 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDICE: End-to-end Deformation Capture of Hand-Face Interactions from a Single Image
Jun 26, 2024



Reconstructing 3D hand-face interactions with deformations from a single image is a challenging yet crucial task with broad applications in AR, VR, and gaming. The challenges stem from self-occlusions during single-view hand-face interactions, diverse spatial relationships between hands and face, complex deformations, and the ambiguity of the single-view setting. The first and only method for hand-face interaction recovery, Decaf, introduces a global fitting optimization guided by contact and deformation estimation networks trained on studio-collected data with 3D annotations. However, Decaf suffers from a time-consuming optimization process and limited generalization capability due to its reliance on 3D annotations of hand-face interaction data. To address these issues, we present DICE, the first end-to-end method for Deformation-aware hand-face Interaction reCovEry from a single image. DICE estimates the poses of hands and faces, contacts, and deformations simultaneously using a Transformer-based architecture. It features disentangling the regression of local deformation fields and global mesh vertex locations into two network branches, enhancing deformation and contact estimation for precise and robust hand-face mesh recovery. To improve generalizability, we propose a weakly-supervised training approach that augments the training set using in-the-wild images without 3D ground-truth annotations, employing the depths of 2D keypoints estimated by off-the-shelf models and adversarial priors of poses for supervision. Our experiments demonstrate that DICE achieves state-of-the-art performance on a standard benchmark and in-the-wild data in terms of accuracy and physical plausibility. Additionally, our method operates at an interactive rate (20 fps) on an Nvidia 4090 GPU, whereas Decaf requires more than 15 seconds for a single image. Our code will be publicly available upon publication.
MACS: Mass Conditioned 3D Hand and Object Motion Synthesis
Dec 22, 2023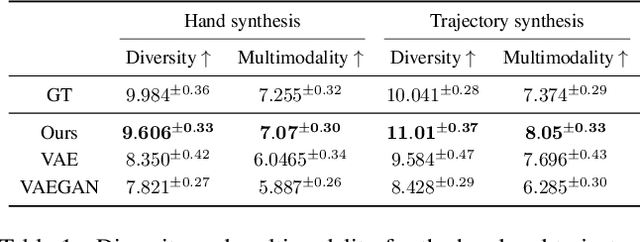
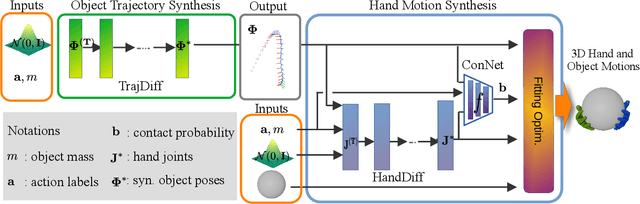
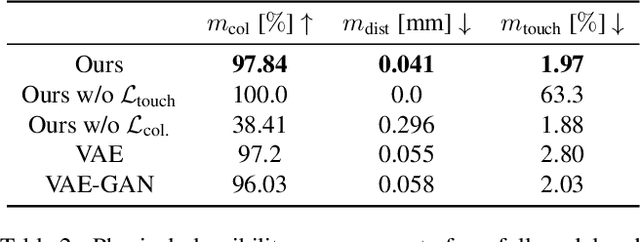

The physical properties of an object, such as mass, significantly affect how we manipulate it with our hands. Surprisingly, this aspect has so far been neglected in prior work on 3D motion synthesis. To improve the naturalness of the synthesized 3D hand object motions, this work proposes MACS the first MAss Conditioned 3D hand and object motion Synthesis approach. Our approach is based on cascaded diffusion models and generates interactions that plausibly adjust based on the object mass and interaction type. MACS also accepts a manually drawn 3D object trajectory as input and synthesizes the natural 3D hand motions conditioned by the object mass. This flexibility enables MACS to be used for various downstream applications, such as generating synthetic training data for ML tasks, fast animation of hands for graphics workflows, and generating character interactions for computer games. We show experimentally that a small-scale dataset is sufficient for MACS to reasonably generalize across interpolated and extrapolated object masses unseen during the training. Furthermore, MACS shows moderate generalization to unseen objects, thanks to the mass-conditioned contact labels generated by our surface contact synthesis model ConNet. Our comprehensive user study confirms that the synthesized 3D hand-object interactions are highly plausible and realistic.
