 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgeoNet: Realtime 3D Pose Estimation of Articulated Surgical Instruments from Stereo Images using a Synthetically-trained Network
Oct 02, 2024



Surgery monitoring in Mixed Reality (MR) environments has recently received substantial focus due to its importance in image-based decisions, skill assessment, and robot-assisted surgery. Tracking hands and articulated surgical instruments is crucial for the success of these applications. Due to the lack of annotated datasets and the complexity of the task, only a few works have addressed this problem. In this work, we present SurgeoNet, a real-time neural network pipeline to accurately detect and track surgical instruments from a stereo VR view. Our multi-stage approach is inspired by state-of-the-art neural-network architectural design, like YOLO and Transformers. We demonstrate the generalization capabilities of SurgeoNet in challenging real-world scenarios, achieved solely through training on synthetic data. The approach can be easily extended to any new set of articulated surgical instruments. SurgeoNet's code and data are publicly available.
DELO: Deep Evidential LiDAR Odometry using Partial Optimal Transport
Aug 14, 2023



Accurate, robust, and real-time LiDAR-based odometry (LO) is imperative for many applications like robot navigation, globally consistent 3D scene map reconstruction, or safe motion-planning. Though LiDAR sensor is known for its precise range measurement, the non-uniform and uncertain point sampling density induce structural inconsistencies. Hence, existing supervised and unsupervised point set registration methods fail to establish one-to-one matching correspondences between LiDAR frames. We introduce a novel deep learning-based real-time (approx. 35-40ms per frame) LO method that jointly learns accurate frame-to-frame correspondences and model's predictive uncertainty (PU) as evidence to safe-guard LO predictions. In this work, we propose (i) partial optimal transportation of LiDAR feature descriptor for robust LO estimation, (ii) joint learning of predictive uncertainty while learning odometry over driving sequences, and (iii) demonstrate how PU can serve as evidence for necessary pose-graph optimization when LO network is either under or over confident. We evaluate our method on KITTI dataset and show competitive performance, even superior generalization ability over recent state-of-the-art approaches. Source codes are available.
INV-Flow2PoseNet: Light-Resistant Rigid Object Pose from Optical Flow of RGB-D Images using Images, Normals and Vertices
Sep 14, 2022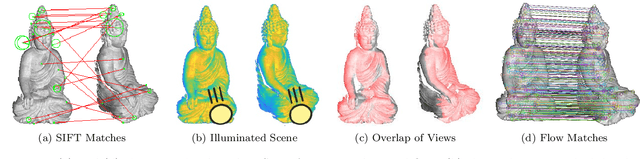
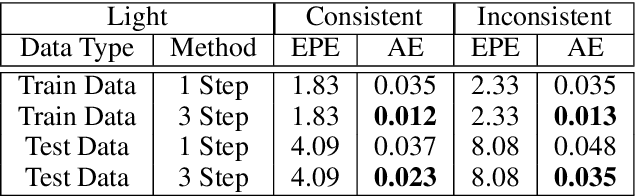

