 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurface Defect Classification in Real-Time Using Convolutional Neural Networks
Apr 07, 2019
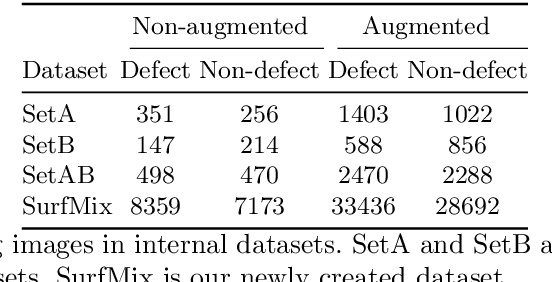
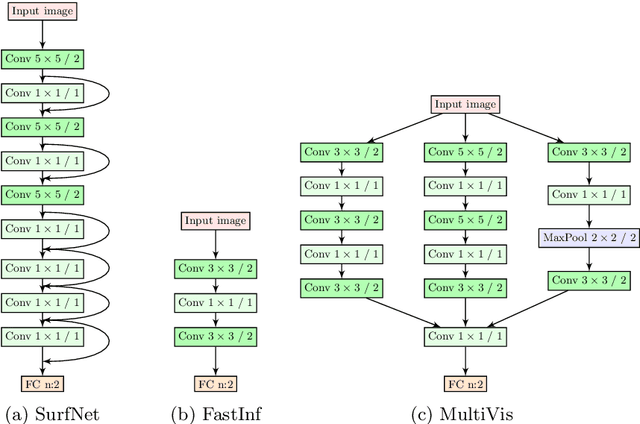
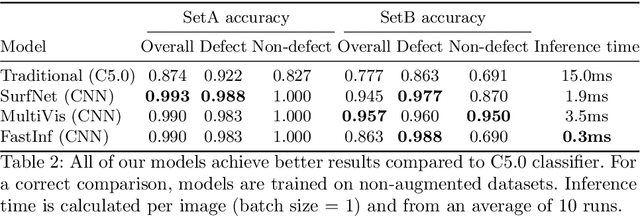
Surface inspection systems are an important application domain for computer vision, as they are used for defect detection and classification in the manufacturing industry. Existing systems use hand-crafted features which require extensive domain knowledge to create. Even though Convolutional neural networks (CNNs) have proven successful in many large-scale challenges, industrial inspection systems have yet barely realized their potential due to two significant challenges: real-time processing speed requirements and specialized narrow domain-specific datasets which are sometimes limited in size. In this paper, we propose CNN models that are specifically designed to handle capacity and real-time speed requirements of surface inspection systems. To train and evaluate our network models, we created a surface image dataset containing more than 22000 labeled images with many types of surface materials and achieved 98.0% accuracy in binary defect classification. To solve the class imbalance problem in our datasets, we introduce neural data augmentation methods which are also applicable to similar domains that suffer from the same problem. Our results show that deep learning based methods are feasible to be used in surface inspection systems and outperform traditional methods in accuracy and inference time by considerable margins.
Learning Quadrangulated Patches For 3D Shape Processing
Mar 25, 2019
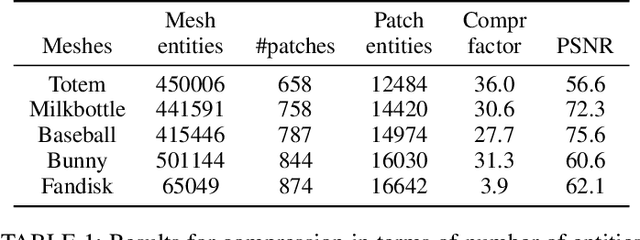


We propose a system for surface completion and inpainting of 3D shapes using generative models, learnt on local patches. Our method uses a novel encoding of height map based local patches parameterized using 3D mesh quadrangulation of the low resolution input shape. This provides us sufficient amount of local 3D patches to learn a generative model for the task of repairing moderate sized holes. Following the ideas from the recent progress in 2D inpainting, we investigated both linear dictionary based model and convolutional denoising autoencoders based model for the task for inpainting, and show our results to be better than the previous geometry based method of surface inpainting. We validate our method on both synthetic shapes and real world scans.
