 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
RadioDiff-FS: Physics-Informed Manifold Alignment in Few-Shot Diffusion Models for High-Fidelity Radio Map Construction
Mar 19, 2026Radio maps (RMs) provide spatially continuous propagation characterizations essential for 6G network planning, but high-fidelity RM construction remains challenging. Rigorous electromagnetic solvers incur prohibitive computational latency, while data-driven models demand massive labeled datasets and generalize poorly from simplified simulations to complex multipath environments. This paper proposes RadioDiff-FS, a few-shot diffusion framework that adapts a pre-trained main-path generator to multipath-rich target domains with only a small number of high-fidelity samples. The adaptation is grounded in a theoretical decomposition of the multipath RM into a dominant main-path component and a directionally sparse residual. This decomposition shows that the cross-domain shift corresponds to a bounded and geometrically structured feature translation rather than an arbitrary distribution change. A Direction-Consistency Loss (DCL) is then introduced to constrain diffusion score updates along physically plausible propagation directions, suppressing phase-inconsistent artifacts that arise in the low-data regime. Experiments show that RadioDiff-FS reduces NMSE by 59.5% on static RMs and by 74.0% on dynamic RMs relative to the vanilla diffusion baseline, achieving an SSIM of 0.9752 and a PSNR of 36.37 dB under severely limited supervision.
Tilt-Ropter: A Novel Hybrid Aerial and Terrestrial Vehicle with Tilt Rotors and Passive Wheels
Feb 02, 2026In this work, we present Tilt-Ropter, a novel hybrid aerial-terrestrial vehicle (HATV) that combines tilt rotors with passive wheels to achieve energy-efficient multi-mode locomotion. Unlike existing under-actuated HATVs, the fully actuated design of Tilt-Ropter enables decoupled force and torque control, greatly enhancing its mobility and environmental adaptability. A nonlinear model predictive controller (NMPC) is developed to track reference trajectories and handle contact constraints across locomotion modes, while a dedicated control allocation module exploits actuation redundancy to achieve energy-efficient control of actuators. Additionally, to enhance robustness during ground contact, we introduce an external wrench estimation algorithm that estimates environmental interaction forces and torques in real time. The system is validated through both simulation and real-world experiments, including seamless air-ground transitions and trajectory tracking. Results show low tracking errors in both modes and highlight a 92.8% reduction in power consumption during ground locomotion, demonstrating the system's potential for long-duration missions across large-scale and energy-constrained environments.
Time of the Flight of the Gaussians: Optimizing Depth Indirectly in Dynamic Radiance Fields
May 08, 2025We present a method to reconstruct dynamic scenes from monocular continuous-wave time-of-flight (C-ToF) cameras using raw sensor samples that achieves similar or better accuracy than neural volumetric approaches and is 100x faster. Quickly achieving high-fidelity dynamic 3D reconstruction from a single viewpoint is a significant challenge in computer vision. In C-ToF radiance field reconstruction, the property of interest-depth-is not directly measured, causing an additional challenge. This problem has a large and underappreciated impact upon the optimization when using a fast primitive-based scene representation like 3D Gaussian splatting, which is commonly used with multi-view data to produce satisfactory results and is brittle in its optimization otherwise. We incorporate two heuristics into the optimization to improve the accuracy of scene geometry represented by Gaussians. Experimental results show that our approach produces accurate reconstructions under constrained C-ToF sensing conditions, including for fast motions like swinging baseball bats. https://visual.cs.brown.edu/gftorf
PointTalk: Audio-Driven Dynamic Lip Point Cloud for 3D Gaussian-based Talking Head Synthesis
Dec 11, 2024



Talking head synthesis with arbitrary speech audio is a crucial challenge in the field of digital humans. Recently, methods based on radiance fields have received increasing attention due to their ability to synthesize high-fidelity and identity-consistent talking heads from just a few minutes of training video. However, due to the limited scale of the training data, these methods often exhibit poor performance in audio-lip synchronization and visual quality. In this paper, we propose a novel 3D Gaussian-based method called PointTalk, which constructs a static 3D Gaussian field of the head and deforms it in sync with the audio. It also incorporates an audio-driven dynamic lip point cloud as a critical component of the conditional information, thereby facilitating the effective synthesis of talking heads. Specifically, the initial step involves generating the corresponding lip point cloud from the audio signal and capturing its topological structure. The design of the dynamic difference encoder aims to capture the subtle nuances inherent in dynamic lip movements more effectively. Furthermore, we integrate the audio-point enhancement module, which not only ensures the synchronization of the audio signal with the corresponding lip point cloud within the feature space, but also facilitates a deeper understanding of the interrelations among cross-modal conditional features. Extensive experiments demonstrate that our method achieves superior high-fidelity and audio-lip synchronization in talking head synthesis compared to previous methods.