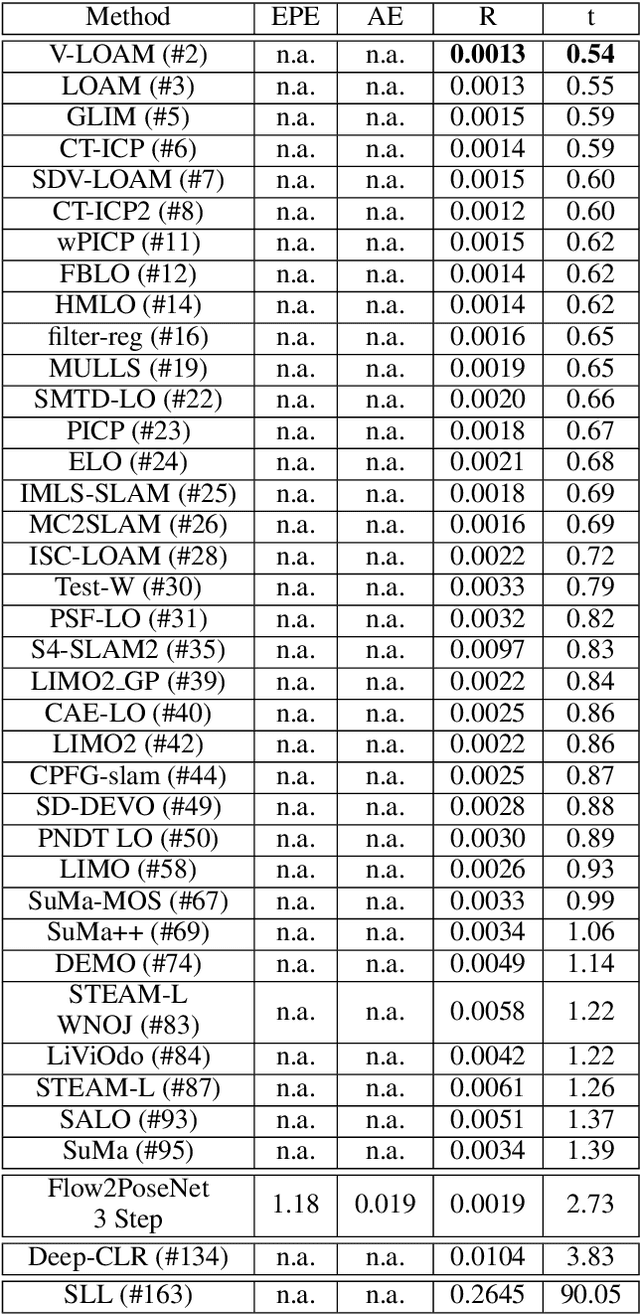
This paper presents a novel architecture for simultaneous estimation of highly accurate optical flows and rigid scene transformations for difficult scenarios where the brightness assumption is violated by strong shading changes. In the case of rotating objects or moving light sources, such as those encountered for driving cars in the dark, the scene appearance often changes significantly from one view to the next. Unfortunately, standard methods for calculating optical flows or poses are based on the expectation that the appearance of features in the scene remain constant between views. These methods may fail frequently in the investigated cases. The presented method fuses texture and geometry information by combining image, vertex and normal data to compute an illumination-invariant optical flow. By using a coarse-to-fine strategy, globally anchored optical flows are learned, reducing the impact of erroneous shading-based pseudo-correspondences. Based on the learned optical flows, a second architecture is proposed that predicts robust rigid transformations from the warped vertex and normal maps. Particular attention is payed to situations with strong rotations, which often cause such shading changes. Therefore a 3-step procedure is proposed that profitably exploits correlations between the normals and vertices. The method has been evaluated on a newly created dataset containing both synthetic and real data with strong rotations and shading effects. This data represents the typical use case in 3D reconstruction, where the object often rotates in large steps between the partial reconstructions. Additionally, we apply the method to the well-known Kitti Odometry dataset. Even if, due to fulfillment of the brighness assumption, this is not the typical use case of the method, the applicability to standard situations and the relation to other methods is therefore established.
The Gesture Authoring Space: Authoring Customised Hand Gestures for Grasping Virtual Objects in Immersive Virtual Environments
Jul 03, 2022