DeepHPS: End-to-end Estimation of 3D Hand Pose and Shape by Learning from Synthetic Depth
Aug 28, 2018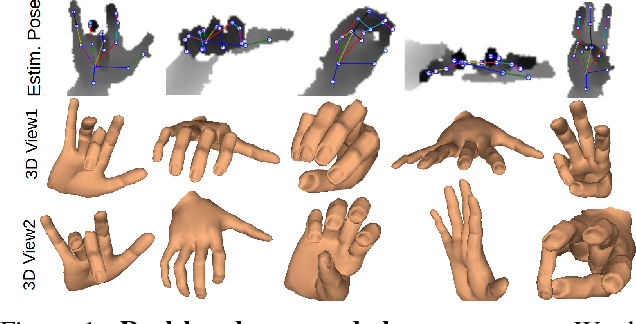
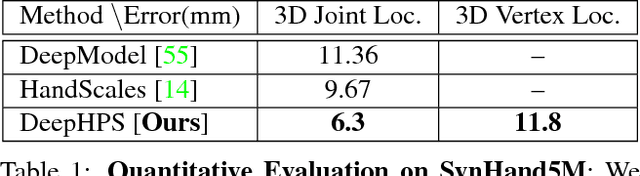
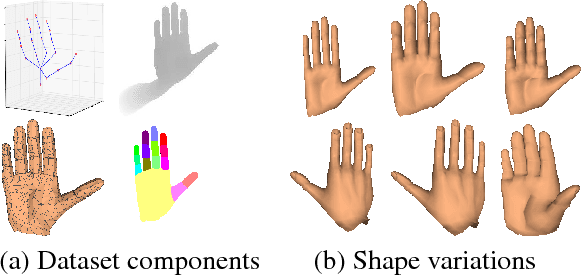
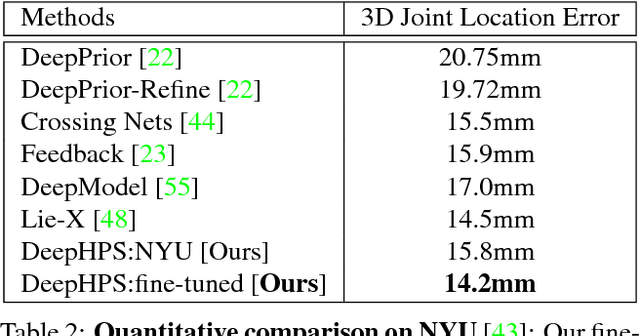
Articulated hand pose and shape estimation is an important problem for vision-based applications such as augmented reality and animation. In contrast to the existing methods which optimize only for joint positions, we propose a fully supervised deep network which learns to jointly estimate a full 3D hand mesh representation and pose from a single depth image. To this end, a CNN architecture is employed to estimate parametric representations i.e. hand pose, bone scales and complex shape parameters. Then, a novel hand pose and shape layer, embedded inside our deep framework, produces 3D joint positions and hand mesh. Lack of sufficient training data with varying hand shapes limits the generalized performance of learning based methods. Also, manually annotating real data is suboptimal. Therefore, we present SynHand5M: a million-scale synthetic dataset with accurate joint annotations, segmentation masks and mesh files of depth maps. Among model based learning (hybrid) methods, we show improved results on our dataset and two of the public benchmarks i.e. NYU and ICVL. Also, by employing a joint training strategy with real and synthetic data, we recover 3D hand mesh and pose from real images in 3.7ms.
