 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGUIDE: Goal-Initialized Directional Understanding for End-to-End Visual Navigation
Jun 09, 2026Learning-based visual navigation for legged robots typically relies on continuous goal updates from hierarchical state estimation to provide a persistent directional reference. This reliance incurs additional sensory and computational overhead and deviates from fully end-to-end mobile autonomy. Furthermore, under partial observability, policies are prone to learn myopic behaviors, easily becoming trapped in dead ends and complex structural layouts. To address these limitations, we investigate a goal-initialized navigation setting, where the target is provided only once at the beginning of an episode, requiring the robot to operate based on intrinsic spatial memory without subsequent goal updates from external modules. In this work, we propose GUIDE, a fully end-to-end reinforcement learning framework designed to cultivate internal directional awareness. Specifically, GUIDE incorporates a spatial anchor predictor that leverages multi-frequency proprioceptive history to extract egomotion representations, thereby maintaining a persistent long-horizon spatial context for navigation. Concurrently, it utilizes raw depth streams to perceive local environmental geometry. We evaluate the proposed framework across both simulation and real-world scenarios on a quadruped robot. Experiments show that GUIDE learns reliable egomotion and directional awareness, enabling a fully end-to-end deployed policy to safely navigate through dense clutter and structured mazes without subsequent goal guidance or prior maps.
BotDirector: Robot Storytelling Across the Symmetrical Reality with Multi-modal Interactions
Jun 02, 2026Robot storytelling offers a unique blend of technological innovation and creative expression that engages children in unprecedented ways. However, the technical aspects are often too complicated for children. We propose an interactive system that facilitates robot storytelling with tangible and natural language interactions. Children arrange the playground with their own stuff and create narratives with an LLM agent. The created narratives are transformed into a motion sequence based on the map and characters, and the motions are executed by self-navigating swarm robots. This system enhances robot storytelling with flexible scenarios, enabling young children to create robot dramas with everyday objects.
Compressive sensing inspired self-supervised single-pixel imaging
Mar 31, 2026Single-pixel imaging (SPI) is a promising imaging modality with distinctive advantages in strongly perturbed environments. Existing SPI methods lack physical sparsity constraints and overlook the integration of local and global features, leading to severe noise vulnerability, structural distortions and blurred details. To address these limitations, we propose SISTA-Net, a compressive sensing-inspired self-supervised method for single-pixel imaging. SISTA-Net unfolds the Iterative Shrinkage-Thresholding Algorithm (ISTA) into an interpretable network consisting of a data fidelity module and a proximal mapping module. The fidelity module adopts a hybrid CNN-Visual State Space Model (VSSM) architecture to integrate local and global feature modeling, enhancing reconstruction integrity and fidelity. We leverage deep nonlinear networks as adaptive sparse transforms combined with a learnable soft-thresholding operator to impose explicit physical sparsity in the latent domain, enabling noise suppression and robustness to interference even at extremely low sampling rates. Extensive experiments on multiple simulation scenarios demonstrate that SISTA-Net outperforms state-of-the-art methods by 2.6 dB in PSNR. Real-world far-field underwater tests yield a 3.4 dB average PSNR improvement, validating its robust anti-interference capability.
Advancing Visual Reliability: Color-Accurate Underwater Image Enhancement for Real-Time Underwater Missions
Mar 17, 2026Underwater image enhancement plays a crucial role in providing reliable visual information for underwater platforms, since strong absorption and scattering in water-related environments generally lead to image quality degradation. Existing high-performance methods often rely on complex architectures, which hinder deployment on underwater devices. Lightweight methods often sacrifice quality for speed and struggle to handle severely degraded underwater images. To address this limitation, we present a real-time underwater image enhancement framework with accurate color restoration. First, an Adaptive Weighted Channel Compensation module is introduced to achieve dynamic color recovery of the red and blue channels using the green channel as a reference anchor. Second, we design a Multi-branch Re-parameterized Dilated Convolution that employs multi-branch fusion during training and structural re-parameterization during inference, enabling large receptive field representation with low computational overhead. Finally, a Statistical Global Color Adjustment module is employed to optimize overall color performance based on statistical priors. Extensive experiments on eight datasets demonstrate that the proposed method achieves state-of-the-art performance across seven evaluation metrics. The model contains only 3,880 inference parameters and achieves an inference speed of 409 FPS. Our method improves the UCIQE score by 29.7% under diverse environmental conditions, and the deployment on ROV platforms and performance gains in downstream tasks further validate its superiority for real-time underwater missions.
