 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShotFinder: Imagination-Driven Open-Domain Video Shot Retrieval via Web Search
Jan 30, 2026In recent years, large language models (LLMs) have made rapid progress in information retrieval, yet existing research has mainly focused on text or static multimodal settings. Open-domain video shot retrieval, which involves richer temporal structure and more complex semantics, still lacks systematic benchmarks and analysis. To fill this gap, we introduce ShotFinder, a benchmark that formalizes editing requirements as keyframe-oriented shot descriptions and introduces five types of controllable single-factor constraints: Temporal order, Color, Visual style, Audio, and Resolution. We curate 1,210 high-quality samples from YouTube across 20 thematic categories, using large models for generation with human verification. Based on the benchmark, we propose ShotFinder, a text-driven three-stage retrieval and localization pipeline: (1) query expansion via video imagination, (2) candidate video retrieval with a search engine, and (3) description-guided temporal localization. Experiments on multiple closed-source and open-source models reveal a significant gap to human performance, with clear imbalance across constraints: temporal localization is relatively tractable, while color and visual style remain major challenges. These results reveal that open-domain video shot retrieval is still a critical capability that multimodal large models have yet to overcome.
MAProtoNet: A Multi-scale Attentive Interpretable Prototypical Part Network for 3D Magnetic Resonance Imaging Brain Tumor Classification
Apr 13, 2024Automated diagnosis with artificial intelligence has emerged as a promising area in the realm of medical imaging, while the interpretability of the introduced deep neural networks still remains an urgent concern. Although contemporary works, such as XProtoNet and MProtoNet, has sought to design interpretable prediction models for the issue, the localization precision of their resulting attribution maps can be further improved. To this end, we propose a Multi-scale Attentive Prototypical part Network, termed MAProtoNet, to provide more precise maps for attribution. Specifically, we introduce a concise multi-scale module to merge attentive features from quadruplet attention layers, and produces attribution maps. The proposed quadruplet attention layers can enhance the existing online class activation mapping loss via capturing interactions between the spatial and channel dimension, while the multi-scale module then fuses both fine-grained and coarse-grained information for precise maps generation. We also apply a novel multi-scale mapping loss for supervision on the proposed multi-scale module. Compared to existing interpretable prototypical part networks in medical imaging, MAProtoNet can achieve state-of-the-art performance in localization on brain tumor segmentation (BraTS) datasets, resulting in approximately 4% overall improvement on activation precision score (with a best score of 85.8%), without using additional annotated labels of segmentation. Our code will be released in https://github.com/TUAT-Novice/maprotonet.
ReadNet: A Hierarchical Transformer Framework for Web Article Readability Analysis
Mar 06, 2021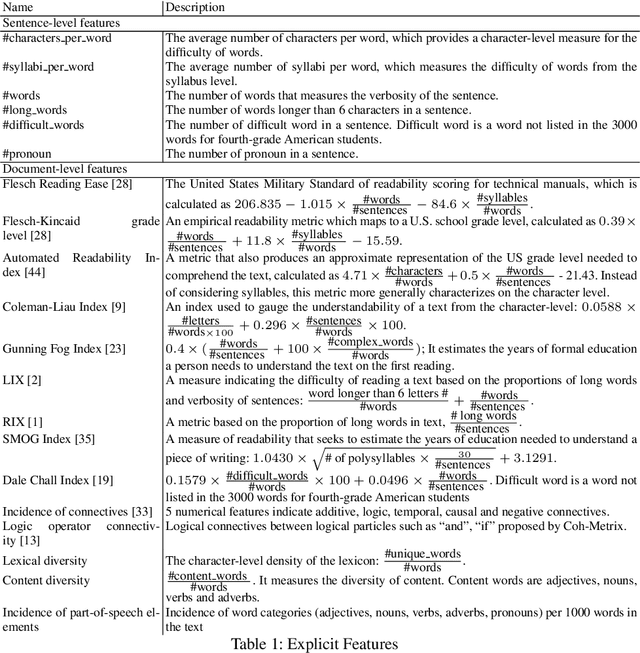

Analyzing the readability of articles has been an important sociolinguistic task. Addressing this task is necessary to the automatic recommendation of appropriate articles to readers with different comprehension abilities, and it further benefits education systems, web information systems, and digital libraries. Current methods for assessing readability employ empirical measures or statistical learning techniques that are limited by their ability to characterize complex patterns such as article structures and semantic meanings of sentences. In this paper, we propose a new and comprehensive framework which uses a hierarchical self-attention model to analyze document readability. In this model, measurements of sentence-level difficulty are captured along with the semantic meanings of each sentence. Additionally, the sentence-level features are incorporated to characterize the overall readability of an article with consideration of article structures. We evaluate our proposed approach on three widely-used benchmark datasets against several strong baseline approaches. Experimental results show that our proposed method achieves the state-of-the-art performance on estimating the readability for various web articles and literature.