Learning 3D Shapes as Multi-Layered Height-maps using 2D Convolutional Networks
Jul 26, 2018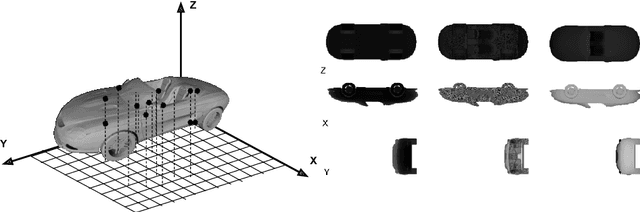

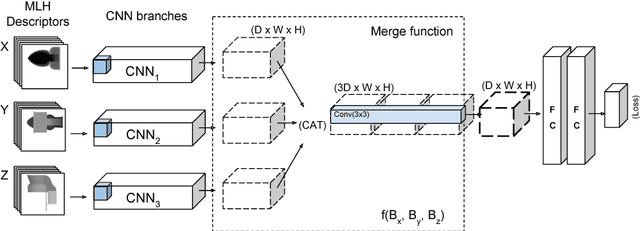
We present a novel global representation of 3D shapes, suitable for the application of 2D CNNs. We represent 3D shapes as multi-layered height-maps (MLH) where at each grid location, we store multiple instances of height maps, thereby representing 3D shape detail that is hidden behind several layers of occlusion. We provide a novel view merging method for combining view dependent information (Eg. MLH descriptors) from multiple views. Because of the ability of using 2D CNNs, our method is highly memory efficient in terms of input resolution compared to the voxel based input. Together with MLH descriptors and our multi view merging, we achieve the state-of-the-art result in classification on ModelNet dataset.
Fast View Synthesis with Deep Stereo Vision
May 07, 2018
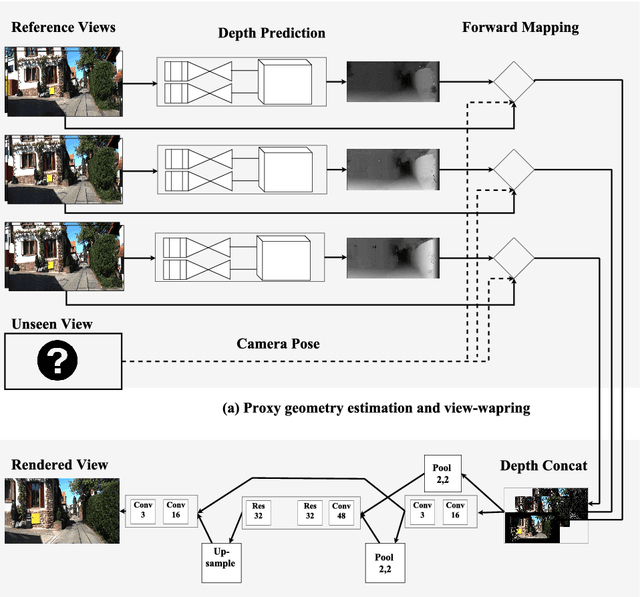
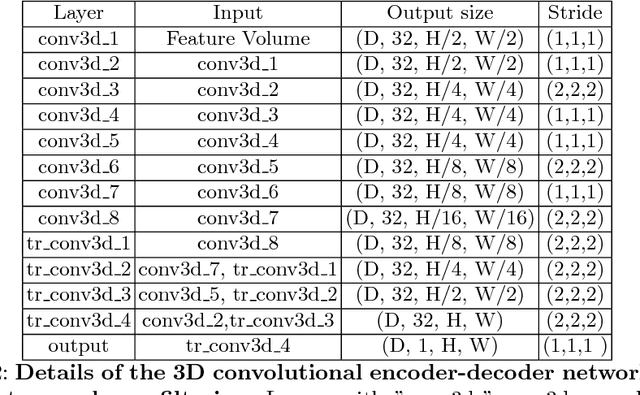
Novel view synthesis is an important problem in computer vision and graphics. Over the years a large number of solutions have been put forward to solve the problem. However, the large-baseline novel view synthesis problem is far from being "solved". Recent works have attempted to use Convolutional Neural Networks (CNNs) to solve view synthesis tasks. Due to the difficulty of learning scene geometry and interpreting camera motion, CNNs are often unable to generate realistic novel views. In this paper, we present a novel view synthesis approach based on stereo-vision and CNNs that decomposes the problem into two sub-tasks: view dependent geometry estimation and texture inpainting. Both tasks are structured prediction problems that could be effectively learned with CNNs. Experiments on the KITTI Odometry dataset show that our approach is more accurate and significantly faster than the current state-of-the-art. The code and supplementary material will be publicly available. Results could be found here https://youtu.be/5pzS9jc-5t0
HDM-Net: Monocular Non-Rigid 3D Reconstruction with Learned Deformation Model
Mar 27, 2018



Monocular dense 3D reconstruction of deformable objects is a hard ill-posed problem in computer vision. Current techniques either require dense correspondences and rely on motion and deformation cues, or assume a highly accurate reconstruction (referred to as a template) of at least a single frame given in advance and operate in the manner of non-rigid tracking. Accurate computation of dense point tracks often requires multiple frames and might be computationally expensive. Availability of a template is a very strong prior which restricts system operation to a pre-defined environment and scenarios. In this work, we propose a new hybrid approach for monocular non-rigid reconstruction which we call Hybrid Deformation Model Network (HDM-Net). In our approach, deformation model is learned by a deep neural network, with a combination