Decaf: Monocular Deformation Capture for Face and Hand Interactions
Oct 13, 2023

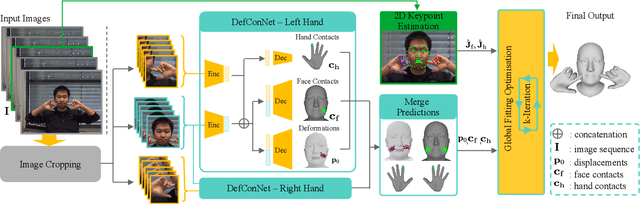
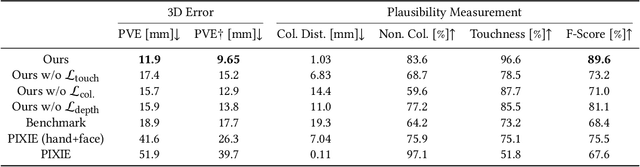
Existing methods for 3D tracking from monocular RGB videos predominantly consider articulated and rigid objects. Modelling dense non-rigid object deformations in this setting remained largely unaddressed so far, although such effects can improve the realism of the downstream applications such as AR/VR and avatar communications. This is due to the severe ill-posedness of the monocular view setting and the associated challenges. While it is possible to naively track multiple non-rigid objects independently using 3D templates or parametric 3D models, such an approach would suffer from multiple artefacts in the resulting 3D estimates such as depth ambiguity, unnatural intra-object collisions and missing or implausible deformations. Hence, this paper introduces the first method that addresses the fundamental challenges depicted above and that allows tracking human hands interacting with human faces in 3D from single monocular RGB videos. We model hands as articulated objects inducing non-rigid face deformations during an active interaction. Our method relies on a new hand-face motion and interaction capture dataset with realistic face deformations acquired with a markerless multi-view camera system. As a pivotal step in its creation, we process the reconstructed raw 3D shapes with position-based dynamics and an approach for non-uniform stiffness estimation of the head tissues, which results in plausible annotations of the surface deformations, hand-face contact regions and head-hand positions. At the core of our neural approach are a variational auto-encoder supplying the hand-face depth prior and modules that guide the 3D tracking by estimating the contacts and the deformations. Our final 3D hand and face reconstructions are realistic and more plausible compared to several baselines applicable in our setting, both quantitatively and qualitatively. https://vcai.mpi-inf.mpg.de/projects/Decaf
MoCapDeform: Monocular 3D Human Motion Capture in Deformable Scenes
Aug 17, 2022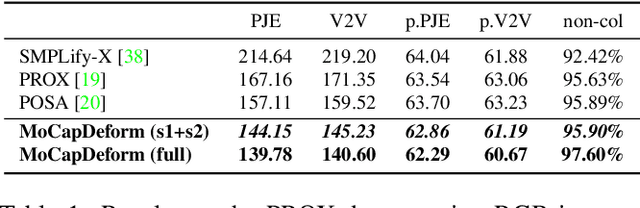
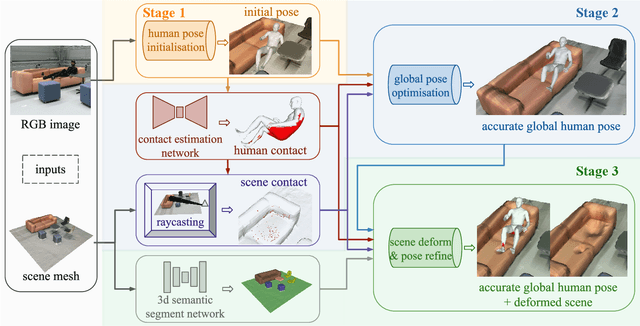
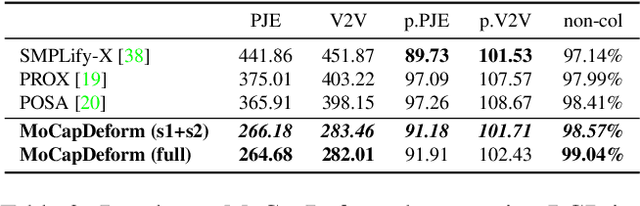
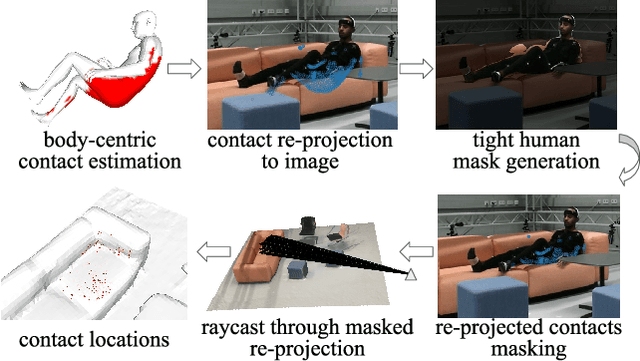
