 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbitrarily-high-dimensional reconciliation via cross-rotation for continuous-variable quantum key distribution
Aug 08, 2025Multidimensional rotation serves as a powerful tool for enhancing information reconciliation and extending the transmission distance in continuous-variable quantum key distribution (CV-QKD). However, the lack of closed-form orthogonal transformations for high-dimensional rotations has limited the maximum reconciliation efficiency to channels with 8 dimensions over the past decade. This paper presents a cross-rotation scheme to overcome this limitation and enable reconciliation in arbitrarily high dimensions, constrained to even multiples of 8. The key treatment involves reshaping the string vector into matrix form and applying orthogonal transformations to its columns and rows in a cross manner, thereby increasing the reconciliation dimension by one order per cross-rotation while significantly reducing the communication overhead over the classical channel. A rigorous performance analysis is also presented from the perspective of achievable sum-rate. Simulation results demonstrate that 64-dimensional cross-rotation nearly approaches the upper bound, making it a recommended choice for practical implementations.
Joint parameter estimation and multidimensional reconciliation for CV-QKD
Aug 07, 2025Accurate quantum channel parameter estimation is essential for effective information reconciliation in continuous-variable quantum key distribution (CV-QKD). However, conventional maximum likelihood (ML) estimators rely on a large amount of discarded data (or pilot symbols), leading to a significant loss in symbol efficiency. Moreover, the separation between the estimation and reconciliation phases can introduce error propagation. In this paper, we propose a novel joint message-passing scheme that unifies channel parameter estimation and information reconciliation within a Bayesian framework. By leveraging the expectation-maximization (EM) algorithm, the proposed method simultaneously estimates unknown parameters during decoding, eliminating the need for separate ML estimation. Furthermore, we introduce a hybrid multidimensional rotation scheme that removes the requirement for norm feedback, significantly reducing classical channel overhead. To the best of our knowledge, this is the first work to unify multidimensional reconciliation and channel parameter estimation in CV-QKD, providing a practical solution for high-efficiency reconciliation with minimal pilots.
Towards Energy-Efficient and Low-Latency Voice-Controlled Smart Homes: A Proposal for Offline Speech Recognition and IoT Integration
Jun 09, 2025The smart home systems, based on AI speech recognition and IoT technology, enable people to control devices through verbal commands and make people's lives more efficient. However, existing AI speech recognition services are primarily deployed on cloud platforms on the Internet. When users issue a command, speech recognition devices like ``Amazon Echo'' will post a recording through numerous network nodes, reach multiple servers, and then receive responses through the Internet. This mechanism presents several issues, including unnecessary energy consumption, communication latency, and the risk of a single-point failure. In this position paper, we propose a smart home concept based on offline speech recognition and IoT technology: 1) integrating offline keyword spotting (KWS) technologies into household appliances with limited resource hardware to enable them to understand user voice commands; 2) designing a local IoT network with decentralized architecture to manage and connect various devices, enhancing the robustness and scalability of the system. This proposal of a smart home based on offline speech recognition and IoT technology will allow users to use low-latency voice control anywhere in the home without depending on the Internet and provide better scalability and energy sustainability.
Bidirectional Prototype-Reward co-Evolution for Test-Time Adaptation of Vision-Language Models
Mar 12, 2025Test-time adaptation (TTA) is crucial in maintaining Vision-Language Models (VLMs) performance when facing real-world distribution shifts, particularly when the source data or target labels are inaccessible. Existing TTA methods rely on CLIP's output probability distribution for feature evaluation, which can introduce biases under domain shifts. This misalignment may cause features to be misclassified due to text priors or incorrect textual associations. To address these limitations, we propose Bidirectional Prototype-Reward co-Evolution (BPRE), a novel TTA framework for VLMs that integrates feature quality assessment with prototype evolution through a synergistic feedback loop. BPRE first employs a Multi-Dimensional Quality-Aware Reward Module to evaluate feature quality and guide prototype refinement precisely. The continuous refinement of prototype quality through Prototype-Reward Interactive Evolution will subsequently enhance the computation of more robust Multi-Dimensional Quality-Aware Reward Scores. Through the bidirectional interaction, the precision of rewards and the evolution of prototypes mutually reinforce each other, forming a self-evolving cycle. Extensive experiments are conducted across 15 diverse recognition datasets encompassing natural distribution shifts and cross-dataset generalization scenarios. Results demonstrate that BPRE consistently achieves superior average performance compared to state-of-the-art methods across different model architectures, such as ResNet-50 and ViT-B/16. By emphasizing comprehensive feature evaluation and bidirectional knowledge refinement, BPRE advances VLM generalization capabilities, offering a new perspective on TTA.
