 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBandVQ: Band-Wise Vector-Quantized EEG Foundation Model
May 24, 2026A central challenge in electroencephalography (EEG) foundation modeling is learning transferable representations across recordings with diverse tasks, montages, references, and spectral characteristics. Existing masked modeling approaches often rely on broadband continuous patches or a single discrete representation, which may underrepresent frequency-specific activity. This paper proposes BandVQ, a band-wise vector-quantized EEG foundation model that decomposes EEG into delta, theta, alpha, beta, and gamma bands, trains an independent VQ-VAE tokenizer for each band, and pretrains a shared Transformer encoder on the resulting discrete VQ code indices. The encoder uses masked code tokens, quantized absolute log-power tokens, channel and temporal embeddings, and metadata prefix tokens representing reference, band, task family, and phase. Region-based masking is also introduced to reduce the trivial reconstruction of spatially adjacent electrodes. The model is pretrained on 71 public EEG corpora comprising over 9,200 subjects and 357,000 single-channel hours and evaluated on six subject-independent classification datasets. Under the current evaluation setting, the proposed model achieves strong transfer performance, with the highest reported results on three cognitive tasks and competitive performance on three motor imagery tasks.
Structured Unitary Tensor Network Representations for Circuit-Efficient Quantum Data Encoding
Feb 18, 2026Encoding classical data into quantum states is a central bottleneck in quantum machine learning: many widely used encodings are circuit-inefficient, requiring deep circuits and substantial quantum resources, which limits scalability on quantum hardware. In this work, we propose TNQE, a circuit-efficient quantum data encoding framework built on structured unitary tensor network (TN) representations. TNQE first represents each classical input via a TN decomposition and then compiles the resulting tensor cores into an encoding circuit through two complementary core-to-circuit strategies. To make this compilation trainable while respecting the unitary nature of quantum operations, we introduce a unitary-aware constraint that parameterizes TN cores as learnable block unitaries, enabling them to be directly optimized and directly encoded as quantum operators. The proposed TNQE framework enables explicit control over circuit depth and qubit resources, allowing the construction of shallow, resource-efficient circuits. Across a range of benchmarks, TNQE achieves encoding circuits as shallow as $0.04\times$ the depth of amplitude encoding, while naturally scaling to high-resolution images ($256 \times 256$) and demonstrating practical feasibility on real quantum hardware.
Parameter-Efficient Fine-Tuning of 3D DDPM for MRI Image Generation Using Tensor Networks
Jul 24, 2025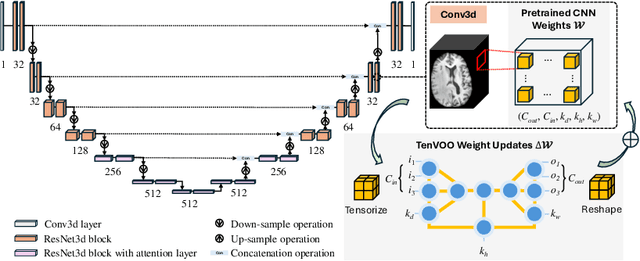

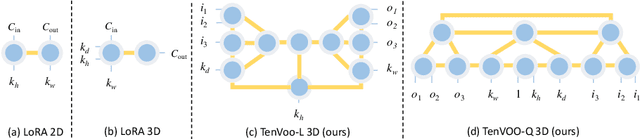

We address the challenge of parameter-efficient fine-tuning (PEFT) for three-dimensional (3D) U-Net-based denoising diffusion probabilistic models (DDPMs) in magnetic resonance imaging (MRI) image generation. Despite its practical significance, research on parameter-efficient representations of 3D convolution operations remains limited. To bridge this gap, we propose Tensor Volumetric Operator (TenVOO), a novel PEFT method specifically designed for fine-tuning DDPMs with 3D convolutional backbones. Leveraging tensor network modeling, TenVOO represents 3D convolution kernels with lower-dimensional tensors, effectively capturing complex spatial dependencies during fine-tuning with few parameters. We evaluate TenVOO on three downstream brain MRI datasets-ADNI, PPMI, and BraTS2021-by fine-tuning a DDPM pretrained on 59,830 T1-weighted brain MRI scans from the UK Biobank. Our results demonstrate that TenVOO achieves state-of-the-art performance in multi-scale structural similarity index measure (MS-SSIM), outperforming existing approaches in capturing spatial dependencies while requiring only 0.3% of the trainable parameters of the original model. Our code is available at: https://github.com/xiaovhua/tenvoo
