 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoGrasp: World-Space Hand-Object Interaction Estimation from Egocentric Videos
Jan 03, 2026We propose EgoGrasp, the first method to reconstruct world-space hand-object interactions (W-HOI) from egocentric monocular videos with dynamic cameras in the wild. Accurate W-HOI reconstruction is critical for understanding human behavior and enabling applications in embodied intelligence and virtual reality. However, existing hand-object interactions (HOI) methods are limited to single images or camera coordinates, failing to model temporal dynamics or consistent global trajectories. Some recent approaches attempt world-space hand estimation but overlook object poses and HOI constraints. Their performance also suffers under severe camera motion and frequent occlusions common in egocentric in-the-wild videos. To address these challenges, we introduce a multi-stage framework with a robust pre-process pipeline built on newly developed spatial intelligence models, a whole-body HOI prior model based on decoupled diffusion models, and a multi-objective test-time optimization paradigm. Our HOI prior model is template-free and scalable to multiple objects. In experiments, we prove our method achieving state-of-the-art performance in W-HOI reconstruction.
DeCo-VAE: Learning Compact Latents for Video Reconstruction via Decoupled Representation
Nov 18, 2025Existing video Variational Autoencoders (VAEs) generally overlook the similarity between frame contents, leading to redundant latent modeling. In this paper, we propose decoupled VAE (DeCo-VAE) to achieve compact latent representation. Instead of encoding RGB pixels directly, we decompose video content into distinct components via explicit decoupling: keyframe, motion and residual, and learn dedicated latent representation for each. To avoid cross-component interference, we design dedicated encoders for each decoupled component and adopt a shared 3D decoder to maintain spatiotemporal consistency during reconstruction. We further utilize a decoupled adaptation strategy that freezes partial encoders while training the others sequentially, ensuring stable training and accurate learning of both static and dynamic features. Extensive quantitative and qualitative experiments demonstrate that DeCo-VAE achieves superior video reconstruction performance.
Class-Aware Prototype Learning with Negative Contrast for Test-Time Adaptation of Vision-Language Models
Oct 22, 2025Vision-Language Models (VLMs) demonstrate impressive zero-shot generalization through large-scale image-text pretraining, yet their performance can drop once the deployment distribution diverges from the training distribution. To address this, Test-Time Adaptation (TTA) methods update models using unlabeled target data. However, existing approaches often ignore two key challenges: prototype degradation in long-tailed distributions and confusion between semantically similar classes. To tackle these issues, we propose \textbf{C}lass-Aware \textbf{P}rototype \textbf{L}earning with \textbf{N}egative \textbf{C}ontrast(\textbf{CPL-NC}), a lightweight TTA framework designed specifically for VLMs to enhance generalization under distribution shifts. CPL-NC introduces a \textit{Class-Aware Prototype Cache} Module that dynamically adjusts per-class capacity based on test-time frequency and activation history, with a rejuvenation mechanism for inactive classes to retain rare-category knowledge. Additionally, a \textit{Negative Contrastive Learning} Mechanism identifies and constrains hard visual-textual negatives to improve class separability. The framework employs asymmetric optimization, refining only textual prototypes while anchoring on stable visual features. Experiments on 15 benchmarks show that CPL-NC consistently outperforms prior TTA methods across both ResNet-50 and ViT-B/16 backbones.
Bridging Perception and Planning: Towards End-to-End Planning for Signal Temporal Logic Tasks
Sep 16, 2025We investigate the task and motion planning problem for Signal Temporal Logic (STL) specifications in robotics. Existing STL methods rely on pre-defined maps or mobility representations, which are ineffective in unstructured real-world environments. We propose the \emph{Structured-MoE STL Planner} (\textbf{S-MSP}), a differentiable framework that maps synchronized multi-view camera observations and an STL specification directly to a feasible trajectory. S-MSP integrates STL constraints within a unified pipeline, trained with a composite loss that combines trajectory reconstruction and STL robustness. A \emph{structure-aware} Mixture-of-Experts (MoE) model enables horizon-aware specialization by projecting sub-tasks into temporally anchored embeddings. We evaluate S-MSP using a high-fidelity simulation of factory-logistics scenarios with temporally constrained tasks. Experiments show that S-MSP outperforms single-expert baselines in STL satisfaction and trajectory feasibility. A rule-based \emph{safety filter} at inference improves physical executability without compromising logical correctness, showcasing the practicality of the approach.