AdaptOVCD: Training-Free Open-Vocabulary Remote Sensing Change Detection via Adaptive Information Fusion
Feb 06, 2026Remote sensing change detection plays a pivotal role in domains such as environmental monitoring, urban planning, and disaster assessment. However, existing methods typically rely on predefined categories and large-scale pixel-level annotations, which limit their generalization and applicability in open-world scenarios. To address these limitations, this paper proposes AdaptOVCD, a training-free Open-Vocabulary Change Detection (OVCD) architecture based on dual-dimensional multi-level information fusion. The framework integrates multi-level information fusion across data, feature, and decision levels vertically while incorporating targeted adaptive designs horizontally, achieving deep synergy among heterogeneous pre-trained models to effectively mitigate error propagation. Specifically, (1) at the data level, Adaptive Radiometric Alignment (ARA) fuses radiometric statistics with original texture features and synergizes with SAM-HQ to achieve radiometrically consistent segmentation; (2) at the feature level, Adaptive Change Thresholding (ACT) combines global difference distributions with edge structure priors and leverages DINOv3 to achieve robust change detection; (3) at the decision level, Adaptive Confidence Filtering (ACF) integrates semantic confidence with spatial constraints and collaborates with DGTRS-CLIP to achieve high-confidence semantic identification. Comprehensive evaluations across nine scenarios demonstrate that AdaptOVCD detects arbitrary category changes in a zero-shot manner, significantly outperforming existing training-free methods. Meanwhile, it achieves 84.89\% of the fully-supervised performance upper bound in cross-dataset evaluations and exhibits superior generalization capabilities. The code is available at https://github.com/Dmygithub/AdaptOVCD.
PUMA: Perception-driven Unified Foothold Prior for Mobility Augmented Quadruped Parkour
Jan 22, 2026Parkour tasks for quadrupeds have emerged as a promising benchmark for agile locomotion. While human athletes can effectively perceive environmental characteristics to select appropriate footholds for obstacle traversal, endowing legged robots with similar perceptual reasoning remains a significant challenge. Existing methods often rely on hierarchical controllers that follow pre-computed footholds, thereby constraining the robot's real-time adaptability and the exploratory potential of reinforcement learning. To overcome these challenges, we present PUMA, an end-to-end learning framework that integrates visual perception and foothold priors into a single-stage training process. This approach leverages terrain features to estimate egocentric polar foothold priors, composed of relative distance and heading, guiding the robot in active posture adaptation for parkour tasks. Extensive experiments conducted in simulation and real-world environments across various discrete complex terrains, demonstrate PUMA's exceptional agility and robustness in challenging scenarios.
Single-Pixel Vision-Language Model for Intrinsic Privacy-Preserving Behavioral Intelligence
Jan 21, 2026Adverse social interactions, such as bullying, harassment, and other illicit activities, pose significant threats to individual well-being and public safety, leaving profound impacts on physical and mental health. However, these critical events frequently occur in privacy-sensitive environments like restrooms, and changing rooms, where conventional surveillance is prohibited or severely restricted by stringent privacy regulations and ethical concerns. Here, we propose the Single-Pixel Vision-Language Model (SP-VLM), a novel framework that reimagines secure environmental monitoring. It achieves intrinsic privacy-by-design by capturing human dynamics through inherently low-dimensional single-pixel modalities and inferring complex behavioral patterns via seamless vision-language integration. Building on this framework, we demonstrate that single-pixel sensing intrinsically suppresses identity recoverability, rendering state-of-the-art face recognition systems ineffective below a critical sampling rate. We further show that SP-VLM can nonetheless extract meaningful behavioral semantics, enabling robust anomaly detection, people counting, and activity understanding from severely degraded single-pixel observations. Combining these findings, we identify a practical sampling-rate regime in which behavioral intelligence emerges while personal identity remains strongly protected. Together, these results point to a human-rights-aligned pathway for safety monitoring that can support timely intervention without normalizing intrusive surveillance in privacy-sensitive spaces.
