 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D SA-UNet: 3D Spatial Attention UNet with 3D ASPP for White Matter Hyperintensities Segmentation
Sep 20, 2023



White Matter Hyperintensity (WMH) is an imaging feature related to various diseases such as dementia and stroke. Accurately segmenting WMH using computer technology is crucial for early disease diagnosis. However, this task remains challenging due to the small lesions with low contrast and high discontinuity in the images, which contain limited contextual and spatial information. To address this challenge, we propose a deep learning model called 3D Spatial Attention U-Net (3D SA-UNet) for automatic WMH segmentation using only Fluid Attenuation Inversion Recovery (FLAIR) scans. The 3D SA-UNet introduces a 3D Spatial Attention Module that highlights important lesion features, such as WMH, while suppressing unimportant regions. Additionally, to capture features at different scales, we extend the Atrous Spatial Pyramid Pooling (ASPP) module to a 3D version, enhancing the segmentation performance of the network. We evaluate our method on publicly available dataset and demonstrate the effectiveness of 3D spatial attention module and 3D ASPP in WMH segmentation. Through experimental results, it has been demonstrated that our proposed 3D SA-UNet model achieves higher accuracy compared to other state-of-the-art 3D convolutional neural networks.
Channel Attention Separable Convolution Network for Skin Lesion Segmentation
Sep 03, 2023

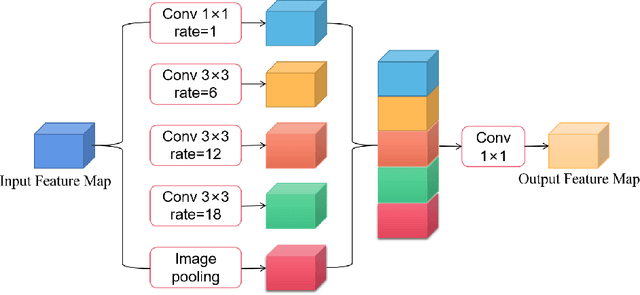

Skin cancer is a frequently occurring cancer in the human population, and it is very important to be able to diagnose malignant tumors in the body early. Lesion segmentation is crucial for monitoring the morphological changes of skin lesions, extracting features to localize and identify diseases to assist doctors in early diagnosis. Manual de-segmentation of dermoscopic images is error-prone and time-consuming, thus there is a pressing demand for precise and automated segmentation algorithms. Inspired by advanced mechanisms such as U-Net, DenseNet, Separable Convolution, Channel Attention, and Atrous Spatial Pyramid Pooling (ASPP), we propose a novel network called Channel Attention Separable Convolution Network (CASCN) for skin lesions segmentation. The proposed CASCN is evaluated on the PH2 dataset with limited images. Without excessive pre-/post-processing of images, CASCN achieves state-of-the-art performance on the PH2 dataset with Dice similarity coefficient of 0.9461 and accuracy of 0.9645.
