 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGHOST: Fast Category-agnostic Hand-Object Interaction Reconstruction from RGB Videos using Gaussian Splatting
Mar 19, 2026Understanding realistic hand-object interactions from monocular RGB videos is essential for AR/VR, robotics, and embodied AI. Existing methods rely on category-specific templates or heavy computation, yet still produce physically inconsistent hand-object alignment in 3D. We introduce GHOST (Gaussian Hand-Object Splatting), a fast, category-agnostic framework for reconstructing dynamic hand-object interactions using 2D Gaussian Splatting. GHOST represents both hands and objects as dense, view-consistent Gaussian discs and introduces three key innovations: (1) a geometric-prior retrieval and consistency loss that completes occluded object regions, (2) a grasp-aware alignment that refines hand translations and object scale to ensure realistic contact, and (3) a hand-aware background loss that prevents penalizing hand-occluded object regions. GHOST achieves complete, physically consistent, and animatable reconstructions from a single RGB video while running an order of magnitude faster than prior category-agnostic methods. Extensive experiments on ARCTIC, HO3D, and in-the-wild datasets demonstrate state-of-the-art accuracy in 3D reconstruction and 2D rendering quality, establishing GHOST as an efficient and robust solution for realistic hand-object interaction modeling. Code is available at https://github.com/ATAboukhadra/GHOST.
Fast-HaMeR: Boosting Hand Mesh Reconstruction using Knowledge Distillation
Mar 17, 2026Fast and accurate 3D hand reconstruction is essential for real-time applications in VR/AR, human-computer interaction, robotics, and healthcare. Most state-of-the-art methods rely on heavy models, limiting their use on resource-constrained devices like headsets, smartphones, and embedded systems. In this paper, we investigate how the use of lightweight neural networks, combined with Knowledge Distillation, can accelerate complex 3D hand reconstruction models by making them faster and lighter, while maintaining comparable reconstruction accuracy. While our approach is suited for various hand reconstruction frameworks, we focus primarily on boosting the HaMeR model, currently the leading method in terms of reconstruction accuracy. We replace its original ViT-H backbone with lighter alternatives, including MobileNet, MobileViT, ConvNeXt, and ResNet, and evaluate three knowledge distillation strategies: output-level, feature-level, and a hybrid of both. Our experiments show that using lightweight backbones that are only 35% the size of the original achieves 1.5x faster inference speed while preserving similar performance quality with only a minimal accuracy difference of 0.4mm. More specifically, we show how output-level distillation notably improves student performance, while feature-level distillation proves more effective for higher-capacity students. Overall, the findings pave the way for efficient real-world applications on low-power devices. The code and models are publicly available under https://github.com/hunainahmedj/Fast-HaMeR.
SurgeoNet: Realtime 3D Pose Estimation of Articulated Surgical Instruments from Stereo Images using a Synthetically-trained Network
Oct 02, 2024



Surgery monitoring in Mixed Reality (MR) environments has recently received substantial focus due to its importance in image-based decisions, skill assessment, and robot-assisted surgery. Tracking hands and articulated surgical instruments is crucial for the success of these applications. Due to the lack of annotated datasets and the complexity of the task, only a few works have addressed this problem. In this work, we present SurgeoNet, a real-time neural network pipeline to accurately detect and track surgical instruments from a stereo VR view. Our multi-stage approach is inspired by state-of-the-art neural-network architectural design, like YOLO and Transformers. We demonstrate the generalization capabilities of SurgeoNet in challenging real-world scenarios, achieved solely through training on synthetic data. The approach can be easily extended to any new set of articulated surgical instruments. SurgeoNet's code and data are publicly available.
