 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges and opportunities in portraying emotion in generated sign language
Aug 11, 2025

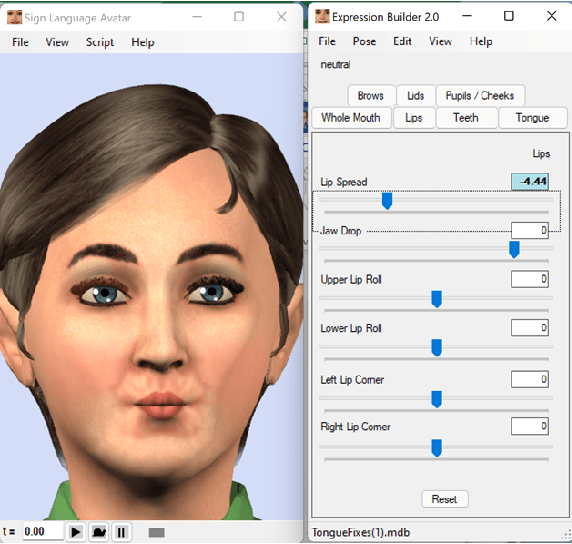

Non-manual signals in sign languages continue to be a challenge for signing avatars. More specifically, emotional content has been difficult to incorporate because of a lack of a standard method of specifying the avatar's emotional state. This paper explores the application of an intuitive two-parameter representation for emotive non-manual signals to the Paula signing avatar that shows promise for facilitating the linguistic specification of emotional facial expressions in a more coherent manner than previous methods. Users can apply these parameters to control Paula's emotional expressions through a textual representation called the EASIER notation. The representation can allow avatars to express more nuanced emotional states using two numerical parameters. It also has the potential to enable more consistent specification of emotional non-manual signals in linguistic annotations which drive signing avatars.
9th Workshop on Sign Language Translation and Avatar Technologies (SLTAT 2025)
Aug 11, 2025

The Sign Language Translation and Avatar Technology (SLTAT) workshops continue a series of gatherings to share recent advances in improving deaf / human communication through non-invasive means. This 2025 edition, the 9th since its first appearance in 2011, is hosted by the International Conference on Intelligent Virtual Agents (IVA), giving the opportunity for contamination between two research communities, using digital humans as either virtual interpreters or as interactive conversational agents. As presented in this summary paper, SLTAT sees contributions beyond avatar technologies, with a consistent number of submissions on sign language recognition, and other work on data collection, data analysis, tools, ethics, usability, and affective computing.
Evaluation of a Sign Language Avatar on Comprehensibility, User Experience \& Acceptability
Aug 07, 2025This paper presents an investigation into the impact of adding adjustment features to an existing sign language (SL) avatar on a Microsoft Hololens 2 device. Through a detailed analysis of interactions of expert German Sign Language (DGS) users with both adjustable and non-adjustable avatars in a specific use case, this study identifies the key factors influencing the comprehensibility, the user experience (UX), and the acceptability of such a system. Despite user preference for adjustable settings, no significant improvements in UX or comprehensibility were observed, which remained at low levels, amid missing SL elements (mouthings and facial expressions) and implementation issues (indistinct hand shapes, lack of feedback and menu positioning). Hedonic quality was rated higher than pragmatic quality, indicating that users found the system more emotionally or aesthetically pleasing than functionally useful. Stress levels were higher for the adjustable avatar, reflecting lower performance, greater effort and more frustration. Additionally, concerns were raised about whether the Hololens adjustment gestures are intuitive and easy to familiarise oneself with. While acceptability of the concept of adjustability was generally positive, it was strongly dependent on usability and animation quality. This study highlights that personalisation alone is insufficient, and that SL avatars must be comprehensible by default. Key recommendations include enhancing mouthing and facial animation, improving interaction interfaces, and applying participatory design.