3D human motion capture from monocular RGB images respecting interactions of a subject with complex and possibly deformable environments is a very challenging, ill-posed and under-explored problem. Existing methods address it only weakly and do not model possible surface deformations often occurring when humans interact with scene surfaces. In contrast, this paper proposes MoCapDeform, i.e., a new framework for monocular 3D human motion capture that is the first to explicitly model non-rigid deformations of a 3D scene for improved 3D human pose estimation and deformable environment reconstruction. MoCapDeform accepts a monocular RGB video and a 3D scene mesh aligned in the camera space. It first localises a subject in the input monocular video along with dense contact labels using a new raycasting based strategy. Next, our human-environment interaction constraints are leveraged to jointly optimise global 3D human poses and non-rigid surface deformations. MoCapDeform achieves superior accuracy than competing methods on several datasets, including our newly recorded one with deforming background scenes.
* 11 pages, 8 figures, 3 tables; project page: https://4dqv.mpi-inf.mpg.de/MoCapDeform/
UnrealEgo: A New Dataset for Robust Egocentric 3D Human Motion Capture
Aug 02, 2022
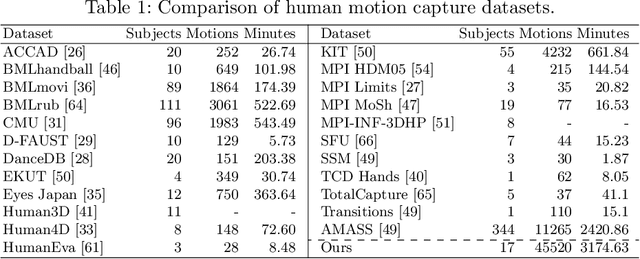

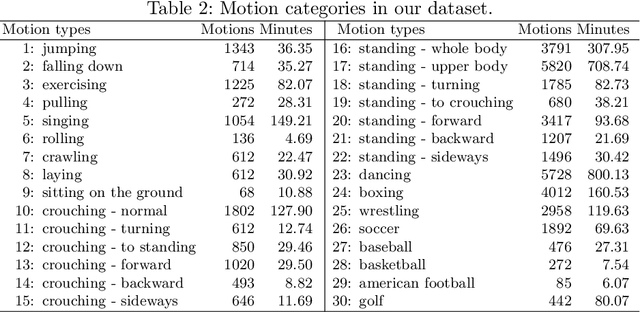
We present UnrealEgo, i.e., a new large-scale naturalistic dataset for egocentric 3D human pose estimation. UnrealEgo is based on an advanced concept of eyeglasses equipped with two fisheye cameras that can be used in unconstrained environments. We design their virtual prototype and attach them to 3D human models for stereo view capture. We next generate a large corpus of human motions. As a consequence, UnrealEgo is the first dataset to provide in-the-wild stereo images with the largest variety of motions among existing egocentric datasets. Furthermore, we propose a new benchmark method with a simple but effective idea of devising a 2D keypoint estimation module for stereo inputs to improve 3D human pose estimation. The extensive experiments show that our approach outperforms the previous state-of-the-art methods qualitatively and quantitatively. UnrealEgo and our source codes are available on our project web page.