Bidirectional Prototype-Reward co-Evolution for Test-Time Adaptation of Vision-Language Models
Mar 12, 2025Test-time adaptation (TTA) is crucial in maintaining Vision-Language Models (VLMs) performance when facing real-world distribution shifts, particularly when the source data or target labels are inaccessible. Existing TTA methods rely on CLIP's output probability distribution for feature evaluation, which can introduce biases under domain shifts. This misalignment may cause features to be misclassified due to text priors or incorrect textual associations. To address these limitations, we propose Bidirectional Prototype-Reward co-Evolution (BPRE), a novel TTA framework for VLMs that integrates feature quality assessment with prototype evolution through a synergistic feedback loop. BPRE first employs a Multi-Dimensional Quality-Aware Reward Module to evaluate feature quality and guide prototype refinement precisely. The continuous refinement of prototype quality through Prototype-Reward Interactive Evolution will subsequently enhance the computation of more robust Multi-Dimensional Quality-Aware Reward Scores. Through the bidirectional interaction, the precision of rewards and the evolution of prototypes mutually reinforce each other, forming a self-evolving cycle. Extensive experiments are conducted across 15 diverse recognition datasets encompassing natural distribution shifts and cross-dataset generalization scenarios. Results demonstrate that BPRE consistently achieves superior average performance compared to state-of-the-art methods across different model architectures, such as ResNet-50 and ViT-B/16. By emphasizing comprehensive feature evaluation and bidirectional knowledge refinement, BPRE advances VLM generalization capabilities, offering a new perspective on TTA.
ComKD-CLIP: Comprehensive Knowledge Distillation for Contrastive Language-Image Pre-traning Model
Aug 08, 2024Contrastive Language-Image Pre-training (CLIP) excels in integrating semantic information between images and text through contrastive learning techniques. It has achieved remarkable performance in various multimodal tasks. However, the deployment of large CLIP models is hindered in resource-limited environments, while smaller models frequently fall short of meeting performance benchmarks necessary for practical applications. In this paper, we propose a novel approach, coined as ComKD-CLIP: Comprehensive Knowledge Distillation for Contrastive Language-Image Pre-traning Model, which aims to comprehensively distill the knowledge from a large teacher CLIP model into a smaller student model, ensuring comparable performance with significantly reduced parameters. ComKD-CLIP is composed of two key mechanisms: Image Feature Alignment (IFAlign) and Educational Attention (EduAttention). IFAlign makes the image features extracted by the student model closely match those extracted by the teacher model, enabling the student to learn teacher's knowledge of extracting image features. EduAttention explores the cross-relationships between text features extracted by the teacher model and image features extracted by the student model, enabling the student model to learn how the teacher model integrates text-image features. In addition, ComKD-CLIP can refine the knowledge distilled from IFAlign and EduAttention leveraging the results of text-image feature fusion by the teacher model, ensuring student model accurately absorbs the knowledge of teacher model. Extensive experiments conducted on 11 datasets have demonstrated the superiority of the proposed method.
CREST: Cross-modal Resonance through Evidential Deep Learning for Enhanced Zero-Shot Learning
Apr 15, 2024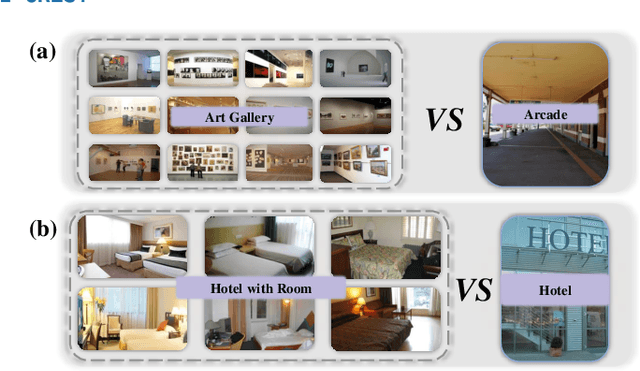



Zero-shot learning (ZSL) enables the recognition of novel classes by leveraging semantic knowledge transfer from known to unknown categories. This knowledge, typically encapsulated in attribute descriptions, aids in identifying class-specific visual features, thus facilitating visual-semantic alignment and improving ZSL performance. However, real-world challenges such as distribution imbalances and attribute co-occurrence among instances often hinder the discernment of local variances in images, a problem exacerbated by the scarcity of fine-grained, region-specific attribute annotations. Moreover, the variability in visual presentation within categories can also skew attribute-category associations. In response, we propose a bidirectional cross-modal ZSL approach CREST. It begins by extracting representations for attribute and visual localization and employs Evidential Deep Learning (EDL) to measure underlying epistemic uncertainty, thereby enhancing the model's resilience against hard negatives. CREST incorporates dual learning pathways, focusing on both visual-category and attribute-category alignments, to ensure robust correlation between latent and observable spaces. Moreover, we introduce an uncertainty-informed cross-modal fusion technique to refine visual-attribute inference. Extensive experiments demonstrate our model's effectiveness and unique explainability across multiple datasets. Our code and data are available at: Comments: Ongoing work; 10 pages, 2 Tables, 9 Figures; Repo is available at https://github.com/JethroJames/CREST.