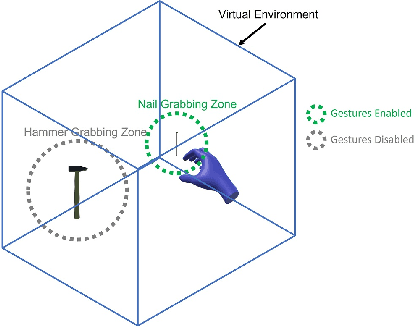

Natural user interfaces are on the rise. Manufacturers for Augmented, Virtual, and Mixed Reality head mounted displays are increasingly integrating new sensors into their consumer grade products, allowing gesture recognition without additional hardware. This offers new possibilities for bare handed interaction within virtual environments. This work proposes a hand gesture authoring tool for object specific grab gestures allowing virtual objects to be grabbed as in the real world. The presented solution uses template matching for gesture recognition and requires no technical knowledge to design and create custom tailored hand gestures. In a user study, the proposed approach is compared with the pinch gesture and the controller for grasping virtual objects. The different grasping techniques are compared in terms of accuracy, task completion time, usability, and naturalness. The study showed that gestures created with the proposed approach are perceived by users as a more natural input modality than the others.
Learning Effect of Lay People in Gesture-Based Locomotion in Virtual Reality
Jun 16, 2022Locomotion in Virtual Reality (VR) is an important part of VR applications. Many scientists are enriching the community with different variations that enable locomotion in VR. Some of the most promising methods are gesture-based and do not require additional handheld hardware. Recent work focused mostly on user preference and performance of the different locomotion techniques. This ignores the learning effect that users go through while new methods are being explored. In this work, it is investigated whether and how quickly users can adapt to a hand gesture-based locomotion system in VR. Four different locomotion techniques are implemented and tested by participants. The goal of this paper is twofold: First, it aims to encourage researchers to consider the learning effect in their studies. Second, this study aims to provide insight into the learning effect of users in gesture-based systems.
Comparing Controller With the Hand Gestures Pinch and Grab for Picking Up and Placing Virtual Objects
Feb 22, 2022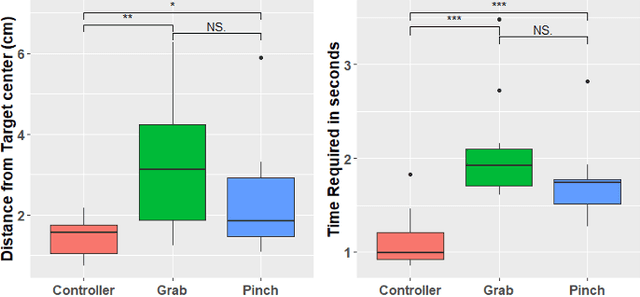
Grabbing virtual objects is one of the essential tasks for Augmented, Virtual, and Mixed Reality applications. Modern applications usually use a simple pinch gesture for grabbing and moving objects. However, picking up objects by pinching has disadvantages. It can be an unnatural gesture to pick up objects and prevents the implementation of other gestures which would be performed with thumb and index. Therefore it is not the optimal choice for many applications. In this work, different implementations for grabbing and placing virtual objects are proposed and compared. Performance and accuracy of the proposed techniques are measured and compared.
MutualEyeContact: A conversation analysis tool with focus on eye contact
Jul 09, 2021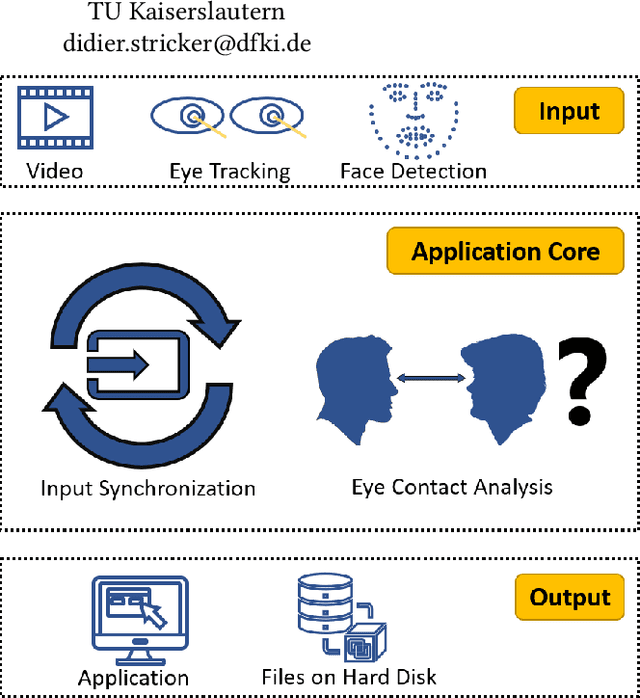
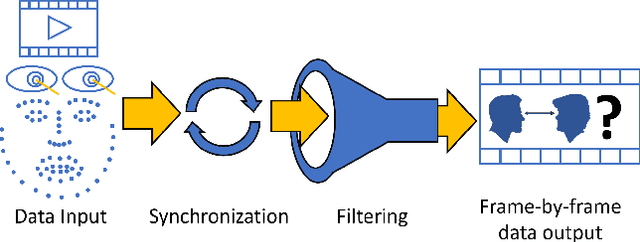

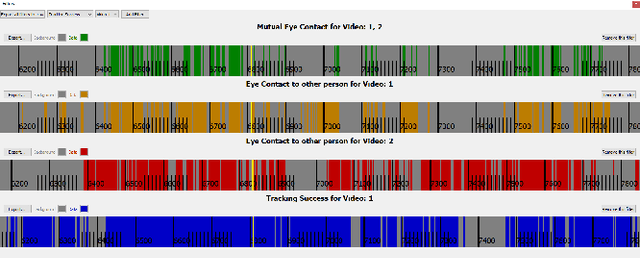
Eye contact between individuals is particularly important for understanding human behaviour. To further investigate the importance of eye contact in social interactions, portable eye tracking technology seems to be a natural choice. However, the analysis of available data can become quite complex. Scientists need data that is calculated quickly and accurately. Additionally, the relevant data must be automatically separated to save time. In this work, we propose a tool called MutualEyeContact which excels in those tasks and can help scientists to understand the importance of (mutual) eye contact in social interactions. We combine state-of-the-art eye tracking with face recognition based on machine learning and provide a tool for analysis and visualization of social interaction sessions. This work is a joint collaboration of computer scientists and cognitive scientists. It combines the fields of social and behavioural science with computer vision and deep learning.
Calibration and Auto-Refinement for Light Field Cameras
Jun 11, 2021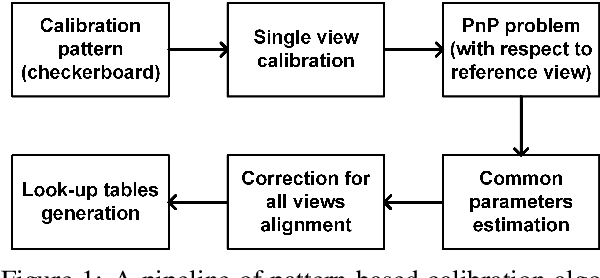