ShapeGraFormer: GraFormer-Based Network for Hand-Object Reconstruction from a Single Depth Map
Oct 18, 2023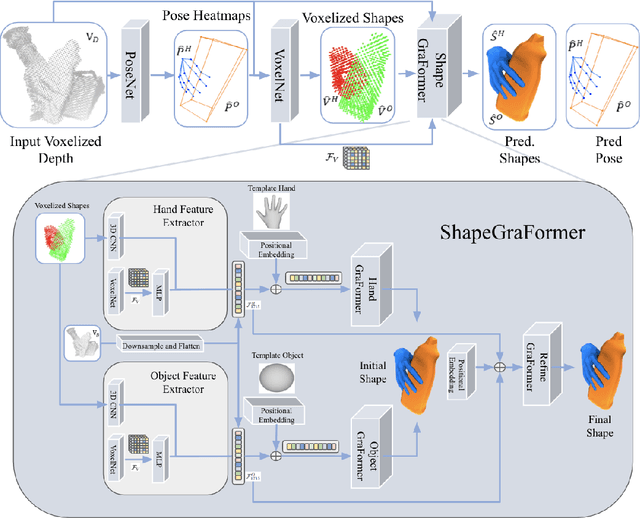



3D reconstruction of hand-object manipulations is important for emulating human actions. Most methods dealing with challenging object manipulation scenarios, focus on hands reconstruction in isolation, ignoring physical and kinematic constraints due to object contact. Some approaches produce more realistic results by jointly reconstructing 3D hand-object interactions. However, they focus on coarse pose estimation or rely upon known hand and object shapes. We propose the first approach for realistic 3D hand-object shape and pose reconstruction from a single depth map. Unlike previous work, our voxel-based reconstruction network regresses the vertex coordinates of a hand and an object and reconstructs more realistic interaction. Our pipeline additionally predicts voxelized hand-object shapes, having a one-to-one mapping to the input voxelized depth. Thereafter, we exploit the graph nature of the hand and object shapes, by utilizing the recent GraFormer network with positional embedding to reconstruct shapes from template meshes. In addition, we show the impact of adding another GraFormer component that refines the reconstructed shapes based on the hand-object interactions and its ability to reconstruct more accurate object shapes. We perform an extensive evaluation on the HO-3D and DexYCB datasets and show that our method outperforms existing approaches in hand reconstruction and produces plausible reconstructions for the objects
THOR-Net: End-to-end Graformer-based Realistic Two Hands and Object Reconstruction with Self-supervision
Oct 25, 2022



Realistic reconstruction of two hands interacting with objects is a new and challenging problem that is essential for building personalized Virtual and Augmented Reality environments. Graph Convolutional networks (GCNs) allow for the preservation of the topologies of hands poses and shapes by modeling them as a graph. In this work, we propose the THOR-Net which combines the power of GCNs, Transformer, and self-supervision to realistically reconstruct two hands and an object from a single RGB image. Our network comprises two stages; namely the features extraction stage and the reconstruction stage. In the features extraction stage, a Keypoint RCNN is used to extract 2D poses, features maps, heatmaps, and bounding boxes from a monocular RGB image. Thereafter, this 2D information is modeled as two graphs and passed to the two branches of the reconstruction stage. The shape reconstruction branch estimates meshes of two hands and an object using our novel coarse-to-fine GraFormer shape network. The 3D poses of the hands and objects are reconstructed by the other branch using a GraFormer network. Finally, a self-supervised photometric loss is used to directly regress the realistic textured of each vertex in the hands' meshes. Our approach achieves State-of-the-art results in Hand shape estimation on the HO-3D dataset (10.0mm) exceeding ArtiBoost (10.8mm). It also surpasses other methods in hand pose estimation on the challenging two hands and object (H2O) dataset by 5mm on the left-hand pose and 1 mm on the right-hand pose.