S$^3$IT: A Benchmark for Spatially Situated Social Intelligence Test
Dec 23, 2025
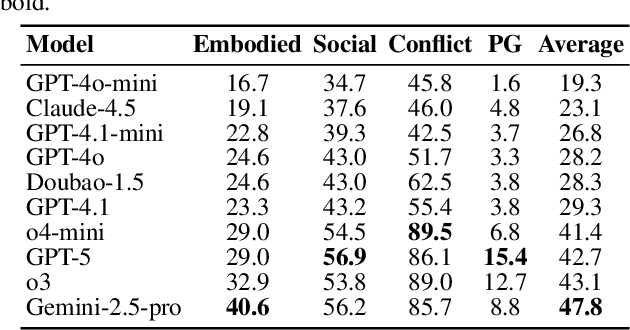
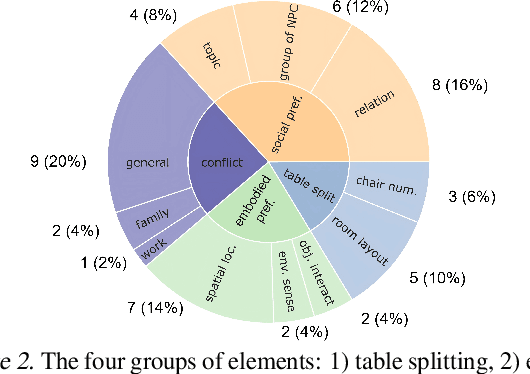

The integration of embodied agents into human environments demands embodied social intelligence: reasoning over both social norms and physical constraints. However, existing evaluations fail to address this integration, as they are limited to either disembodied social reasoning (e.g., in text) or socially-agnostic physical tasks. Both approaches fail to assess an agent's ability to integrate and trade off both physical and social constraints within a realistic, embodied context. To address this challenge, we introduce Spatially Situated Social Intelligence Test (S$^{3}$IT), a benchmark specifically designed to evaluate embodied social intelligence. It is centered on a novel and challenging seat-ordering task, requiring an agent to arrange seating in a 3D environment for a group of large language model-driven (LLM-driven) NPCs with diverse identities, preferences, and intricate interpersonal relationships. Our procedurally extensible framework generates a vast and diverse scenario space with controllable difficulty, compelling the agent to acquire preferences through active dialogue, perceive the environment via autonomous exploration, and perform multi-objective optimization within a complex constraint network. We evaluate state-of-the-art LLMs on S$^{3}$IT and found that they still struggle with this problem, showing an obvious gap compared with the human baseline. Results imply that LLMs have deficiencies in spatial intelligence, yet simultaneously demonstrate their ability to achieve near human-level competence in resolving conflicts that possess explicit textual cues.
TongSIM: A General Platform for Simulating Intelligent Machines
Dec 23, 2025As artificial intelligence (AI) rapidly advances, especially in multimodal large language models (MLLMs), research focus is shifting from single-modality text processing to the more complex domains of multimodal and embodied AI. Embodied intelligence focuses on training agents within realistic simulated environments, leveraging physical interaction and action feedback rather than conventionally labeled datasets. Yet, most existing simulation platforms remain narrowly designed, each tailored to specific tasks. A versatile, general-purpose training environment that can support everything from low-level embodied navigation to high-level composite activities, such as multi-agent social simulation and human-AI collaboration, remains largely unavailable. To bridge this gap, we introduce TongSIM, a high-fidelity, general-purpose platform for training and evaluating embodied agents. TongSIM offers practical advantages by providing over 100 diverse, multi-room indoor scenarios as well as an open-ended, interaction-rich outdoor town simulation, ensuring broad applicability across research needs. Its comprehensive evaluation framework and benchmarks enable precise assessment of agent capabilities, such as perception, cognition, decision-making, human-robot cooperation, and spatial and social reasoning. With features like customized scenes, task-adaptive fidelity, diverse agent types, and dynamic environmental simulation, TongSIM delivers flexibility and scalability for researchers, serving as a unified platform that accelerates training, evaluation, and advancement toward general embodied intelligence.
A Generative Data Framework with Authentic Supervision for Underwater Image Restoration and Enhancement
Nov 18, 2025Underwater image restoration and enhancement are crucial for correcting color distortion and restoring image details, thereby establishing a fundamental basis for subsequent underwater visual tasks. However, current deep learning methodologies in this area are frequently constrained by the scarcity of high-quality paired datasets. Since it is difficult to obtain pristine reference labels in underwater scenes, existing benchmarks often rely on manually selected results from enhancement algorithms, providing debatable reference images that lack globally consistent color and authentic supervision. This limits the model's capabilities in color restoration, image enhancement, and generalization. To overcome this limitation, we propose using in-air natural images as unambiguous reference targets and translating them into underwater-degraded versions, thereby constructing synthetic datasets that provide authentic supervision signals for model learning. Specifically, we establish a generative data framework based on unpaired image-to-image translation, producing a large-scale dataset that covers 6 representative underwater degradation types. The framework constructs synthetic datasets with precise ground-truth labels, which facilitate the learning of an accurate mapping from degraded underwater images to their pristine scene appearances. Extensive quantitative and qualitative experiments across 6 representative network architectures and 3 independent test sets show that models trained on our synthetic data achieve comparable or superior color restoration and generalization performance to those trained on existing benchmarks. This research provides a reliable and scalable data-driven solution for underwater image restoration and enhancement. The generated dataset is publicly available at: https://github.com/yftian2025/SynUIEDatasets.git.