* 21 pages, 10 figures, 10 tables; project page: https://4dqv.mpi-inf.mpg.de/UnrealEgo/
Unbiased 4D: Monocular 4D Reconstruction with a Neural Deformation Model
Jun 16, 2022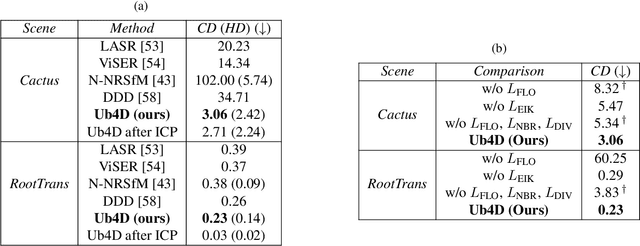
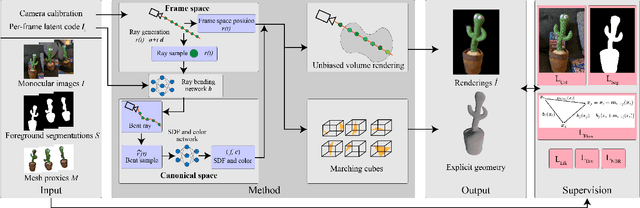

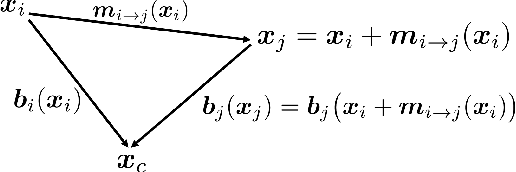
Capturing general deforming scenes is crucial for many computer graphics and vision applications, and it is especially challenging when only a monocular RGB video of the scene is available. Competing methods assume dense point tracks, 3D templates, large-scale training datasets, or only capture small-scale deformations. In contrast to those, our method, Ub4D, makes none of these assumptions while outperforming the previous state of the art in challenging scenarios. Our technique includes two new, in the context of non-rigid 3D reconstruction, components, i.e., 1) A coordinate-based and implicit neural representation for non-rigid scenes, which enables an unbiased reconstruction of dynamic scenes, and 2) A novel dynamic scene flow loss, which enables the reconstruction of larger deformations. Results on our new dataset, which will be made publicly available, demonstrate the clear improvement over the state of the art in terms of surface reconstruction accuracy and robustness to large deformations. Visit the project page https://4dqv.mpi-inf.mpg.de/Ub4D/.