HandVoxNet++: 3D Hand Shape and Pose Estimation using Voxel-Based Neural Networks
Jul 02, 2021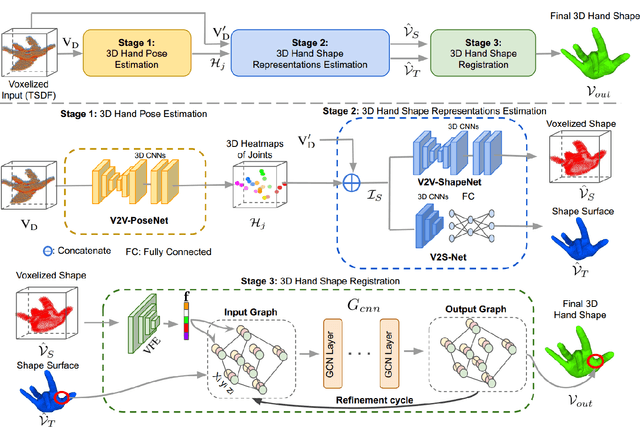
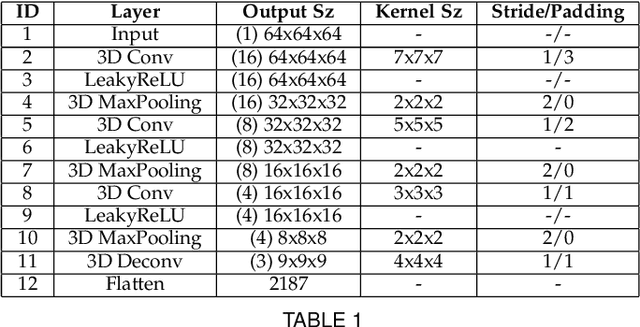

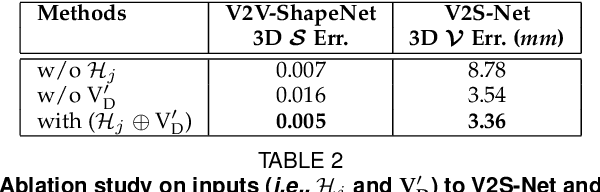
3D hand shape and pose estimation from a single depth map is a new and challenging computer vision problem with many applications. Existing methods addressing it directly regress hand meshes via 2D convolutional neural networks, which leads to artifacts due to perspective distortions in the images. To address the limitations of the existing methods, we develop HandVoxNet++, i.e., a voxel-based deep network with 3D and graph convolutions trained in a fully supervised manner. The input to our network is a 3D voxelized-depth-map-based on the truncated signed distance function (TSDF). HandVoxNet++ relies on two hand shape representations. The first one is the 3D voxelized grid of hand shape, which does not preserve the mesh topology and which is the most accurate representation. The second representation is the hand surface that preserves the mesh topology. We combine the advantages of both representations by aligning the hand surface to the voxelized hand shape either with a new neural Graph-Convolutions-based Mesh Registration (GCN-MeshReg) or classical segment-wise Non-Rigid Gravitational Approach (NRGA++) which does not rely on training data. In extensive evaluations on three public benchmarks, i.e., SynHand5M, depth-based HANDS19 challenge and HO-3D, the proposed HandVoxNet++ achieves the state-of-the-art performance. In this journal extension of our previous approach presented at CVPR 2020, we gain 41.09% and 13.7% higher shape alignment accuracy on SynHand5M and HANDS19 datasets, respectively. Our method is ranked first on the HANDS19 challenge dataset (Task 1: Depth-Based 3D Hand Pose Estimation) at the moment of the submission of our results to the portal in August 2020.
HandVoxNet: Deep Voxel-Based Network for 3D Hand Shape and Pose Estimation from a Single Depth Map
Apr 03, 2020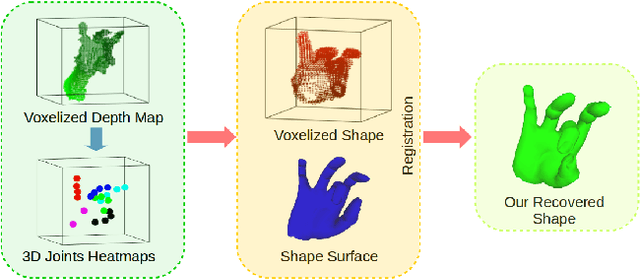

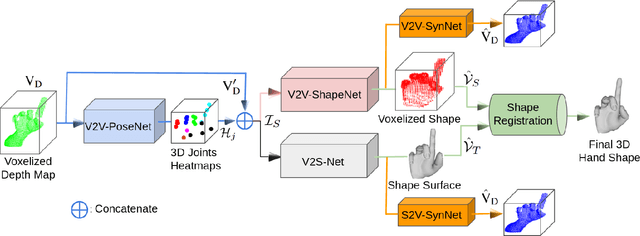

3D hand shape and pose estimation from a single depth map is a new and challenging computer vision problem with many applications. The state-of-the-art methods directly regress 3D hand meshes from 2D depth images via 2D convolutional neural networks, which leads to artefacts in the estimations due to perspective distortions in the images. In contrast, we propose a novel architecture with 3D convolutions trained in a weakly-supervised manner. The input to our method is a 3D voxelized depth map, and we rely on two hand shape representations. The first one is the 3D voxelized grid of the shape which is accurate but does not preserve the mesh topology and the number of mesh vertices. The second representation is the 3D hand surface which is less accurate but does not suffer from the limitations of the first representation. We combine the advantages of these two representations by registering the hand surface to the voxelized hand shape. In the extensive experiments, the proposed approach improves over the state of the art by 47.8% on the SynHand5M dataset. Moreover, our augmentation policy for voxelized depth maps further enhances the accuracy of 3D hand pose estimation on real data. Our method produces visually more reasonable and realistic hand shapes on NYU and BigHand2.2M datasets compared to the existing approaches.