The TUB Sign Language Corpus Collection
Aug 07, 2025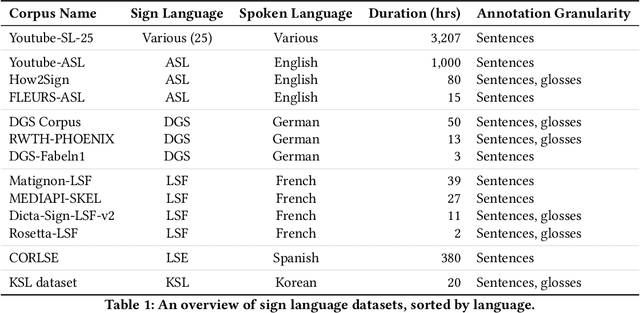
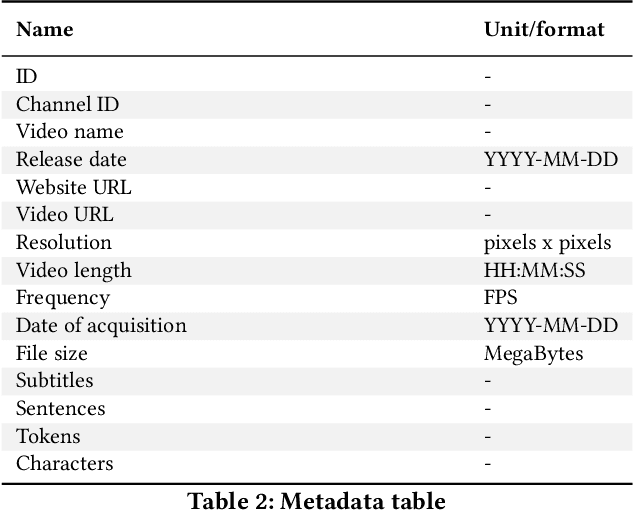
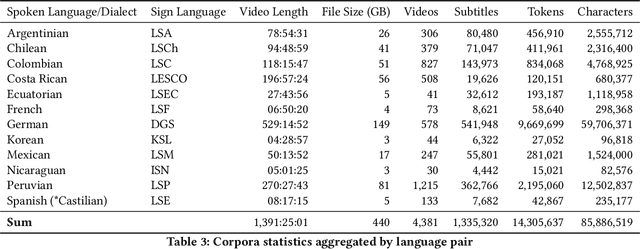
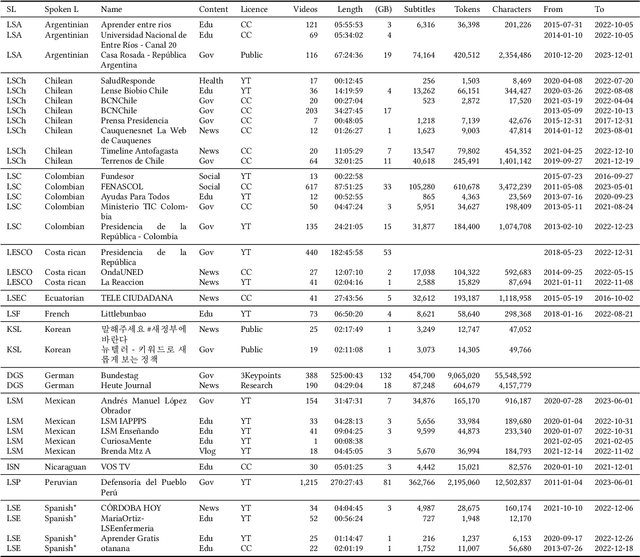
We present a collection of parallel corpora of 12 sign languages in video format, together with subtitles in the dominant spoken languages of the corresponding countries. The entire collection includes more than 1,300 hours in 4,381 video files, accompanied by 1,3~M subtitles containing 14~M tokens. Most notably, it includes the first consistent parallel corpora for 8 Latin American sign languages, whereas the size of the German Sign Language corpora is ten times the size of the previously available corpora. The collection was created by collecting and processing videos of multiple sign languages from various online sources, mainly broadcast material of news shows, governmental bodies and educational channels. The preparation involved several stages, including data collection, informing the content creators and seeking usage approvals, scraping, and cropping. The paper provides statistics on the collection and an overview of the methods used to collect the data.