MR-EEGWaveNet: Multiresolutional EEGWaveNet for Seizure Detection from Long EEG Recordings
May 23, 2025Feature engineering for generalized seizure detection models remains a significant challenge. Recently proposed models show variable performance depending on the training data and remain ineffective at accurately distinguishing artifacts from seizure data. In this study, we propose a novel end-to-end model, ''Multiresolutional EEGWaveNet (MR-EEGWaveNet),'' which efficiently distinguishes seizure events from background electroencephalogram (EEG) and artifacts/noise by capturing both temporal dependencies across different time frames and spatial relationships between channels. The model has three modules: convolution, feature extraction, and predictor. The convolution module extracts features through depth-wise and spatio-temporal convolution. The feature extraction module individually reduces the feature dimension extracted from EEG segments and their sub-segments. Subsequently, the extracted features are concatenated into a single vector for classification using a fully connected classifier called the predictor module. In addition, an anomaly score-based post-classification processing technique was introduced to reduce the false-positive rates of the model. Experimental results were reported and analyzed using different parameter settings and datasets (Siena (public) and Juntendo (private)). The proposed MR-EEGWaveNet significantly outperformed the conventional non-multiresolution approach, improving the F1 scores from 0.177 to 0.336 on Siena and 0.327 to 0.488 on Juntendo, with precision gains of 15.9% and 20.62%, respectively.
Mirror Descent and Novel Exponentiated Gradient Algorithms Using Trace-Form Entropies and Deformed Logarithms
Mar 11, 2025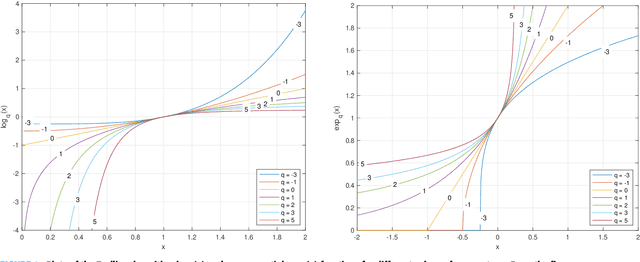
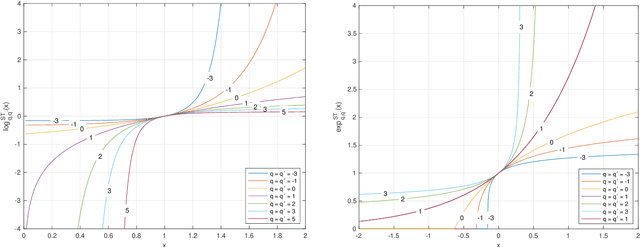
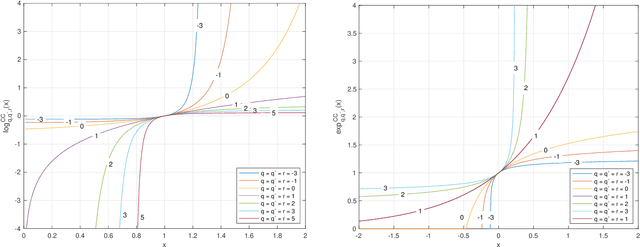
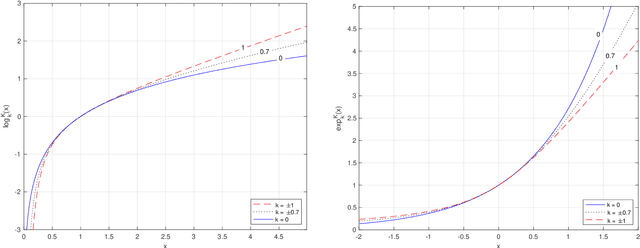
In this paper we propose and investigate a wide class of Mirror Descent updates (MD) and associated novel Generalized Exponentiated Gradient (GEG) algorithms by exploiting various trace-form entropies and associated deformed logarithms and their inverses - deformed (generalized) exponential functions. The proposed algorithms can be considered as extension of entropic MD and generalization of multiplicative updates. In the literature, there exist nowadays over fifty mathematically well defined generalized entropies, so impossible to exploit all of them in one research paper. So we focus on a few selected most popular entropies and associated logarithms like the Tsallis, Kaniadakis and Sharma-Taneja-Mittal and some of their extension like Tempesta or Kaniadakis-Scarfone entropies. The shape and properties of the deformed logarithms and their inverses are tuned by one or more hyperparameters. By learning these hyperparameters, we can adapt to distribution of training data, which can be designed to the specific geometry of the optimization problem, leading to potentially faster convergence and better performance. The using generalized entropies and associated deformed logarithms in the Bregman divergence, used as a regularization term, provides some new insight into exponentiated gradient descent updates.