HULC: 3D Human Motion Capture with Pose Manifold Sampling and Dense Contact Guidance
May 24, 2022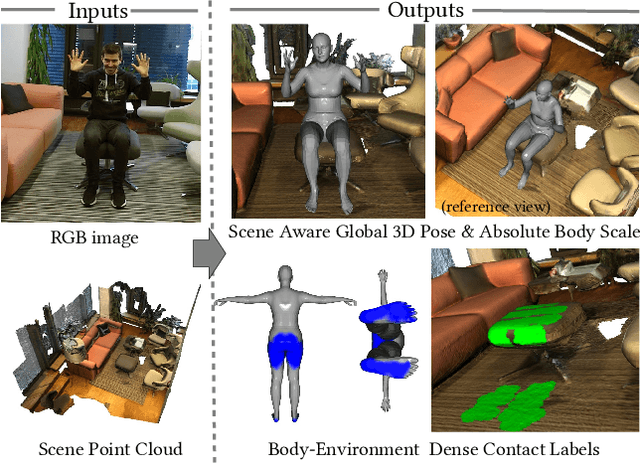
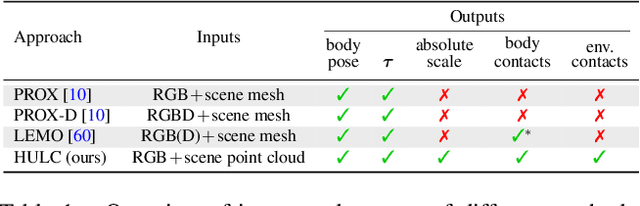
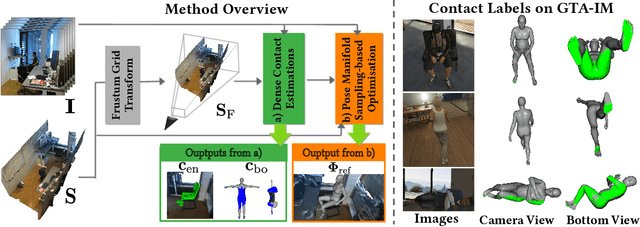
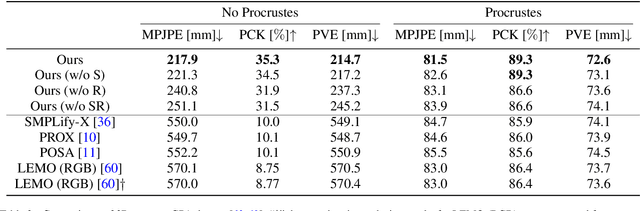
Marker-less monocular 3D human motion capture (MoCap) with scene interactions is a challenging research topic relevant for extended reality, robotics and virtual avatar generation. Due to the inherent depth ambiguity of monocular settings, 3D motions captured with existing methods often contain severe artefacts such as incorrect body-scene inter-penetrations, jitter and body floating. To tackle these issues, we propose HULC, a new approach for 3D human MoCap which is aware of the scene geometry. HULC estimates 3D poses and dense body-environment surface contacts for improved 3D localisations, as well as the absolute scale of the subject. Furthermore, we introduce a 3D pose trajectory optimisation based on a novel pose manifold sampling that resolves erroneous body-environment inter-penetrations. Although the proposed method requires less structured inputs compared to existing scene-aware monocular MoCap algorithms, it produces more physically-plausible poses: HULC significantly and consistently outperforms the existing approaches in various experiments and on different metrics.
Gravity-Aware Monocular 3D Human-Object Reconstruction
Aug 19, 2021

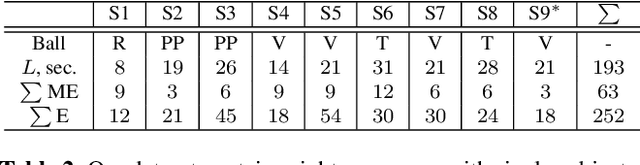
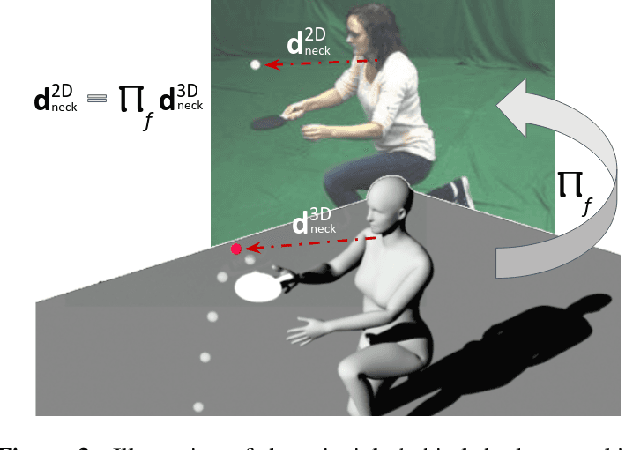
This paper proposes GraviCap, i.e., a new approach for joint markerless 3D human motion capture and object trajectory estimation from monocular RGB videos. We focus on scenes with objects partially observed during a free flight. In contrast to existing monocular methods, we can recover scale, object trajectories as well as human bone lengths in meters and the ground plane's orientation, thanks to the awareness of the gravity constraining object motions. Our objective function is parametrised by the object's initial velocity and position, gravity direction and focal length, and jointly optimised for one or several free flight episodes. The proposed human-object interaction constraints ensure geometric consistency of the 3D reconstructions and improved physical plausibility of human poses compared to the unconstrained case. We evaluate GraviCap on a new dataset with ground-truth annotations for persons and different objects undergoing free flights. In the experiments, our approach achieves state-of-the-art accuracy in 3D human motion capture on various metrics. We urge the reader to watch our supplementary video. Both the source code and the dataset are released; see http://4dqv.mpi-inf.mpg.de/GraviCap/.
