 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLWM: Dual Latent World Models enable Holistic Gaussian-centric Pre-training in Autonomous Driving
Apr 01, 2026Vision-based autonomous driving has gained much attention due to its low costs and excellent performance. Compared with dense BEV (Bird's Eye View) or sparse query models, Gaussian-centric method is a comprehensive yet sparse representation by describing scene with 3D semantic Gaussians. In this paper, we introduce DLWM, a novel paradigm with Dual Latent World Models specifically designed to enable holistic gaussian-centric pre-training in autonomous driving using two stages. In the first stage, DLWM predicts 3D Gaussians from queries by self-supervised reconstructing multi-view semantic and depth images. Equipped with fine-grained contextual features, in the second stage, two latent world models are trained separately for temporal feature learning, including Gaussian-flow-guided latent prediction for downstream occupancy perception and forecasting tasks, and ego-planning-guided latent prediction for motion planning. Extensive experiments in SurroundOcc and nuScenes benchmarks demonstrate that DLWM shows significant performance gains across Gaussian-centric 3D occupancy perception, 4D occupancy forecasting and motion planning tasks.
Group Inertial Poser: Multi-Person Pose and Global Translation from Sparse Inertial Sensors and Ultra-Wideband Ranging
Oct 24, 2025Tracking human full-body motion using sparse wearable inertial measurement units (IMUs) overcomes the limitations of occlusion and instrumentation of the environment inherent in vision-based approaches. However, purely IMU-based tracking compromises translation estimates and accurate relative positioning between individuals, as inertial cues are inherently self-referential and provide no direct spatial reference for others. In this paper, we present a novel approach for robustly estimating body poses and global translation for multiple individuals by leveraging the distances between sparse wearable sensors - both on each individual and across multiple individuals. Our method Group Inertial Poser estimates these absolute distances between pairs of sensors from ultra-wideband ranging (UWB) and fuses them with inertial observations as input into structured state-space models to integrate temporal motion patterns for precise 3D pose estimation. Our novel two-step optimization further leverages the estimated distances for accurately tracking people's global trajectories through the world. We also introduce GIP-DB, the first IMU+UWB dataset for two-person tracking, which comprises 200 minutes of motion recordings from 14 participants. In our evaluation, Group Inertial Poser outperforms previous state-of-the-art methods in accuracy and robustness across synthetic and real-world data, showing the promise of IMU+UWB-based multi-human motion capture in the wild. Code, models, dataset: https://github.com/eth-siplab/GroupInertialPoser
An Efficient Occupancy World Model via Decoupled Dynamic Flow and Image-assisted Training
Dec 18, 2024



The field of autonomous driving is experiencing a surge of interest in world models, which aim to predict potential future scenarios based on historical observations. In this paper, we introduce DFIT-OccWorld, an efficient 3D occupancy world model that leverages decoupled dynamic flow and image-assisted training strategy, substantially improving 4D scene forecasting performance. To simplify the training process, we discard the previous two-stage training strategy and innovatively reformulate the occupancy forecasting problem as a decoupled voxels warping process. Our model forecasts future dynamic voxels by warping existing observations using voxel flow, whereas static voxels are easily obtained through pose transformation. Moreover, our method incorporates an image-assisted training paradigm to enhance prediction reliability. Specifically, differentiable volume rendering is adopted to generate rendered depth maps through predicted future volumes, which are adopted in render-based photometric consistency. Experiments demonstrate the effectiveness of our approach, showcasing its state-of-the-art performance on the nuScenes and OpenScene benchmarks for 4D occupancy forecasting, end-to-end motion planning and point cloud forecasting. Concretely, it achieves state-of-the-art performances compared to existing 3D world models while incurring substantially lower computational costs.
D$^2$-World: An Efficient World Model through Decoupled Dynamic Flow
Nov 26, 2024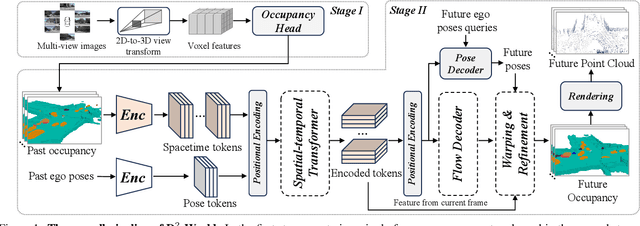
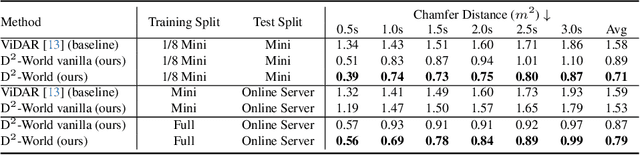
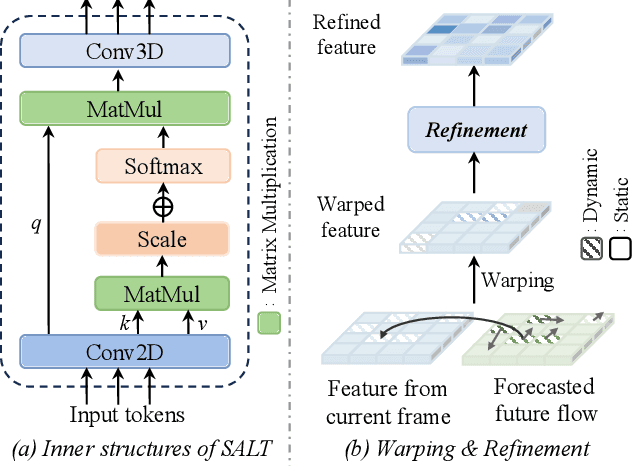
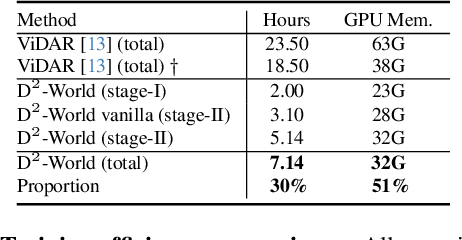
This technical report summarizes the second-place solution for the Predictive World Model Challenge held at the CVPR-2024 Workshop on Foundation Models for Autonomous Systems. We introduce D$^2$-World, a novel World model that effectively forecasts future point clouds through Decoupled Dynamic flow. Specifically, the past semantic occupancies are obtained via existing occupancy networks (e.g., BEVDet). Following this, the occupancy results serve as the input for a single-stage world model, generating future occupancy in a non-autoregressive manner. To further simplify the task, dynamic voxel decoupling is performed in the world model. The model generates future dynamic voxels by warping the existing observations through voxel flow, while remaining static voxels can be easily obtained through pose transformation. As a result, our approach achieves state-of-the-art performance on the OpenScene Predictive World Model benchmark, securing second place, and trains more than 300% faster than the baseline model. Code is available at https://github.com/zhanghm1995/D2-World.