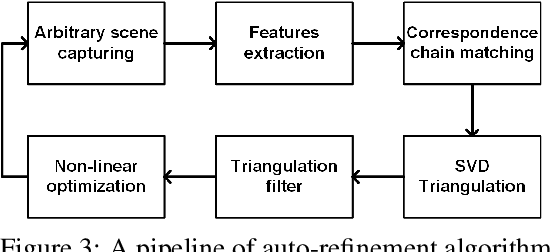
The ability to create an accurate three-dimensional reconstruction of a captured scene draws attention to the principles of light fields. This paper presents an approach for light field camera calibration and rectification, based on pairwise pattern-based parameters extraction. It is followed by a correspondence-based algorithm for camera parameters refinement from arbitrary scenes using the triangulation filter and nonlinear optimization. The effectiveness of our approach is validated on both real and synthetic data.
RPSRNet: End-to-End Trainable Rigid Point Set Registration Network using Barnes-Hut $2^D$-Tree Representation
Apr 12, 2021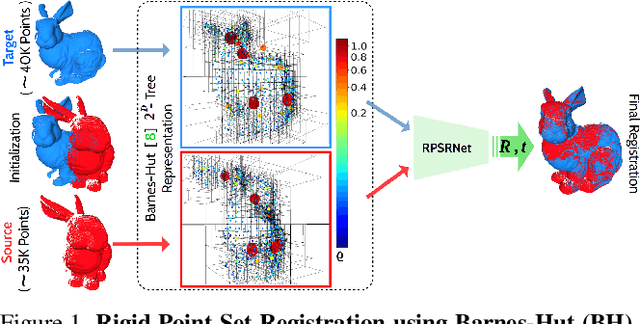
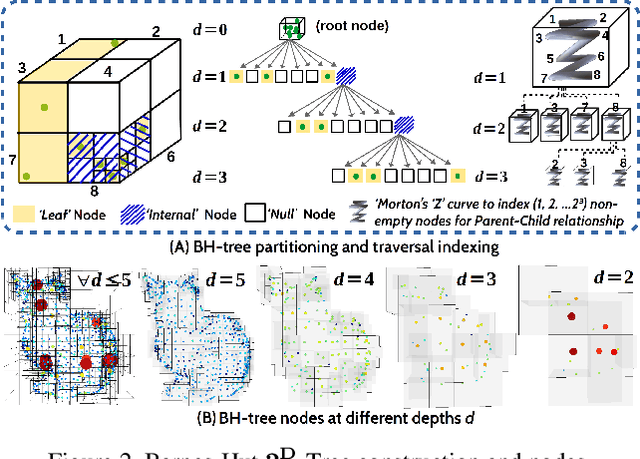