Minimizing false negative rate in melanoma detection and providing insight into the causes of classification
Mar 09, 2021
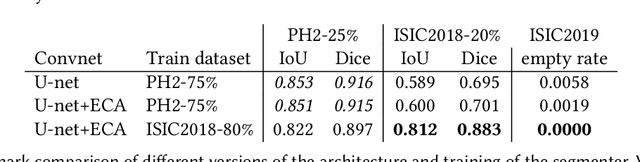
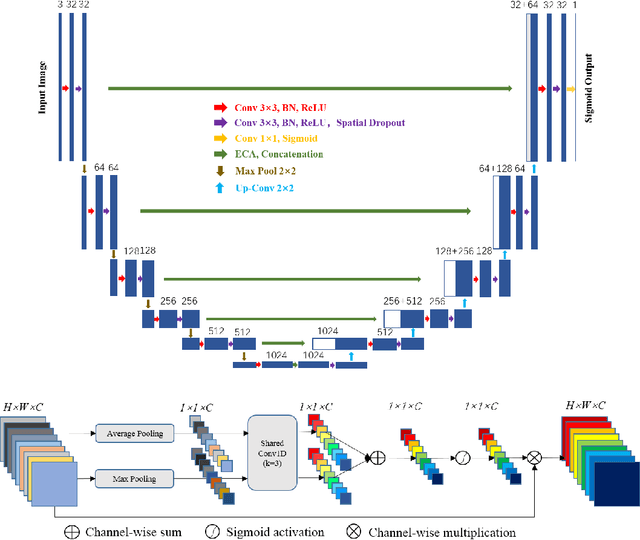
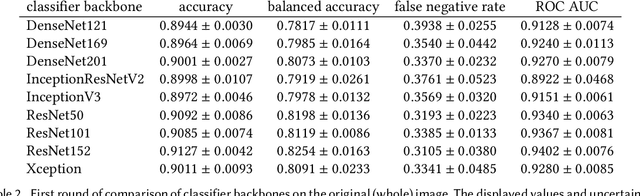
Our goal is to bridge human and machine intelligence in melanoma detection. We develop a classification system exploiting a combination of visual pre-processing, deep learning, and ensembling for providing explanations to experts and to minimize false negative rate while maintaining high accuracy in melanoma detection. Source images are first automatically segmented using a U-net CNN. The result of the segmentation is then used to extract image sub-areas and specific parameters relevant in human evaluation, namely center, border, and asymmetry measures. These data are then processed by tailored neural networks which include structure searching algorithms. Partial results are then ensembled by a committee machine. Our evaluation on the largest skin lesion dataset which is publicly available today, ISIC-2019, shows improvement in all evaluated metrics over a baseline using the original images only. We also showed that indicative scores computed by the feature classifiers can provide useful insight into the various features on which the decision can be based.
Residual Spatial Attention Network for Retinal Vessel Segmentation
Sep 18, 2020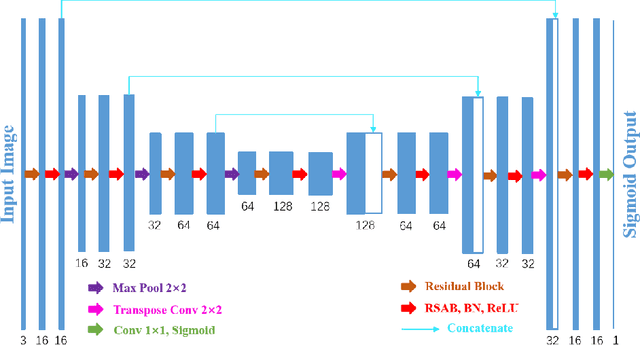
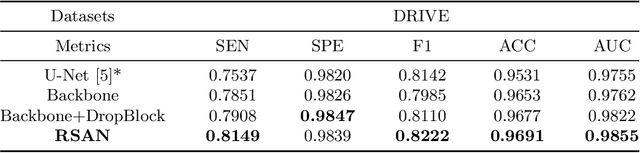

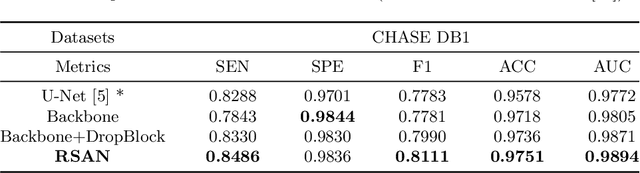
Reliable segmentation of retinal vessels can be employed as a way of monitoring and diagnosing certain diseases, such as diabetes and hypertension, as they affect the retinal vascular structure. In this work, we propose the Residual Spatial Attention Network (RSAN) for retinal vessel segmentation. RSAN employs a modified residual block structure that integrates DropBlock, which can not only be utilized to construct deep networks to extract more complex vascular features, but can also effectively alleviate the overfitting. Moreover, in order to further improve the representation capability of the network, based on this modified residual block, we introduce the spatial attention (SA) and propose the Residual Spatial Attention Block (RSAB) to build RSAN. We adopt the public DRIVE and CHASE DB1 color fundus image datasets to evaluate the proposed RSAN. Experiments show that the modified residual structure and the spatial attention are effective in this work, and our proposed RSAN achieves the state-of-the-art performance.