Model-Free Adversarial Purification via Coarse-To-Fine Tensor Network Representation
Feb 25, 2025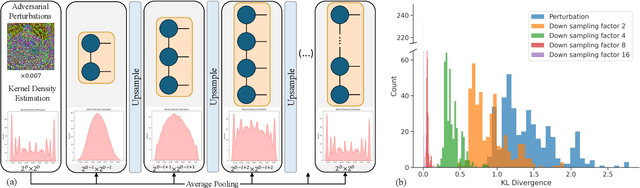
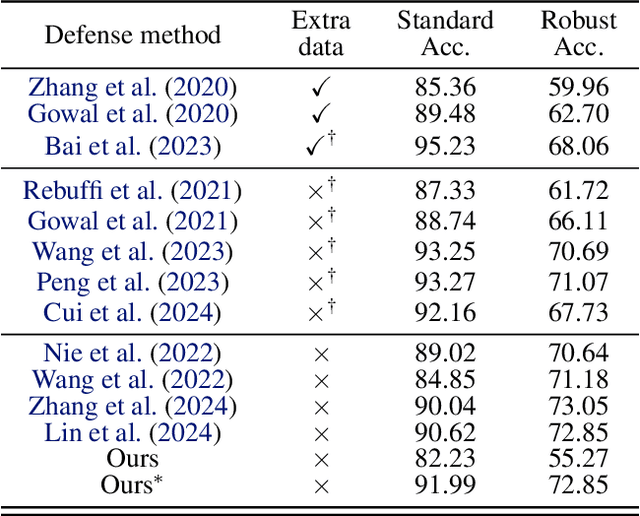
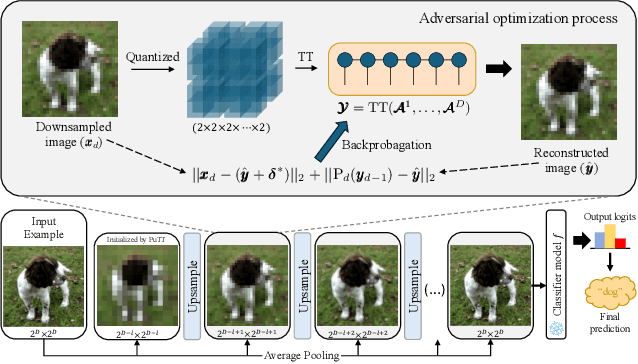
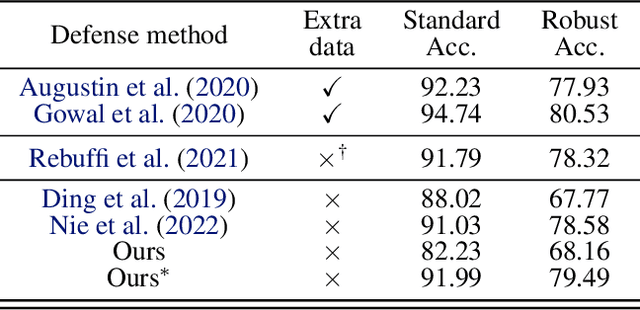
Deep neural networks are known to be vulnerable to well-designed adversarial attacks. Although numerous defense strategies have been proposed, many are tailored to the specific attacks or tasks and often fail to generalize across diverse scenarios. In this paper, we propose Tensor Network Purification (TNP), a novel model-free adversarial purification method by a specially designed tensor network decomposition algorithm. TNP depends neither on the pre-trained generative model nor the specific dataset, resulting in strong robustness across diverse adversarial scenarios. To this end, the key challenge lies in relaxing Gaussian-noise assumptions of classical decompositions and accommodating the unknown distribution of adversarial perturbations. Unlike the low-rank representation of classical decompositions, TNP aims to reconstruct the unobserved clean examples from an adversarial example. Specifically, TNP leverages progressive downsampling and introduces a novel adversarial optimization objective to address the challenge of minimizing reconstruction error but without inadvertently restoring adversarial perturbations. Extensive experiments conducted on CIFAR-10, CIFAR-100, and ImageNet demonstrate that our method generalizes effectively across various norm threats, attack types, and tasks, providing a versatile and promising adversarial purification technique.