Variable-frame CNNLSTM for Breast Nodule Classification using Ultrasound Videos
Feb 17, 2025



The intersection of medical imaging and artificial intelligence has become an important research direction in intelligent medical treatment, particularly in the analysis of medical images using deep learning for clinical diagnosis. Despite the advances, existing keyframe classification methods lack extraction of time series features, while ultrasonic video classification based on three-dimensional convolution requires uniform frame numbers across patients, resulting in poor feature extraction efficiency and model classification performance. This study proposes a novel video classification method based on CNN and LSTM, introducing NLP's long and short sentence processing scheme into video classification for the first time. The method reduces CNN-extracted image features to 1x512 dimension, followed by sorting and compressing feature vectors for LSTM training. Specifically, feature vectors are sorted by patient video frame numbers and populated with padding value 0 to form variable batches, with invalid padding values compressed before LSTM training to conserve computing resources. Experimental results demonstrate that our variable-frame CNNLSTM method outperforms other approaches across all metrics, showing improvements of 3-6% in F1 score and 1.5% in specificity compared to keyframe methods. The variable-frame CNNLSTM also achieves better accuracy and precision than equal-frame CNNLSTM. These findings validate the effectiveness of our approach in classifying variable-frame ultrasound videos and suggest potential applications in other medical imaging modalities.
Diff-CXR: Report-to-CXR generation through a disease-knowledge enhanced diffusion model
Oct 26, 2024Text-To-Image (TTI) generation is significant for controlled and diverse image generation with broad potential applications. Although current medical TTI methods have made some progress in report-to-Chest-Xray (CXR) generation, their generation performance may be limited due to the intrinsic characteristics of medical data. In this paper, we propose a novel disease-knowledge enhanced Diffusion-based TTI learning framework, named Diff-CXR, for medical report-to-CXR generation. First, to minimize the negative impacts of noisy data on generation, we devise a Latent Noise Filtering Strategy that gradually learns the general patterns of anomalies and removes them in the latent space. Then, an Adaptive Vision-Aware Textual Learning Strategy is designed to learn concise and important report embeddings in a domain-specific Vision-Language Model, providing textual guidance for Chest-Xray generation. Finally, by incorporating the general disease knowledge into the pretrained TTI model via a delicate control adapter, a disease-knowledge enhanced diffusion model is introduced to achieve realistic and precise report-to-CXR generation. Experimentally, our Diff-CXR outperforms previous SOTA medical TTI methods by 33.4\% / 8.0\% and 23.8\% / 56.4\% in the FID and mAUC score on MIMIC-CXR and IU-Xray, with the lowest computational complexity at 29.641 GFLOPs. Downstream experiments on three thorax disease classification benchmarks and one CXR-report generation benchmark demonstrate that Diff-CXR is effective in improving classical CXR analysis methods. Notably, models trained on the combination of 1\% real data and synthetic data can achieve a competitive mAUC score compared to models trained on all data, presenting promising clinical applications.
GaussianPU: A Hybrid 2D-3D Upsampling Framework for Enhancing Color Point Clouds via 3D Gaussian Splatting
Sep 03, 2024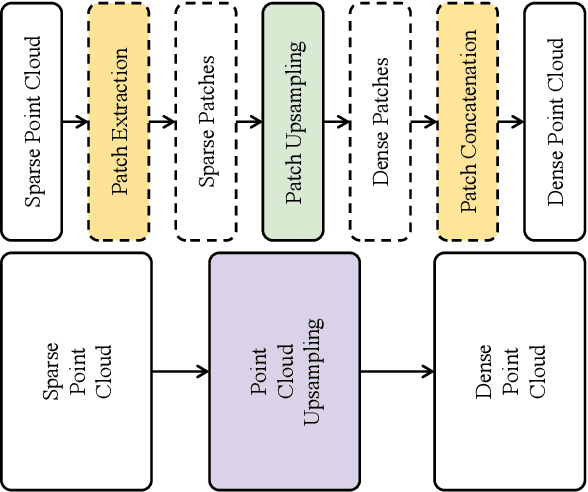
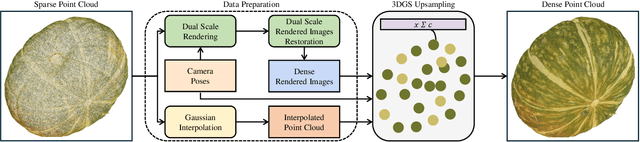


Dense colored point clouds enhance visual perception and are of significant value in various robotic applications. However, existing learning-based point cloud upsampling methods are constrained by computational resources and batch processing strategies, which often require subdividing point clouds into smaller patches, leading to distortions that degrade perceptual quality. To address this challenge, we propose a novel 2D-3D hybrid colored point cloud upsampling framework (GaussianPU) based on 3D Gaussian Splatting (3DGS) for robotic perception. This approach leverages 3DGS to bridge 3D point clouds with their 2D rendered images in robot vision systems. A dual scale rendered image restoration network transforms sparse point cloud renderings into dense representations, which are then input into 3DGS along with precise robot camera poses and interpolated sparse point clouds to reconstruct dense 3D point clouds. We have made a series of enhancements to the vanilla 3DGS, enabling precise control over the number of points and significantly boosting the quality of the upsampled point cloud for robotic scene understanding. Our framework supports processing entire point clouds on a single consumer-grade GPU, such as the NVIDIA GeForce RTX 3090, eliminating the need for segmentation and thus producing high-quality, dense colored point clouds with millions of points for robot navigation and manipulation tasks. Extensive experimental results on generating million-level point cloud data validate the effectiveness of our method, substantially improving the quality of colored point clouds and demonstrating significant potential for applications involving large-scale point clouds in autonomous robotics and human-robot interaction scenarios.