Channel Attention Residual U-Net for Retinal Vessel Segmentation
Apr 07, 2020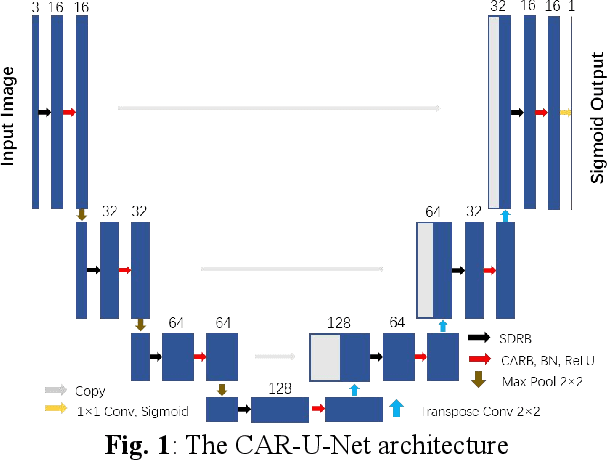
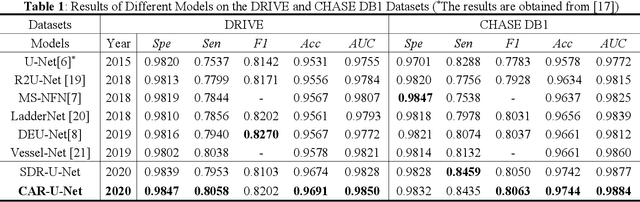

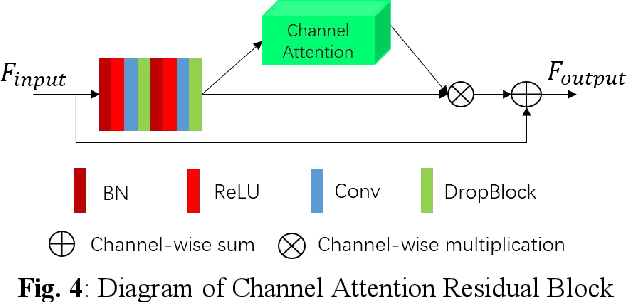
Retinal vessel segmentation is a vital step for the diagnosis of many early eye-related diseases. In this work, we propose a new deep learning model, namely Channel Attention Residual U-Net (CAR-U-Net), to accurately segment retinal vascular and non-vascular pixels. In this model, the channel attention mechanism was introduced into Residual Block and a Channel Attention Residual Block (CARB) was proposed to enhance the discriminative ability of the network by considering the interdependence between the feature channels. Moreover, to prevent the convolutional networks from overfitting, a Structured Dropout Residual Block (SDRB) was proposed, consisting of pre-activated residual block and DropBlock. The results show that our proposed CAR-U-Net has reached the state-of-the-art performance on two publicly available retinal vessel datasets: DRIVE and CHASE DB1.