Scalable Bayesian Tensor Ring Factorization for Multiway Data Analysis
Dec 04, 2024Tensor decompositions play a crucial role in numerous applications related to multi-way data analysis. By employing a Bayesian framework with sparsity-inducing priors, Bayesian Tensor Ring (BTR) factorization offers probabilistic estimates and an effective approach for automatically adapting the tensor ring rank during the learning process. However, previous BTR method employs an Automatic Relevance Determination (ARD) prior, which can lead to sub-optimal solutions. Besides, it solely focuses on continuous data, whereas many applications involve discrete data. More importantly, it relies on the Coordinate-Ascent Variational Inference (CAVI) algorithm, which is inadequate for handling large tensors with extensive observations. These limitations greatly limit its application scales and scopes, making it suitable only for small-scale problems, such as image/video completion. To address these issues, we propose a novel BTR model that incorporates a nonparametric Multiplicative Gamma Process (MGP) prior, known for its superior accuracy in identifying latent structures. To handle discrete data, we introduce the P\'olya-Gamma augmentation for closed-form updates. Furthermore, we develop an efficient Gibbs sampler for consistent posterior simulation, which reduces the computational complexity of previous VI algorithm by two orders, and an online EM algorithm that is scalable to extremely large tensors. To showcase the advantages of our model, we conduct extensive experiments on both simulation data and real-world applications.
Generalized Exponentiated Gradient Algorithms and Their Application to On-Line Portfolio Selection
Jun 02, 2024
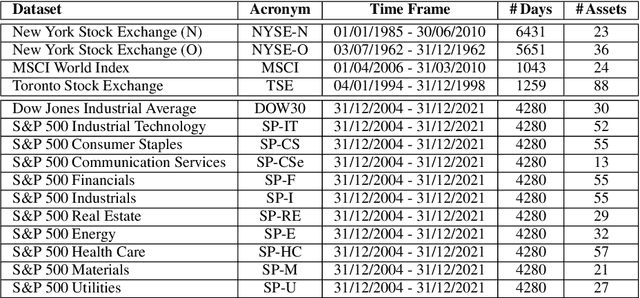
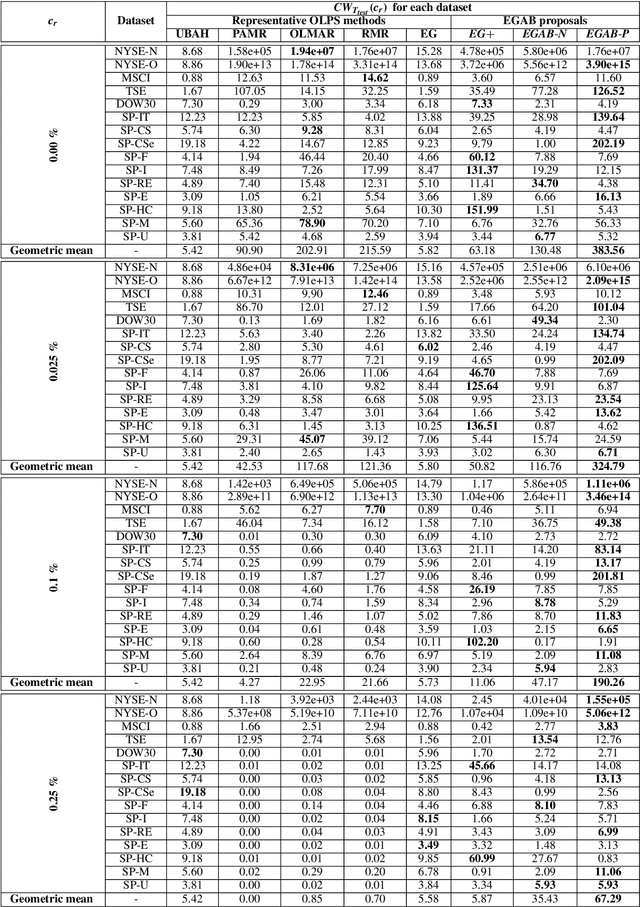
This paper introduces a novel family of generalized exponentiated gradient (EG) updates derived from an Alpha-Beta divergence regularization function. Collectively referred to as EGAB, the proposed updates belong to the category of multiplicative gradient algorithms for positive data and demonstrate considerable flexibility by controlling iteration behavior and performance through three hyperparameters: $\alpha$, $\beta$, and the learning rate $\eta$. To enforce a unit $l_1$ norm constraint for nonnegative weight vectors within generalized EGAB algorithms, we develop two slightly distinct approaches. One method exploits scale-invariant loss functions, while the other relies on gradient projections onto the feasible domain. As an illustration of their applicability, we evaluate the proposed updates in addressing the online portfolio selection problem (OLPS) using gradient-based methods. Here, they not only offer a unified perspective on the search directions of various OLPS algorithms (including the standard exponentiated gradient and diverse mean-reversion strategies), but also facilitate smooth interpolation and extension of these updates due to the flexibility in hyperparameter selection. Simulation results confirm that the adaptability of these generalized gradient updates can effectively enhance the performance for some portfolios, particularly in scenarios involving transaction costs.
