPC, capable of modeling specific normal patterns associated with different concepts. Moreover, CPC further enables our VQ-Flow for concept-aware distribution modeling, faithfully mimicking the intricate multi-class normal distribution through a mixed Gaussian distribution reparametrized on the conceptual prototypes. Through the introduction of vector quantization, the proposed VQ-Flow advances the state-of-the-art in multi-class anomaly detection within a unified training scheme, yielding the Det./Loc. AUROC of 99.5%/98.3% on MVTec AD. The codebase is publicly available at https://github.com/cool-xuan/vqflow.
Generalized Exponentiated Gradient Algorithms and Their Application to On-Line Portfolio Selection
Jun 02, 2024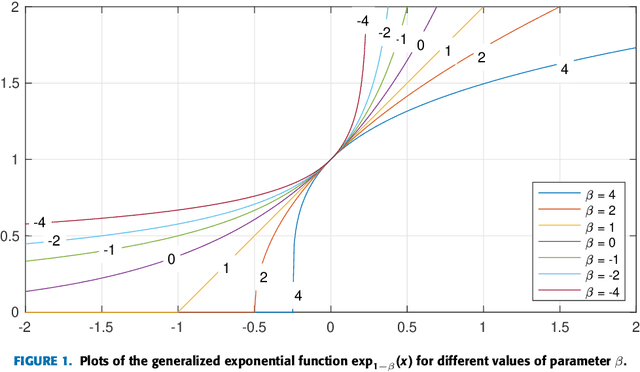
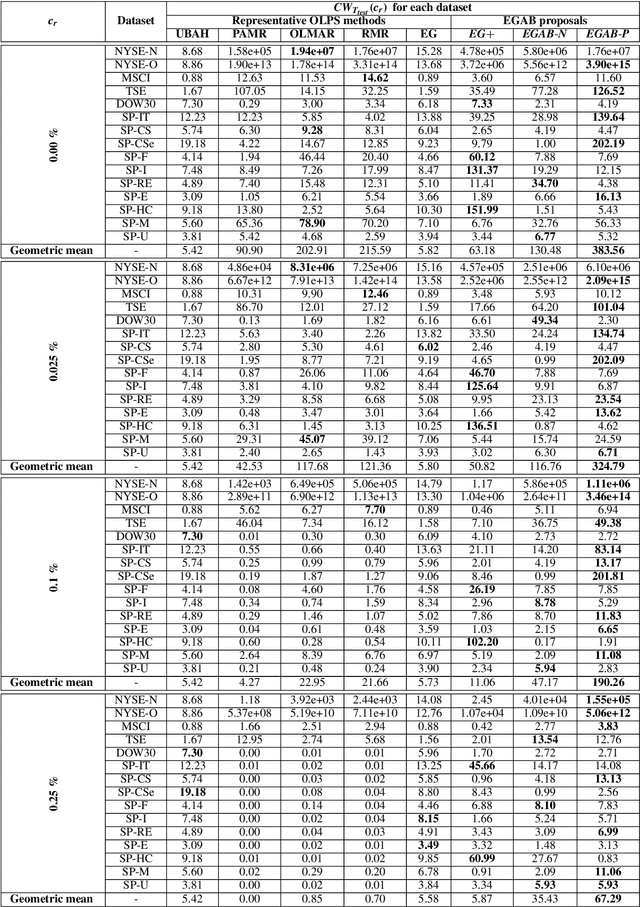
This paper introduces a novel family of generalized exponentiated gradient (EG) updates derived from an Alpha-Beta divergence regularization function. Collectively referred to as EGAB, the proposed updates belong to the category of multiplicative gradient algorithms for positive data and demonstrate considerable flexibility by controlling iteration behavior and performance through three hyperparameters: $\alpha$, $\beta$, and the learning rate $\eta$. To enforce a unit $l_1$ norm constraint for nonnegative weight vectors within generalized EGAB algorithms, we develop two slightly distinct approaches. One method exploits scale-invariant loss functions, while the other relies on gradient projections onto the feasible domain. As an illustration of their applicability, we evaluate the proposed updates in addressing the online portfolio selection problem (OLPS) using gradient-based methods. Here, they not only offer a unified perspective on the search directions of various OLPS algorithms (including the standard exponentiated gradient and diverse mean-reversion strategies), but also facilitate smooth interpolation and extension of these updates due to the flexibility in hyperparameter selection. Simulation results confirm that the adaptability of these generalized gradient updates can effectively enhance the performance for some portfolios, particularly in scenarios involving transaction costs.