X4D-SceneFormer: Enhanced Scene Understanding on 4D Point Cloud Videos through Cross-modal Knowledge Transfer
Dec 12, 2023The field of 4D point cloud understanding is rapidly developing with the goal of analyzing dynamic 3D point cloud sequences. However, it remains a challenging task due to the sparsity and lack of texture in point clouds. Moreover, the irregularity of point cloud poses a difficulty in aligning temporal information within video sequences. To address these issues, we propose a novel cross-modal knowledge transfer framework, called X4D-SceneFormer. This framework enhances 4D-Scene understanding by transferring texture priors from RGB sequences using a Transformer architecture with temporal relationship mining. Specifically, the framework is designed with a dual-branch architecture, consisting of an 4D point cloud transformer and a Gradient-aware Image Transformer (GIT). During training, we employ multiple knowledge transfer techniques, including temporal consistency losses and masked self-attention, to strengthen the knowledge transfer between modalities. This leads to enhanced performance during inference using single-modal 4D point cloud inputs. Extensive experiments demonstrate the superior performance of our framework on various 4D point cloud video understanding tasks, including action recognition, action segmentation and semantic segmentation. The results achieve 1st places, i.e., 85.3% (+7.9%) accuracy and 47.3% (+5.0%) mIoU for 4D action segmentation and semantic segmentation, on the HOI4D challenge\footnote{\url{http://www.hoi4d.top/}.}, outperforming previous state-of-the-art by a large margin. We release the code at https://github.com/jinglinglingling/X4D
Dense Residual Network for Retinal Vessel Segmentation
Apr 07, 2020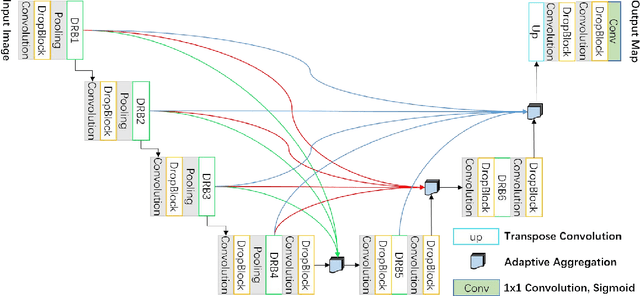
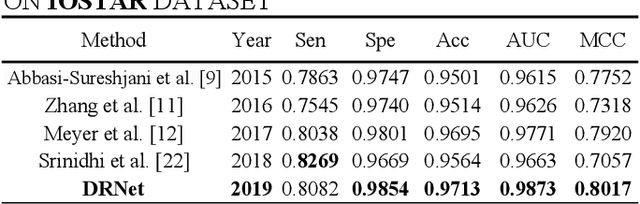
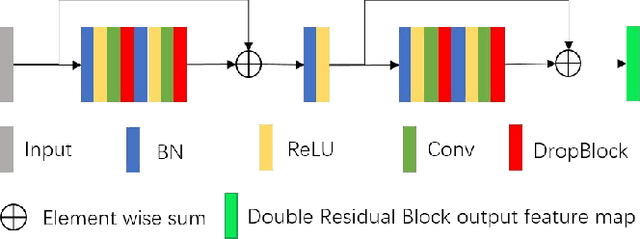
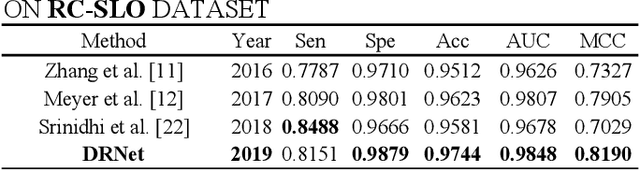
Retinal vessel segmentation plays an imaportant role in the field of retinal image analysis because changes in retinal vascular structure can aid in the diagnosis of diseases such as hypertension and diabetes. In recent research, numerous successful segmentation methods for fundus images have been proposed. But for other retinal imaging modalities, more research is needed to explore vascular extraction. In this work, we propose an efficient method to segment blood vessels in Scanning Laser Ophthalmoscopy (SLO) retinal images. Inspired by U-Net, "feature map reuse" and residual learning, we propose a deep dense residual network structure called DRNet. In DRNet, feature maps of previous blocks are adaptively aggregated into subsequent layers as input, which not only facilitates spatial reconstruction, but also learns more efficiently due to more stable gradients. Furthermore, we introduce DropBlock to alleviate the overfitting problem of the network. We train and test this model on the recent SLO public dataset. The results show that our method achieves the state-of-the-art performance even without data augmentation.