MAProtoNet: A Multi-scale Attentive Interpretable Prototypical Part Network for 3D Magnetic Resonance Imaging Brain Tumor Classification
Apr 13, 2024Automated diagnosis with artificial intelligence has emerged as a promising area in the realm of medical imaging, while the interpretability of the introduced deep neural networks still remains an urgent concern. Although contemporary works, such as XProtoNet and MProtoNet, has sought to design interpretable prediction models for the issue, the localization precision of their resulting attribution maps can be further improved. To this end, we propose a Multi-scale Attentive Prototypical part Network, termed MAProtoNet, to provide more precise maps for attribution. Specifically, we introduce a concise multi-scale module to merge attentive features from quadruplet attention layers, and produces attribution maps. The proposed quadruplet attention layers can enhance the existing online class activation mapping loss via capturing interactions between the spatial and channel dimension, while the multi-scale module then fuses both fine-grained and coarse-grained information for precise maps generation. We also apply a novel multi-scale mapping loss for supervision on the proposed multi-scale module. Compared to existing interpretable prototypical part networks in medical imaging, MAProtoNet can achieve state-of-the-art performance in localization on brain tumor segmentation (BraTS) datasets, resulting in approximately 4% overall improvement on activation precision score (with a best score of 85.8%), without using additional annotated labels of segmentation. Our code will be released in https://github.com/TUAT-Novice/maprotonet.
Robust Diffusion Models for Adversarial Purification
Mar 24, 2024Diffusion models (DMs) based adversarial purification (AP) has shown to be the most powerful alternative to adversarial training (AT). However, these methods neglect the fact that pre-trained diffusion models themselves are not robust to adversarial attacks as well. Additionally, the diffusion process can easily destroy semantic information and generate a high quality image but totally different from the original input image after the reverse process, leading to degraded standard accuracy. To overcome these issues, a natural idea is to harness adversarial training strategy to retrain or fine-tune the pre-trained diffusion model, which is computationally prohibitive. We propose a novel robust reverse process with adversarial guidance, which is independent of given pre-trained DMs and avoids retraining or fine-tuning the DMs. This robust guidance can not only ensure to generate purified examples retaining more semantic content but also mitigate the accuracy-robustness trade-off of DMs for the first time, which also provides DM-based AP an efficient adaptive ability to new attacks. Extensive experiments are conducted to demonstrate that our method achieves the state-of-the-art results and exhibits generalization against different attacks.