Quantization Aware Factorization for Deep Neural Network Compression
Aug 08, 2023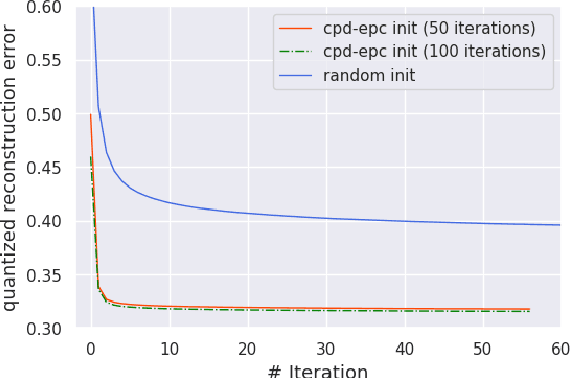
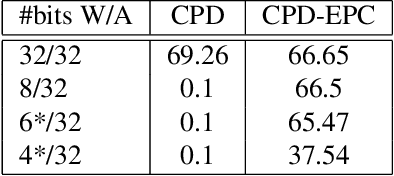
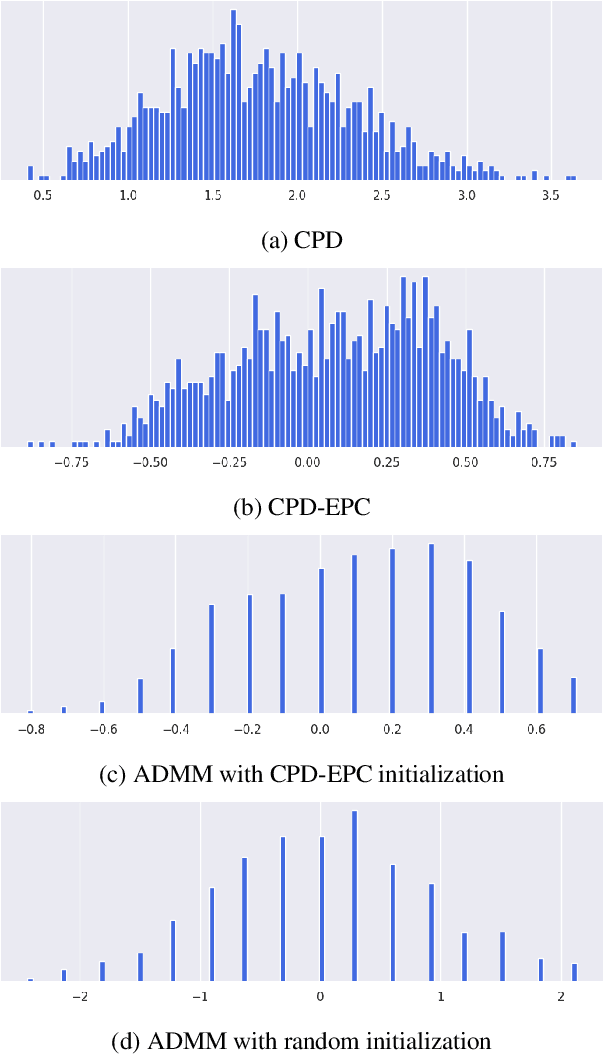
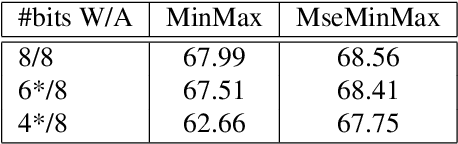
Tensor decomposition of convolutional and fully-connected layers is an effective way to reduce parameters and FLOP in neural networks. Due to memory and power consumption limitations of mobile or embedded devices, the quantization step is usually necessary when pre-trained models are deployed. A conventional post-training quantization approach applied to networks with decomposed weights yields a drop in accuracy. This motivated us to develop an algorithm that finds tensor approximation directly with quantized factors and thus benefit from both compression techniques while keeping the prediction quality of the model. Namely, we propose to use Alternating Direction Method of Multipliers (ADMM) for Canonical Polyadic (CP) decomposition with factors whose elements lie on a specified quantization grid. We compress neural network weights with a devised algorithm and evaluate it's prediction quality and performance. We compare our approach to state-of-the-art post-training quantization methods and demonstrate competitive results and high flexibility in achiving a desirable quality-performance tradeoff.