Dense Residual Network for Retinal Vessel Segmentation
Apr 07, 2020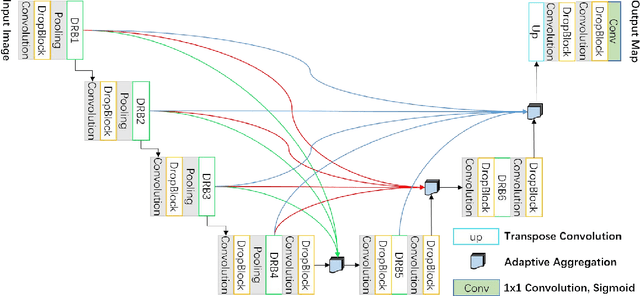
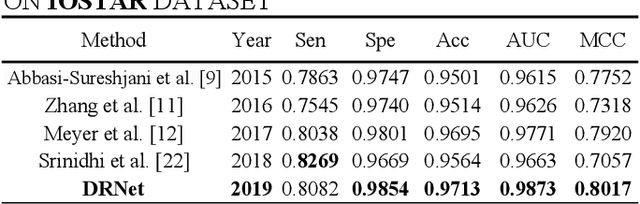
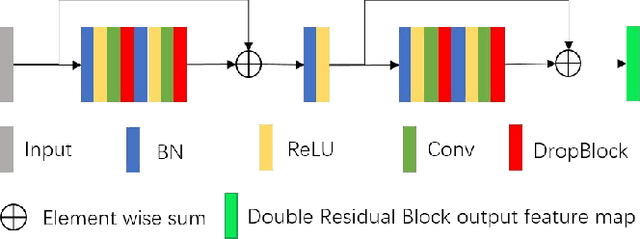
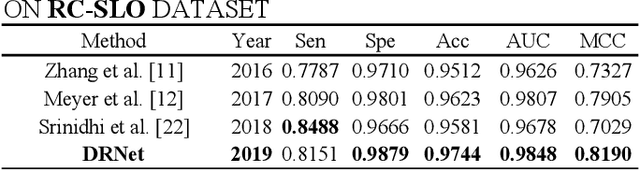
Retinal vessel segmentation plays an imaportant role in the field of retinal image analysis because changes in retinal vascular structure can aid in the diagnosis of diseases such as hypertension and diabetes. In recent research, numerous successful segmentation methods for fundus images have been proposed. But for other retinal imaging modalities, more research is needed to explore vascular extraction. In this work, we propose an efficient method to segment blood vessels in Scanning Laser Ophthalmoscopy (SLO) retinal images. Inspired by U-Net, "feature map reuse" and residual learning, we propose a deep dense residual network structure called DRNet. In DRNet, feature maps of previous blocks are adaptively aggregated into subsequent layers as input, which not only facilitates spatial reconstruction, but also learns more efficiently due to more stable gradients. Furthermore, we introduce DropBlock to alleviate the overfitting problem of the network. We train and test this model on the recent SLO public dataset. The results show that our method achieves the state-of-the-art performance even without data augmentation.
SA-UNet: Spatial Attention U-Net for Retinal Vessel Segmentation
Apr 07, 2020
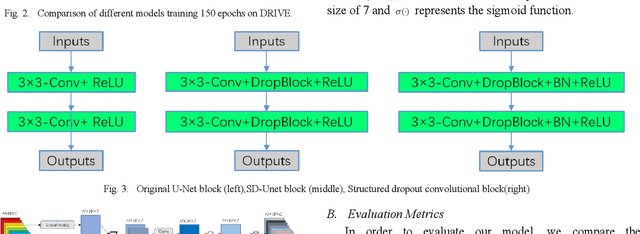
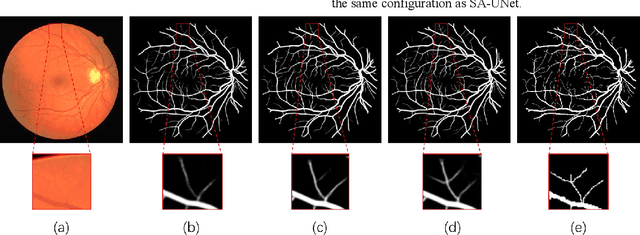

The precise segmentation of retinal blood vessel is of great significance for early diagnosis of eye-related diseases such as diabetes and hypertension. In this work, we propose a lightweight network named Spatial Attention U-Net (SA-UNet) that does not require thousands of annotated training samples and can be utilized in a data augmentation manner to use the available annotated samples more efficiently. SA-UNet introduces a spatial attention module which infers the attention map along the spatial dimension, and then multiply the attention map by the input feature map for adaptive feature refinement. In addition, the proposed network employees a kind of structured dropout convolutional block instead of the original convolutional block of U-Net to prevent the network from overfitting. We evaluate SA-UNet based on two benchmark retinal datasets: the Vascular Extraction (DRIVE) dataset and the Child Heart and Health Study (CHASE_DB1) dataset. The results show that our proposed SA-UNet achieves the state-of-the-art retinal vessel segmentation accuracy on both datasets.