D$^2$-World: An Efficient World Model through Decoupled Dynamic Flow
Nov 26, 2024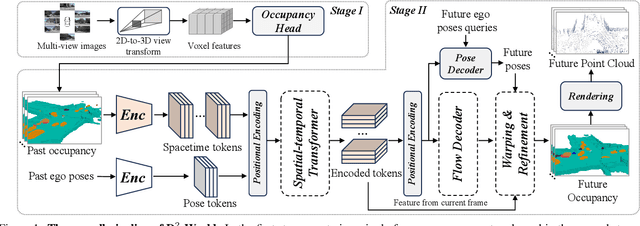
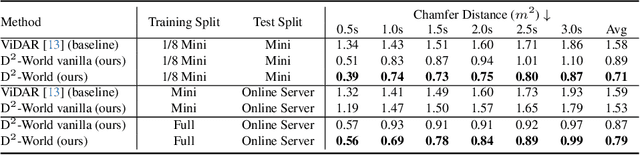
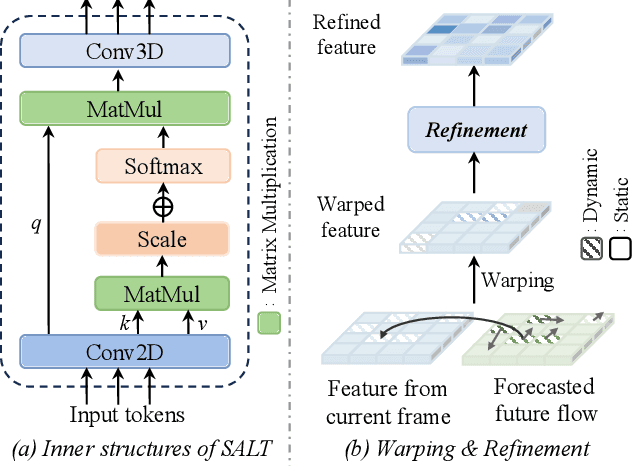
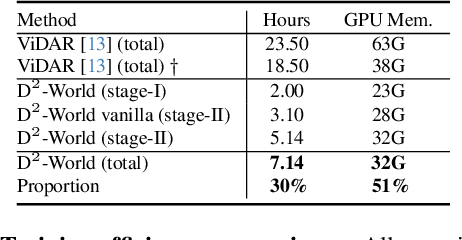
This technical report summarizes the second-place solution for the Predictive World Model Challenge held at the CVPR-2024 Workshop on Foundation Models for Autonomous Systems. We introduce D$^2$-World, a novel World model that effectively forecasts future point clouds through Decoupled Dynamic flow. Specifically, the past semantic occupancies are obtained via existing occupancy networks (e.g., BEVDet). Following this, the occupancy results serve as the input for a single-stage world model, generating future occupancy in a non-autoregressive manner. To further simplify the task, dynamic voxel decoupling is performed in the world model. The model generates future dynamic voxels by warping the existing observations through voxel flow, while remaining static voxels can be easily obtained through pose transformation. As a result, our approach achieves state-of-the-art performance on the OpenScene Predictive World Model benchmark, securing second place, and trains more than 300% faster than the baseline model. Code is available at https://github.com/zhanghm1995/D2-World.