Color histogram equalization and fine-tuning to improve expression recognition of (partially occluded) faces on sign language datasets
Jul 27, 2025The goal of this investigation is to quantify to what extent computer vision methods can correctly classify facial expressions on a sign language dataset. We extend our experiments by recognizing expressions using only the upper or lower part of the face, which is needed to further investigate the difference in emotion manifestation between hearing and deaf subjects. To take into account the peculiar color profile of a dataset, our method introduces a color normalization stage based on histogram equalization and fine-tuning. The results show the ability to correctly recognize facial expressions with 83.8% mean sensitivity and very little variance (.042) among classes. Like for humans, recognition of expressions from the lower half of the face (79.6%) is higher than that from the upper half (77.9%). Noticeably, the classification accuracy from the upper half of the face is higher than human level.
MMS Player: an open source software for parametric data-driven animation of Sign Language avatars
Jul 22, 2025This paper describes the MMS-Player, an open source software able to synthesise sign language animations from a novel sign language representation format called MMS (MultiModal Signstream). The MMS enhances gloss-based representations by adding information on parallel execution of signs, timing, and inflections. The implementation consists of Python scripts for the popular Blender 3D authoring tool and can be invoked via command line or HTTP API. Animations can be rendered as videos or exported in other popular 3D animation exchange formats. The software is freely available under GPL-3.0 license at https://github.com/DFKI-SignLanguage/MMS-Player.
Avatar Visual Similarity for Social HCI: Increasing Self-Awareness
Aug 23, 2024



Self-awareness is a critical factor in social human-human interaction and, hence, in social HCI interaction. Increasing self-awareness through mirrors or video recordings is common in face-to-face trainings, since it influences antecedents of self-awareness like explicit identification and implicit affective identification (affinity). However, increasing self-awareness has been scarcely examined in virtual trainings with virtual avatars, which allow for adjusting the similarity, e.g. to avoid negative effects of self-consciousness. Automatic visual similarity in avatars is an open issue related to high costs. It is important to understand which features need to be manipulated and which degree of similarity is necessary for self-awareness to leverage the added value of using avatars for self-awareness. This article examines the relationship between avatar visual similarity and increasing self-awareness in virtual training environments. We define visual similarity based on perceptually important facial features for human-human identification and develop a theory-based methodology to systematically manipulate visual similarity of virtual avatars and support self-awareness. Three personalized versions of virtual avatars with varying degrees of visual similarity to participants were created (weak, medium and strong facial features manipulation). In a within-subject study (N=33), we tested effects of degree of similarity on perceived similarity, explicit identification and implicit affective identification (affinity). Results show significant differences between the weak similarity manipulation, and both the strong manipulation and the random avatar for all three antecedents of self-awareness. An increasing degree of avatar visual similarity influences antecedents of self-awareness in virtual environments.
Fine-tuning of explainable CNNs for skin lesion classification based on dermatologists' feedback towards increasing trust
Apr 03, 2023



In this paper, we propose a CNN fine-tuning method which enables users to give simultaneous feedback on two outputs: the classification itself and the visual explanation for the classification. We present the effect of this feedback strategy in a skin lesion classification task and measure how CNNs react to the two types of user feedback. To implement this approach, we propose a novel CNN architecture that integrates the Grad-CAM technique for explaining the model's decision in the training loop. Using simulated user feedback, we found that fine-tuning our model on both classification and explanation improves visual explanation while preserving classification accuracy, thus potentially increasing the trust of users in using CNN-based skin lesion classifiers.