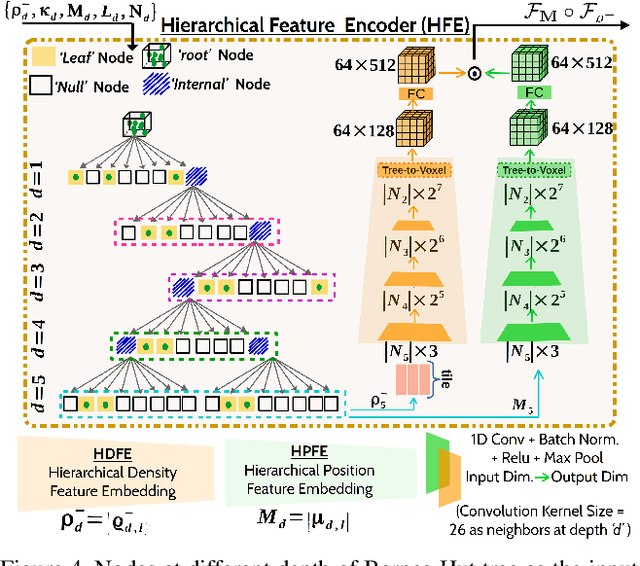
We propose RPSRNet - a novel end-to-end trainable deep neural network for rigid point set registration. For this task, we use a novel $2^D$-tree representation for the input point sets and a hierarchical deep feature embedding in the neural network. An iterative transformation refinement module in our network boosts the feature matching accuracy in the intermediate stages. We achieve an inference speed of 12-15ms to register a pair of input point clouds as large as 250K. Extensive evaluation on (i) KITTI LiDAR odometry and (ii) ModelNet-40 datasets shows that our method outperforms prior state-of-the-art methods - e.g., on the KITTI data set, DCP-v2 by1.3 and 1.5 times, and PointNetLK by 1.8 and 1.9 times better rotational and translational accuracy respectively. Evaluation on ModelNet40 shows that RPSRNet is more robust than other benchmark methods when the samples contain a significant amount of noise and other disturbances. RPSRNet accurately registers point clouds with non-uniform sampling densities, e.g., LiDAR data, which cannot be processed by many existing deep-learning-based registration methods.
SALT: A Semi-automatic Labeling Tool for RGB-D Video Sequences
Feb 22, 2021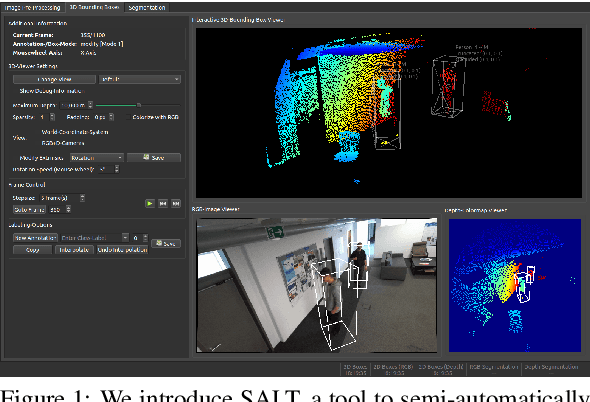

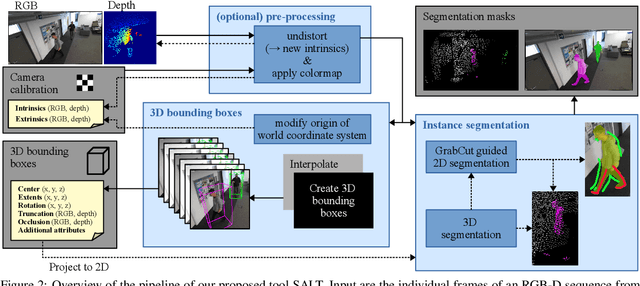
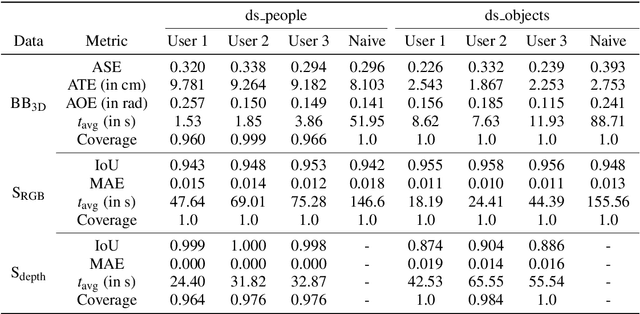
Large labeled data sets are one of the essential basics of modern deep learning techniques. Therefore, there is an increasing need for tools that allow to label large amounts of data as intuitively as possible. In this paper, we introduce SALT, a tool to semi-automatically annotate RGB-D video sequences to generate 3D bounding boxes for full six Degrees of Freedom (DoF) object poses, as well as pixel-level instance segmentation masks for both RGB and depth. Besides bounding box propagation through various interpolation techniques, as well as algorithmically guided instance segmentation, our pipeline also provides built-in pre-processing functionalities to facilitate the data set creation process. By making full use of SALT, annotation time can be reduced by a factor of up to 33.95 for bounding box creation and 8.55 for RGB segmentation without compromising the quality of the automatically generated ground truth.
* VISAPP 2021 full paper (9 pages, 6 figures), published by SciTePress: https://www.scitepress.org/PublicationsDetail.aspx?ID=ywQZ3GZrka8=&t=1