GaussianPU: A Hybrid 2D-3D Upsampling Framework for Enhancing Color Point Clouds via 3D Gaussian Splatting
Sep 03, 2024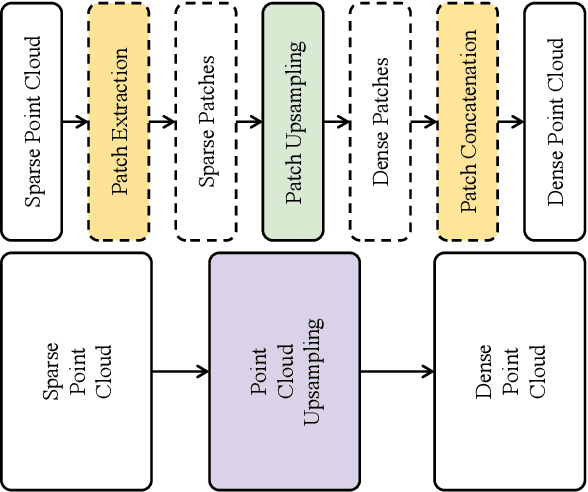
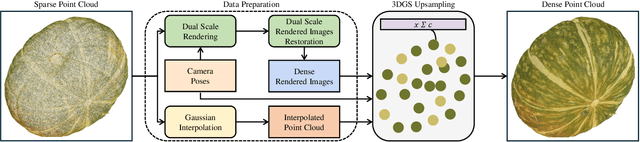


Dense colored point clouds enhance visual perception and are of significant value in various robotic applications. However, existing learning-based point cloud upsampling methods are constrained by computational resources and batch processing strategies, which often require subdividing point clouds into smaller patches, leading to distortions that degrade perceptual quality. To address this challenge, we propose a novel 2D-3D hybrid colored point cloud upsampling framework (GaussianPU) based on 3D Gaussian Splatting (3DGS) for robotic perception. This approach leverages 3DGS to bridge 3D point clouds with their 2D rendered images in robot vision systems. A dual scale rendered image restoration network transforms sparse point cloud renderings into dense representations, which are then input into 3DGS along with precise robot camera poses and interpolated sparse point clouds to reconstruct dense 3D point clouds. We have made a series of enhancements to the vanilla 3DGS, enabling precise control over the number of points and significantly boosting the quality of the upsampled point cloud for robotic scene understanding. Our framework supports processing entire point clouds on a single consumer-grade GPU, such as the NVIDIA GeForce RTX 3090, eliminating the need for segmentation and thus producing high-quality, dense colored point clouds with millions of points for robot navigation and manipulation tasks. Extensive experimental results on generating million-level point cloud data validate the effectiveness of our method, substantially improving the quality of colored point clouds and demonstrating significant potential for applications involving large-scale point clouds in autonomous robotics and human-robot interaction scenarios.