Towards social embodied cobots: The integration of an industrial cobot with a social virtual agent
Jan 16, 2023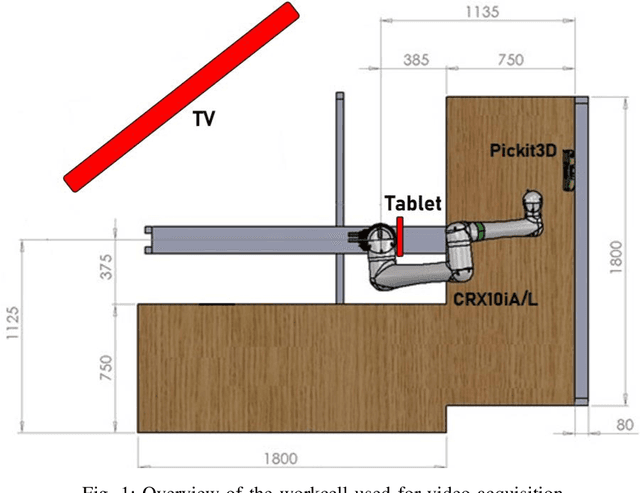


The integration of the physical capabilities of an industrial collaborative robot with a social virtual character may represent a viable solution to enhance the workers' perception of the system as an embodied social entity and increase social engagement and well-being at the workplace. An online study was setup using prerecorded video interactions in order to pilot potential advantages of different embodied configurations of the cobot-avatar system in terms of perceptions of Social Presence, cobot-avatar Unity and Social Role of the system, and explore the relation of these. In particular, two different configurations were explored and compared: the virtual character was displayed either on a tablet strapped onto the base of the cobot or on a large TV screen positioned at the back of the workcell. The results imply that participants showed no clear preference based on the constructs, and both configurations fulfill these basic criteria. In terms of the relations between the constructs, there were strong correlations between perception of Social Presence, Unity and Social Role (Collegiality). This gives a valuable insight into the role of these constructs in the perception of cobots as embodied social entities, and towards building cobots that support well-being at the workplace.
Minimizing false negative rate in melanoma detection and providing insight into the causes of classification
Mar 09, 2021
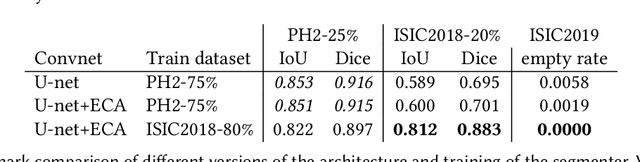
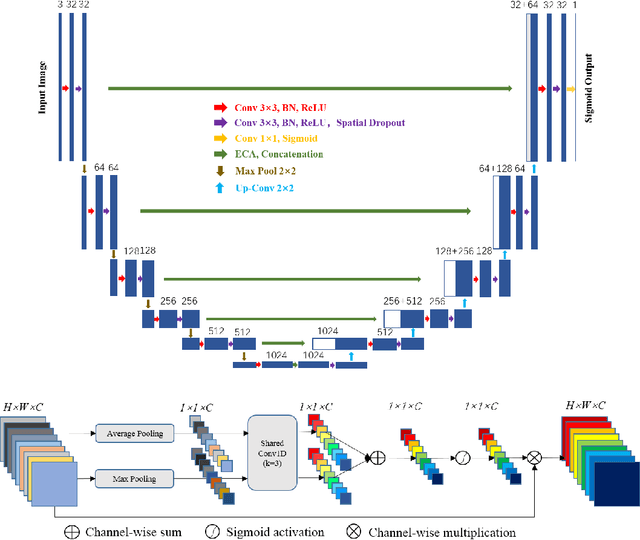
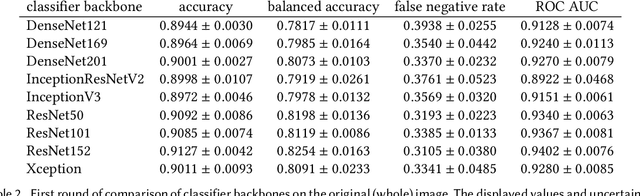
Our goal is to bridge human and machine intelligence in melanoma detection. We develop a classification system exploiting a combination of visual pre-processing, deep learning, and ensembling for providing explanations to experts and to minimize false negative rate while maintaining high accuracy in melanoma detection. Source images are first automatically segmented using a U-net CNN. The result of the segmentation is then used to extract image sub-areas and specific parameters relevant in human evaluation, namely center, border, and asymmetry measures. These data are then processed by tailored neural networks which include structure searching algorithms. Partial results are then ensembled by a committee machine. Our evaluation on the largest skin lesion dataset which is publicly available today, ISIC-2019, shows improvement in all evaluated metrics over a baseline using the original images only. We also showed that indicative scores computed by the feature classifiers can provide useful insight into the various features on which the decision can be based.