of domain-specific loss functions. We train the network with multiple states of a non-rigidly deforming structure with a known shape at rest. HDM-Net learns different reconstruction cues including texture-dependent surface deformations, shading and contours. We show generalisability of HDM-Net to states not presented in the training dataset, with unseen textures and under new illumination conditions. Experiments with noisy data and a comparison with other methods demonstrate robustness and accuracy of the proposed approach and suggest possible application scenarios of the new technique in interventional diagnostics and augmented reality.
Learning quadrangulated patches for 3D shape parameterization and completion
Sep 20, 2017
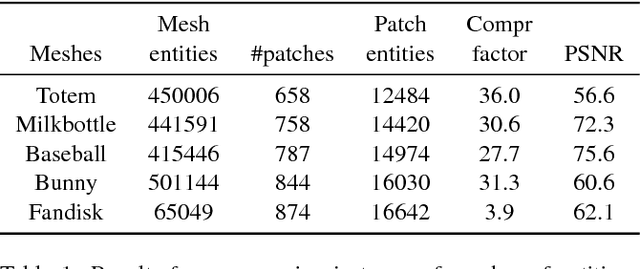


We propose a novel 3D shape parameterization by surface patches, that are oriented by 3D mesh quadrangulation of the shape. By encoding 3D surface detail on local patches, we learn a patch dictionary that identifies principal surface features of the shape. Unlike previous methods, we are able to encode surface patches of variable size as determined by the user. We propose novel methods for dictionary learning and patch reconstruction based on the query of a noisy input patch with holes. We evaluate the patch dictionary towards various applications in 3D shape inpainting, denoising and compression. Our method is able to predict missing vertices and inpaint moderately sized holes. We demonstrate a complete pipeline for reconstructing the 3D mesh from the patch encoding. We validate our shape parameterization and reconstruction methods on both synthetic shapes and real world scans. We show that our patch dictionary performs successful shape completion of complicated surface textures.
CNN-based Patch Matching for Optical Flow with Thresholded Hinge Embedding Loss
May 18, 2017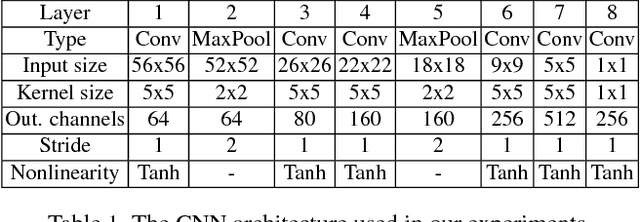



Learning based approaches have not yet achieved their full potential in optical flow estimation, where their performance still trails heuristic approaches. In this paper, we present a CNN based patch matching approach for optical flow estimation. An important contribution of our approach is a novel thresholded loss for Siamese networks. We demonstrate that our loss performs clearly better than existing losses. It also allows to speed up training by a factor of 2 in our tests. Furthermore, we present a novel way for calculating CNN based features for different image scales, which performs better than existing methods. We also discuss new ways of evaluating the robustness of trained features for the application of patch matching for optical flow. An interesting discovery in our paper is that low-pass filtering of feature maps can increase the robustness of features created by CNNs. We proved the competitive performance of our approach by submitting it to the KITTI 2012, KITTI 2015 and MPI-Sintel evaluation portals where we obtained state-of-the-art results on all three datasets.