Uncertainty-aware No-Reference Point Cloud Quality Assessment
Jan 17, 2024
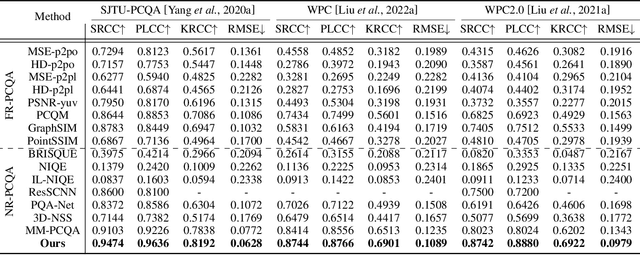

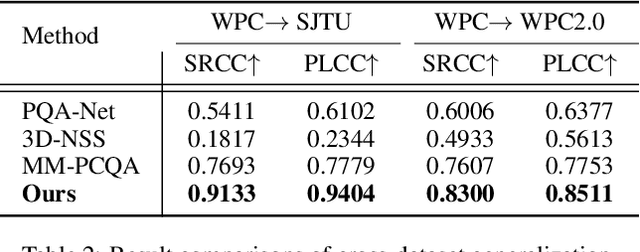
The evolution of compression and enhancement algorithms necessitates an accurate quality assessment for point clouds. Previous works consistently regard point cloud quality assessment (PCQA) as a MOS regression problem and devise a deterministic mapping, ignoring the stochasticity in generating MOS from subjective tests. Besides, the viewpoint switching of 3D point clouds in subjective tests reinforces the judging stochasticity of different subjects compared with traditional images. This work presents the first probabilistic architecture for no-reference PCQA, motivated by the labeling process of existing datasets. The proposed method can model the quality judging stochasticity of subjects through a tailored conditional variational autoencoder (CVAE) and produces multiple intermediate quality ratings. These intermediate ratings simulate the judgments from different subjects and are then integrated into an accurate quality prediction, mimicking the generation process of a ground truth MOS. Specifically, our method incorporates a Prior Module, a Posterior Module, and a Quality Rating Generator, where the former two modules are introduced to model the judging stochasticity in subjective tests, while the latter is developed to generate diverse quality ratings. Extensive experiments indicate that our approach outperforms previous cutting-edge methods by a large margin and exhibits gratifying cross-dataset robustness.
Air Bumper: A Collision Detection and Reaction Framework for Autonomous MAV Navigation
Jul 12, 2023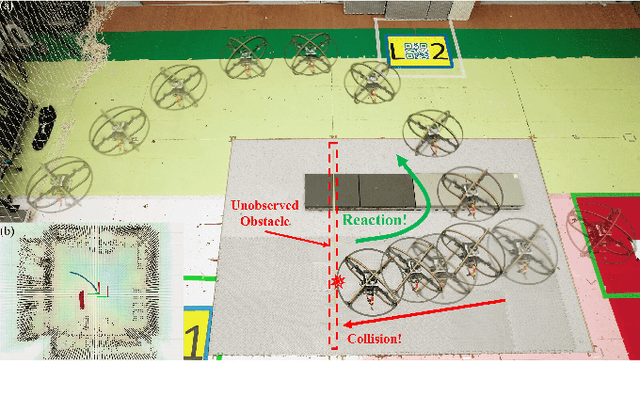
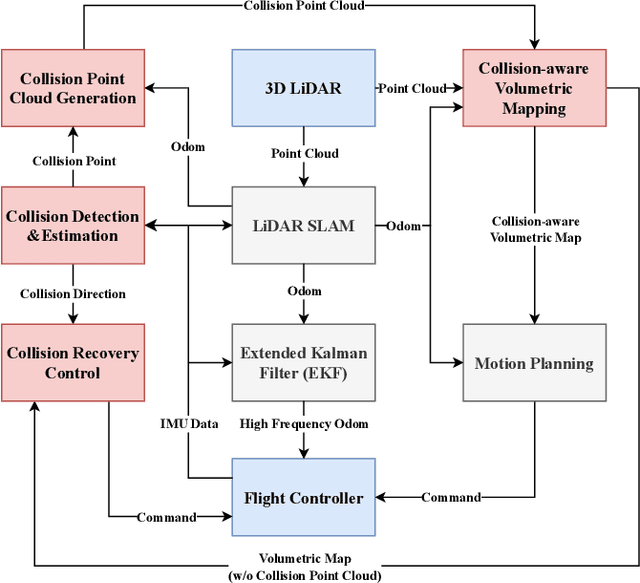
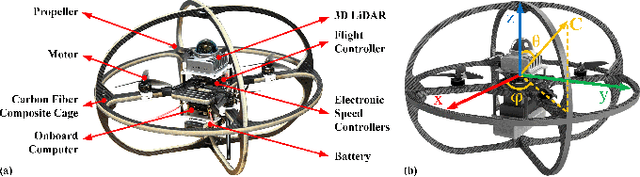

Autonomous navigation in unknown environments with obstacles remains challenging for micro aerial vehicles (MAVs) due to their limited onboard computing and sensing resources. Although various collision avoidance methods have been developed, it is still possible for drones to collide with unobserved obstacles due to unpredictable disturbances, sensor limitations, and control uncertainty. Instead of completely avoiding collisions, this article proposes Air Bumper, a collision detection and reaction framework, for fully autonomous flight in 3D environments to improve the safety of drones. Our framework only utilizes the onboard inertial measurement unit (IMU) to detect and estimate collisions. We further design a collision recovery control for rapid recovery and collision-aware mapping to integrate collision information into general LiDAR-based sensing and planning frameworks. Our simulation and experimental results show that the quadrotor can rapidly detect, estimate, and recover from collisions with obstacles in 3D space and continue the flight smoothly with the help of the collision-aware map.
