 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMirror Descent and Novel Exponentiated Gradient Algorithms Using Trace-Form Entropies and Deformed Logarithms
Mar 11, 2025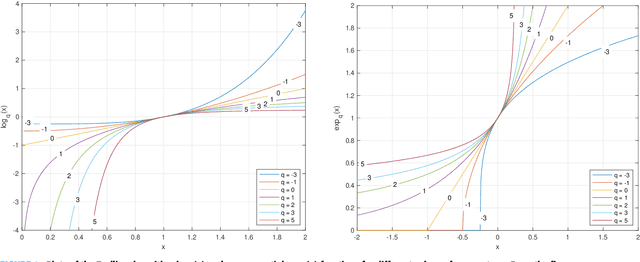
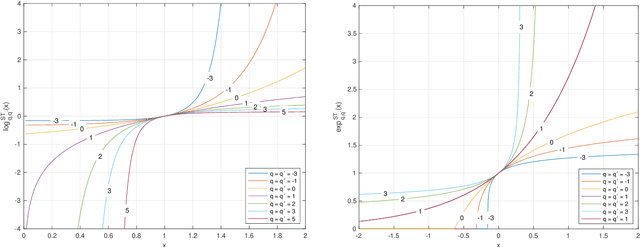
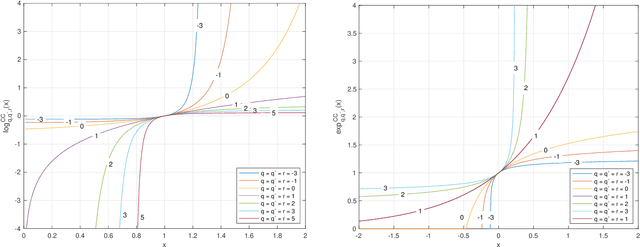
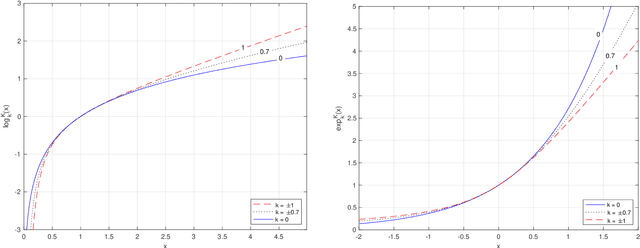
In this paper we propose and investigate a wide class of Mirror Descent updates (MD) and associated novel Generalized Exponentiated Gradient (GEG) algorithms by exploiting various trace-form entropies and associated deformed logarithms and their inverses - deformed (generalized) exponential functions. The proposed algorithms can be considered as extension of entropic MD and generalization of multiplicative updates. In the literature, there exist nowadays over fifty mathematically well defined generalized entropies, so impossible to exploit all of them in one research paper. So we focus on a few selected most popular entropies and associated logarithms like the Tsallis, Kaniadakis and Sharma-Taneja-Mittal and some of their extension like Tempesta or Kaniadakis-Scarfone entropies. The shape and properties of the deformed logarithms and their inverses are tuned by one or more hyperparameters. By learning these hyperparameters, we can adapt to distribution of training data, which can be designed to the specific geometry of the optimization problem, leading to potentially faster convergence and better performance. The using generalized entropies and associated deformed logarithms in the Bregman divergence, used as a regularization term, provides some new insight into exponentiated gradient descent updates.
Generalized Exponentiated Gradient Algorithms and Their Application to On-Line Portfolio Selection
Jun 02, 2024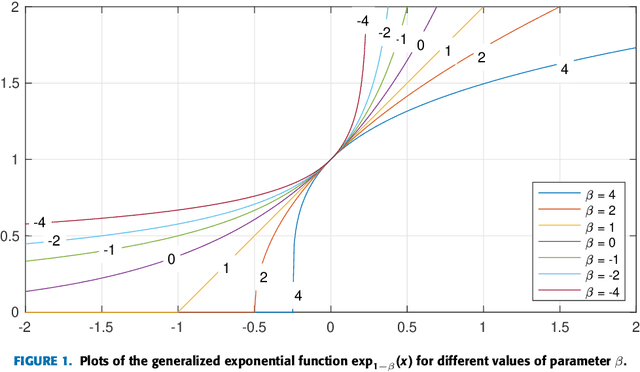
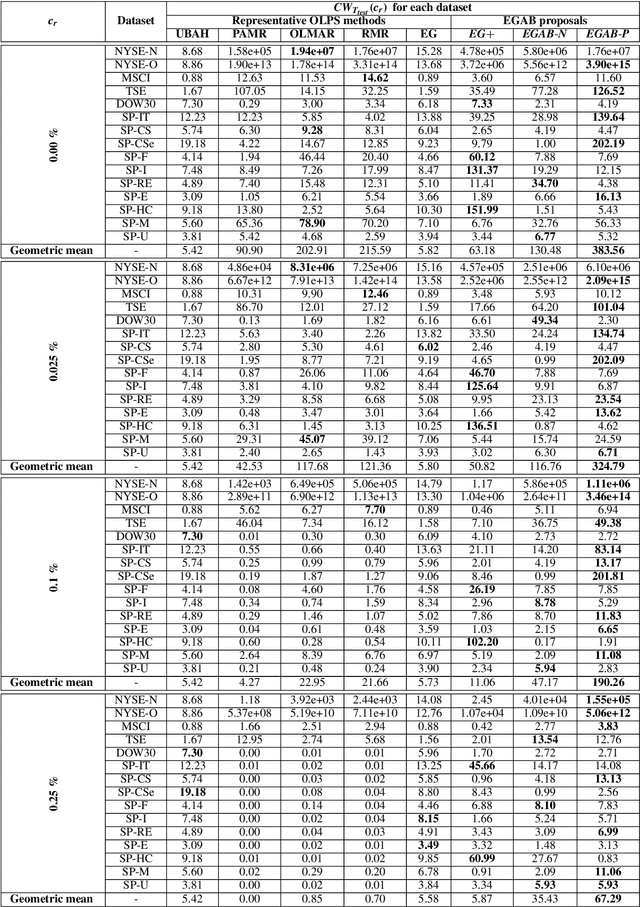
This paper introduces a novel family of generalized exponentiated gradient (EG) updates derived from an Alpha-Beta divergence regularization function. Collectively referred to as EGAB, the proposed updates belong to the category of multiplicative gradient algorithms for positive data and demonstrate considerable flexibility by controlling iteration behavior and performance through three hyperparameters: $\alpha$, $\beta$, and the learning rate $\eta$. To enforce a unit $l_1$ norm constraint for nonnegative weight vectors within generalized EGAB algorithms, we develop two slightly distinct approaches. One method exploits scale-invariant loss functions, while the other relies on gradient projections onto the feasible domain. As an illustration of their applicability, we evaluate the proposed updates in addressing the online portfolio selection problem (OLPS) using gradient-based methods. Here, they not only offer a unified perspective on the search directions of various OLPS algorithms (including the standard exponentiated gradient and diverse mean-reversion strategies), but also facilitate smooth interpolation and extension of these updates due to the flexibility in hyperparameter selection. Simulation results confirm that the adaptability of these generalized gradient updates can effectively enhance the performance for some portfolios, particularly in scenarios involving transaction costs.