An Explainable Non-local Network for COVID-19 Diagnosis
Aug 08, 2024The CNN has achieved excellent results in the automatic classification of medical images. In this study, we propose a novel deep residual 3D attention non-local network (NL-RAN) to classify CT images included COVID-19, common pneumonia, and normal to perform rapid and explainable COVID-19 diagnosis. We built a deep residual 3D attention non-local network that could achieve end-to-end training. The network is embedded with a nonlocal module to capture global information, while a 3D attention module is embedded to focus on the details of the lesion so that it can directly analyze the 3D lung CT and output the classification results. The output of the attention module can be used as a heat map to increase the interpretability of the model. 4079 3D CT scans were included in this study. Each scan had a unique label (novel coronavirus pneumonia, common pneumonia, and normal). The CT scans cohort was randomly split into a training set of 3263 scans, a validation set of 408 scans, and a testing set of 408 scans. And compare with existing mainstream classification methods, such as CovNet, CBAM, ResNet, etc. Simultaneously compare the visualization results with visualization methods such as CAM. Model performance was evaluated using the Area Under the ROC Curve(AUC), precision, and F1-score. The NL-RAN achieved the AUC of 0.9903, the precision of 0.9473, and the F1-score of 0.9462, surpass all the classification methods compared. The heat map output by the attention module is also clearer than the heat map output by CAM. Our experimental results indicate that our proposed method performs significantly better than existing methods. In addition, the first attention module outputs a heat map containing detailed outline information to increase the interpretability of the model. Our experiments indicate that the inference of our model is fast. It can provide real-time assistance with diagnosis.
ALIF: Low-Cost Adversarial Audio Attacks on Black-Box Speech Platforms using Linguistic Features
Aug 03, 2024Extensive research has revealed that adversarial examples (AE) pose a significant threat to voice-controllable smart devices. Recent studies have proposed black-box adversarial attacks that require only the final transcription from an automatic speech recognition (ASR) system. However, these attacks typically involve many queries to the ASR, resulting in substantial costs. Moreover, AE-based adversarial audio samples are susceptible to ASR updates. In this paper, we identify the root cause of these limitations, namely the inability to construct AE attack samples directly around the decision boundary of deep learning (DL) models. Building on this observation, we propose ALIF, the first black-box adversarial linguistic feature-based attack pipeline. We leverage the reciprocal process of text-to-speech (TTS) and ASR models to generate perturbations in the linguistic embedding space where the decision boundary resides. Based on the ALIF pipeline, we present the ALIF-OTL and ALIF-OTA schemes for launching attacks in both the digital domain and the physical playback environment on four commercial ASRs and voice assistants. Extensive evaluations demonstrate that ALIF-OTL and -OTA significantly improve query efficiency by 97.7% and 73.3%, respectively, while achieving competitive performance compared to existing methods. Notably, ALIF-OTL can generate an attack sample with only one query. Furthermore, our test-of-time experiment validates the robustness of our approach against ASR updates.
U-MedSAM: Uncertainty-aware MedSAM for Medical Image Segmentation
Aug 03, 2024



Medical Image Foundation Models have proven to be powerful tools for mask prediction across various datasets. However, accurately assessing the uncertainty of their predictions remains a significant challenge. To address this, we propose a new model, U-MedSAM, which integrates the MedSAM model with an uncertainty-aware loss function and the Sharpness-Aware Minimization (SharpMin) optimizer. The uncertainty-aware loss function automatically combines region-based, distribution-based, and pixel-based loss designs to enhance segmentation accuracy and robustness. SharpMin improves generalization by finding flat minima in the loss landscape, thereby reducing overfitting. Our method was evaluated in the CVPR24 MedSAM on Laptop challenge, where U-MedSAM demonstrated promising performance.