Improved Point Transformation Methods For Self-Supervised Depth Prediction
Feb 18, 2021
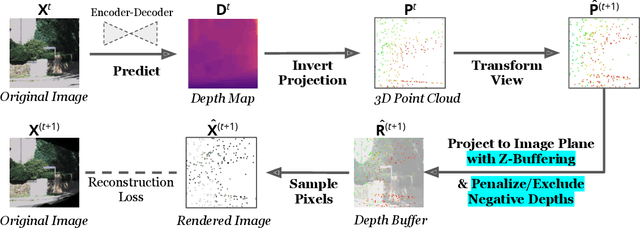
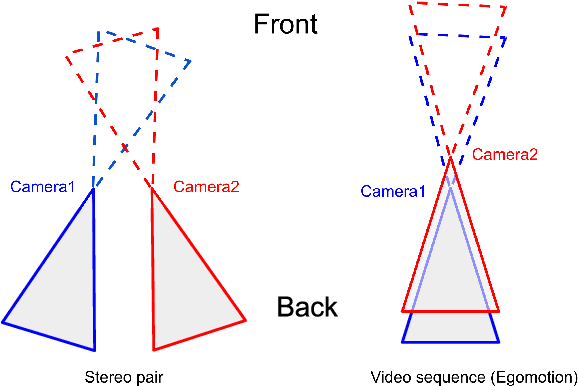
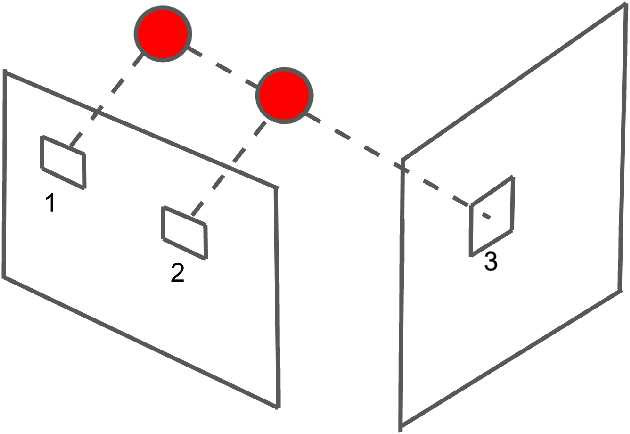
Given stereo or egomotion image pairs, a popular and successful method for unsupervised learning of monocular depth estimation is to measure the quality of image reconstructions resulting from the learned depth predictions. Continued research has improved the overall approach in recent years, yet the common framework still suffers from several important limitations, particularly when dealing with points occluded after transformation to a novel viewpoint. While prior work has addressed this problem heuristically, this paper introduces a z-buffering algorithm that correctly and efficiently handles occluded points. Because our algorithm is implemented with operators typical of machine learning libraries, it can be incorporated into any existing unsupervised depth learning framework with automatic support for differentiation. Additionally, because points having negative depth after transformation often signify erroneously shallow depth predictions, we introduce a loss function to penalize this undesirable behavior explicitly. Experimental results on the KITTI data set show that the z-buffer and negative depth loss both improve the performance of a state of the art depth-prediction network.