* 12 pages, six figures, five tables; project webpage: http://4dqv.mpi-inf.mpg.de/GraviCap/
HandVoxNet++: 3D Hand Shape and Pose Estimation using Voxel-Based Neural Networks
Jul 02, 2021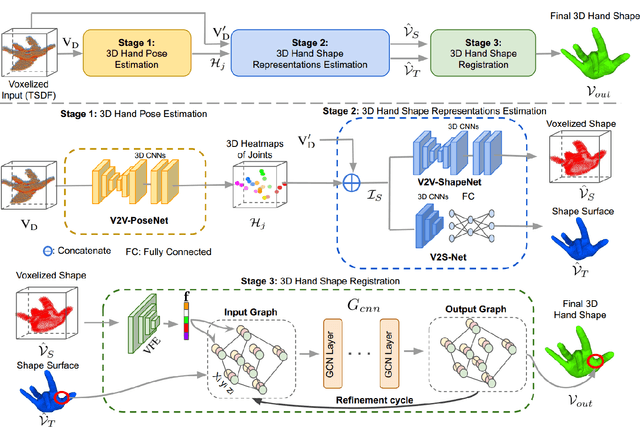
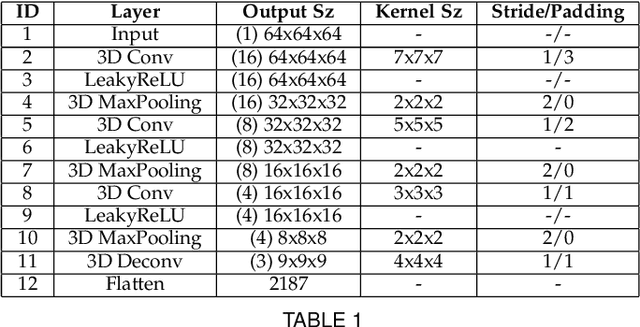

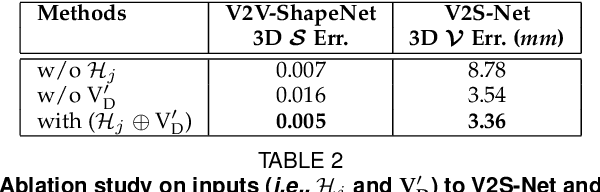
3D hand shape and pose estimation from a single depth map is a new and challenging computer vision problem with many applications. Existing methods addressing it directly regress hand meshes via 2D convolutional neural networks, which leads to artifacts due to perspective distortions in the images. To address the limitations of the existing methods, we develop HandVoxNet++, i.e., a voxel-based deep network with 3D and graph convolutions trained in a fully supervised manner. The input to our network is a 3D voxelized-depth-map-based on the truncated signed distance function (TSDF). HandVoxNet++ relies on two hand shape representations. The first one is the 3D voxelized grid of hand shape, which does not preserve the mesh topology and which is the most accurate representation. The second representation is the hand surface that preserves the mesh topology. We combine the advantages of both representations by aligning the hand surface to the voxelized hand shape either with a new neural Graph-Convolutions-based Mesh Registration (GCN-MeshReg) or classical segment-wise Non-Rigid Gravitational Approach (NRGA++) which does not rely on training data. In extensive evaluations on three public benchmarks, i.e., SynHand5M, depth-based HANDS19 challenge and HO-3D, the proposed HandVoxNet++ achieves the state-of-the-art performance. In this journal extension of our previous approach presented at CVPR 2020, we gain 41.09% and 13.7% higher shape alignment accuracy on SynHand5M and HANDS19 datasets, respectively. Our method is ranked first on the HANDS19 challenge dataset (Task 1: Depth-Based 3D Hand Pose Estimation) at the moment of the submission of our results to the portal in August 2020.