Structure from Articulated Motion: An Accurate and Stable Monocular 3D Reconstruction Approach without Training Data
May 12, 2019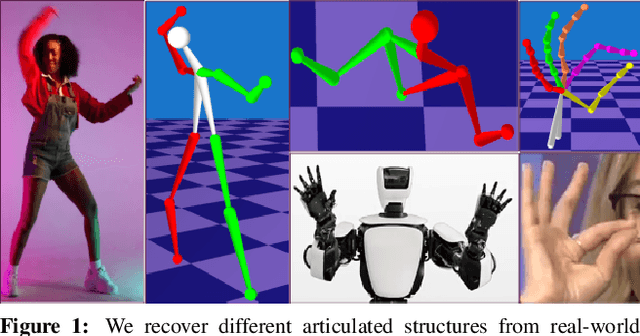

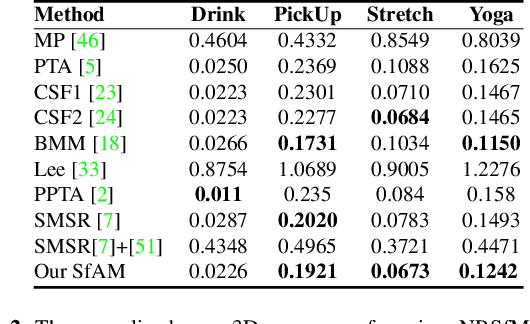
Recovery of articulated 3D structure from 2D observations is a challenging computer vision problem with many applications. Current learning-based approaches achieve state-of-the-art performance on public benchmarks but are limited to the specific types of objects and motions covered by the training datasets. Model-based approaches do not rely on training data but show lower accuracy on public benchmarks. In this paper, we introduce a new model-based method called Structure from Articulated Motion (SfAM). SfAM includes a new articulated structure term which ensures consistency of bone lengths throughout the whole image sequence and recovers a scene-specific configuration of the articulated structure. The proposed approach is highly robust to noisy 2D annotations, generalizes to arbitrary objects and motion types and does not rely on training data. It achieves state-of-the-art accuracy and scales across different scenarios which is shown in extensive experiments on public benchmarks and real video sequences.
DeepHPS: End-to-end Estimation of 3D Hand Pose and Shape by Learning from Synthetic Depth
Aug 28, 2018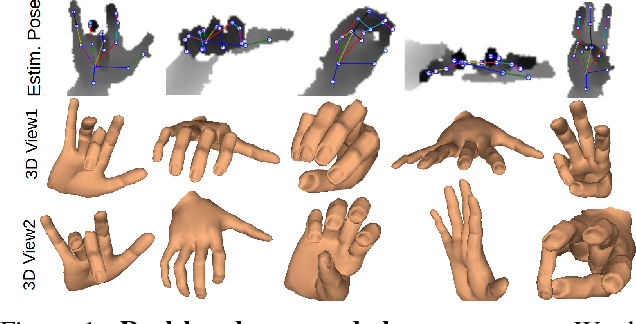
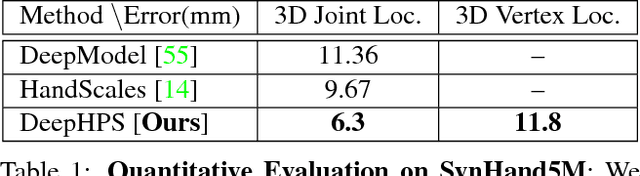
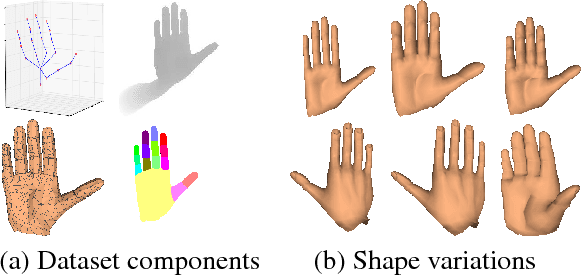
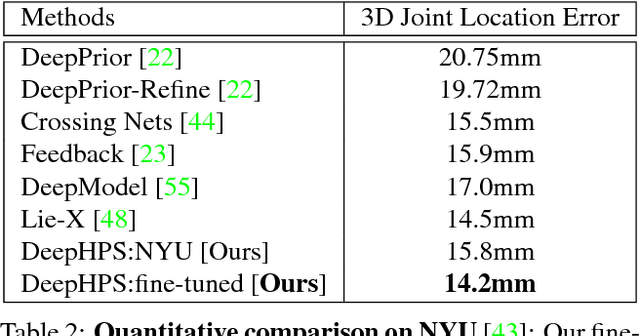
Articulated hand pose and shape estimation is an important problem for vision-based applications such as augmented reality and animation. In contrast to the existing methods which optimize only for joint positions, we propose a fully supervised deep network which learns to jointly estimate a full 3D hand mesh representation and pose from a single depth image. To this end, a CNN architecture is employed to estimate parametric representations i.e. hand pose, bone scales and complex shape parameters. Then, a novel hand pose and shape layer, embedded inside our