Optical Coherence Tomography Image Enhancement via Block Hankelization and Low Rank Tensor Network Approximation
Jun 19, 2023In this paper, the problem of image super-resolution for Optical Coherence Tomography (OCT) has been addressed. Due to the motion artifacts, OCT imaging is usually done with a low sampling rate and the resulting images are often noisy and have low resolution. Therefore, reconstruction of high resolution OCT images from the low resolution versions is an essential step for better OCT based diagnosis. In this paper, we propose a novel OCT super-resolution technique using Tensor Ring decomposition in the embedded space. A new tensorization method based on a block Hankelization approach with overlapped patches, called overlapped patch Hankelization, has been proposed which allows us to employ Tensor Ring decomposition. The Hankelization method enables us to better exploit the inter connection of pixels and consequently achieve better super-resolution of images. The low resolution image was first patch Hankelized and then its Tensor Ring decomposition with rank incremental has been computed. Simulation results confirm that the proposed approach is effective in OCT super-resolution.
Lightweight Attribute Localizing Models for Pedestrian Attribute Recognition
Jun 16, 2023
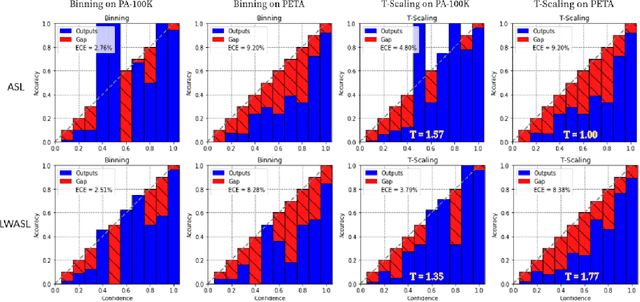
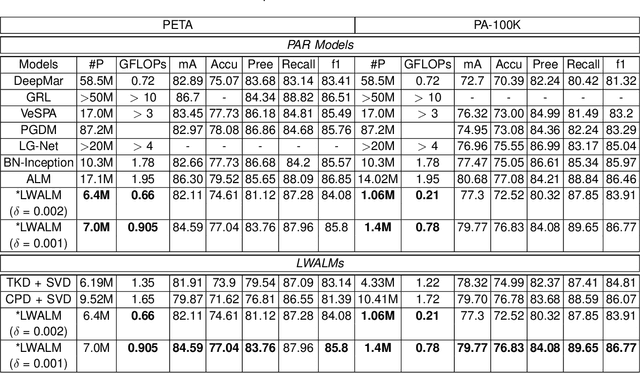
Pedestrian Attribute Recognition (PAR) deals with the problem of identifying features in a pedestrian image. It has found interesting applications in person retrieval, suspect re-identification and soft biometrics. In the past few years, several Deep Neural Networks (DNNs) have been designed to solve the task; however, the developed DNNs predominantly suffer from over-parameterization and high computational complexity. These problems hinder them from being exploited in resource-constrained embedded devices with limited memory and computational capacity. By reducing a network's layers using effective compression techniques, such as tensor decomposition, neural network compression is an effective method to tackle these problems. We propose novel Lightweight Attribute Localizing Models (LWALM) for Pedestrian Attribute Recognition (PAR). LWALM is a compressed neural network obtained after effective layer-wise compression of the Attribute Localization Model (ALM) using the Canonical Polyadic Decomposition with Error Preserving Correction (CPD-EPC) algorithm.