Fast Simultaneous Gravitational Alignment of Multiple Point Sets
Jun 21, 2021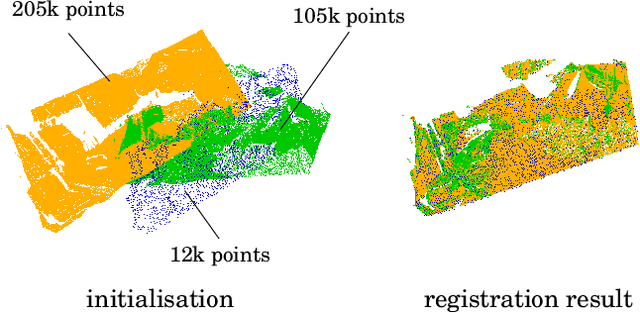
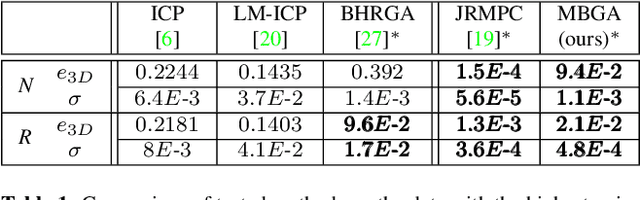
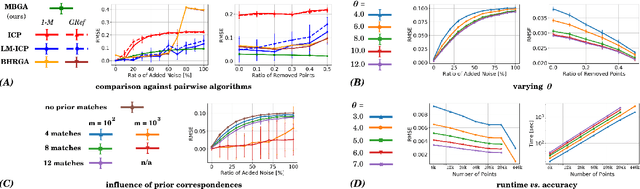
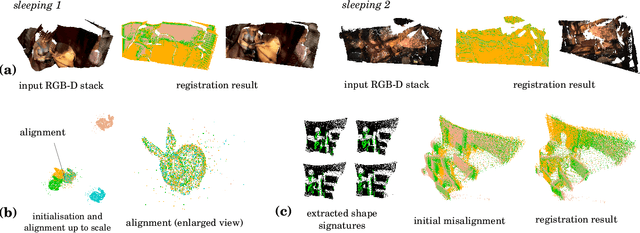
The problem of simultaneous rigid alignment of multiple unordered point sets which is unbiased towards any of the inputs has recently attracted increasing interest, and several reliable methods have been newly proposed. While being remarkably robust towards noise and clustered outliers, current approaches require sophisticated initialisation schemes and do not scale well to large point sets. This paper proposes a new resilient technique for simultaneous registration of multiple point sets by interpreting the latter as particle swarms rigidly moving in the mutually induced force fields. Thanks to the improved simulation with altered physical laws and acceleration of globally multiply-linked point interactions with a 2^D-tree (D is the space dimensionality), our Multi-Body Gravitational Approach (MBGA) is robust to noise and missing data while supporting more massive point sets than previous methods (with 10^5 points and more). In various experimental settings, MBGA is shown to outperform several baseline point set alignment approaches in terms of accuracy and runtime. We make our source code available for the community to facilitate the reproducibility of the results.
* Project webpage: http://gvv.mpi-inf.mpg.de/projects/MBGA/