deep framework, produces 3D joint positions and hand mesh. Lack of sufficient training data with varying hand shapes limits the generalized performance of learning based methods. Also, manually annotating real data is suboptimal. Therefore, we present SynHand5M: a million-scale synthetic dataset with accurate joint annotations, segmentation masks and mesh files of depth maps. Among model based learning (hybrid) methods, we show improved results on our dataset and two of the public benchmarks i.e. NYU and ICVL. Also, by employing a joint training strategy with real and synthetic data, we recover 3D hand mesh and pose from real images in 3.7ms.
Simultaneous Hand Pose and Skeleton Bone-Lengths Estimation from a Single Depth Image
Dec 08, 2017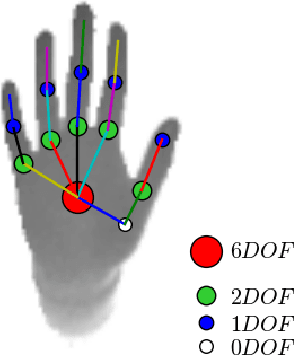
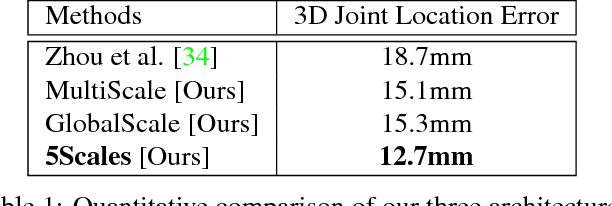
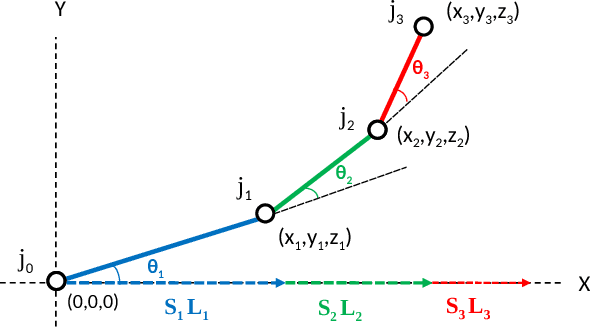

Articulated hand pose estimation is a challenging task for human-computer interaction. The state-of-the-art hand pose estimation algorithms work only with one or a few subjects for which they have been calibrated or trained. Particularly, the hybrid methods based on learning followed by model fitting or model based deep learning do not explicitly consider varying hand shapes and sizes. In this work, we introduce a novel hybrid algorithm for estimating the 3D hand pose as well as bone-lengths of the hand skeleton at the same time, from a single depth image. The proposed CNN architecture learns hand pose parameters and scale parameters associated with the bone-lengths simultaneously. Subsequently, a new hybrid forward kinematics layer employs both parameters to estimate 3D joint positions of the hand. For end-to-end training, we combine three public datasets NYU, ICVL and MSRA-2015 in one unified format to achieve large variation in hand shapes and sizes. Among hybrid methods, our method shows improved accuracy over the state-of-the-art on the combined dataset and the ICVL dataset that contain multiple subjects. Also, our algorithm is demonstrated to work well with unseen images.