 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINV-Flow2PoseNet: Light-Resistant Rigid Object Pose from Optical Flow of RGB-D Images using Images, Normals and Vertices
Sep 14, 2022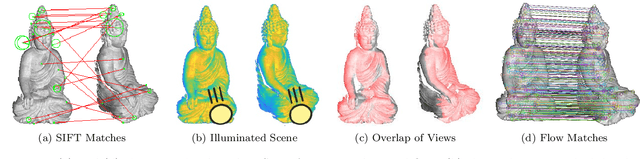
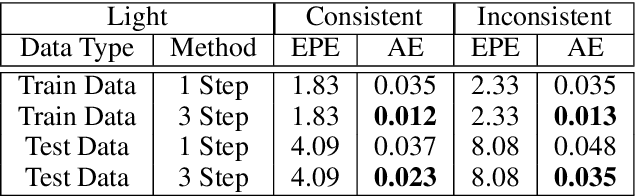

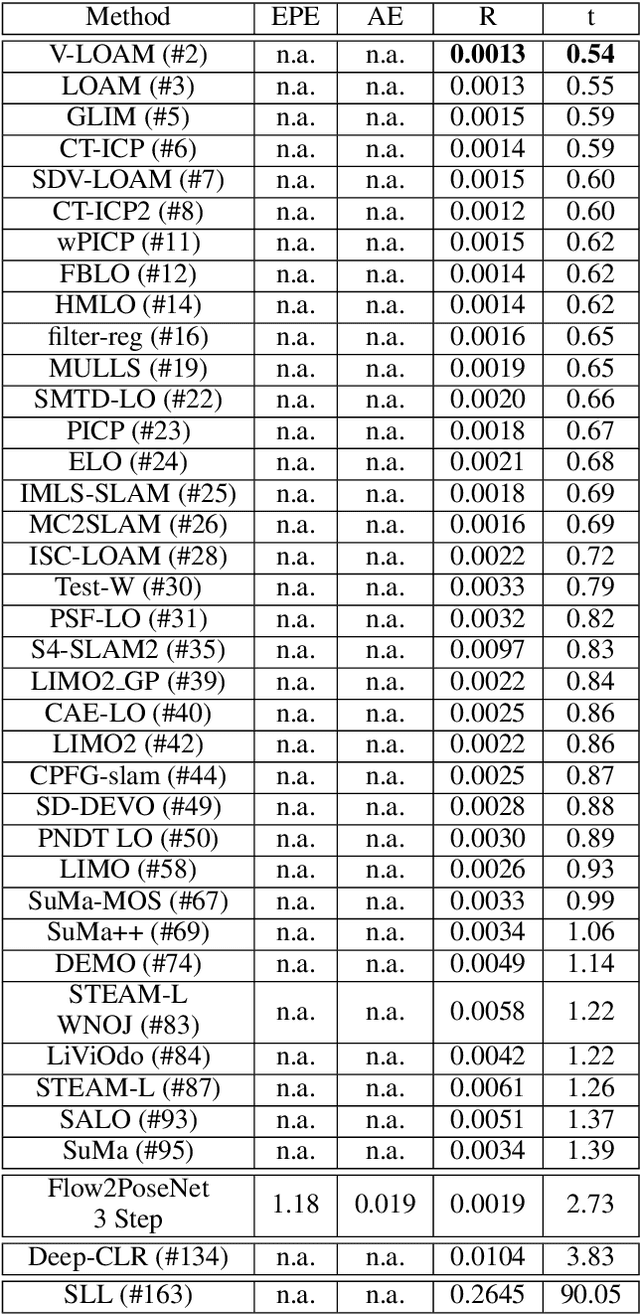
This paper presents a novel architecture for simultaneous estimation of highly accurate optical flows and rigid scene transformations for difficult scenarios where the brightness assumption is violated by strong shading changes. In the case of rotating objects or moving light sources, such as those encountered for driving cars in the dark, the scene appearance often changes significantly from one view to the next. Unfortunately, standard methods for calculating optical flows or poses are based on the expectation that the appearance of features in the scene remain constant between views. These methods may fail frequently in the investigated cases. The presented method fuses texture and geometry information by combining image, vertex and normal data to compute an illumination-invariant optical flow. By using a coarse-to-fine strategy, globally anchored optical flows are learned, reducing the impact of erroneous shading-based pseudo-correspondences. Based on the learned optical flows, a second architecture is proposed that predicts robust rigid transformations from the warped vertex and normal maps. Particular attention is payed to situations with strong rotations, which often cause such shading changes. Therefore a 3-step procedure is proposed that profitably exploits correlations between the normals and vertices. The method has been evaluated on a newly created dataset containing both synthetic and real data with strong rotations and shading effects. This data represents the typical use case in 3D reconstruction, where the object often rotates in large steps between the partial reconstructions. Additionally, we apply the method to the well-known Kitti Odometry dataset. Even if, due to fulfillment of the brighness assumption, this is not the typical use case of the method, the applicability to standard situations and the relation to other methods is therefore established.
ZebraPose: Coarse to Fine Surface Encoding for 6DoF Object Pose Estimation
Mar 29, 2022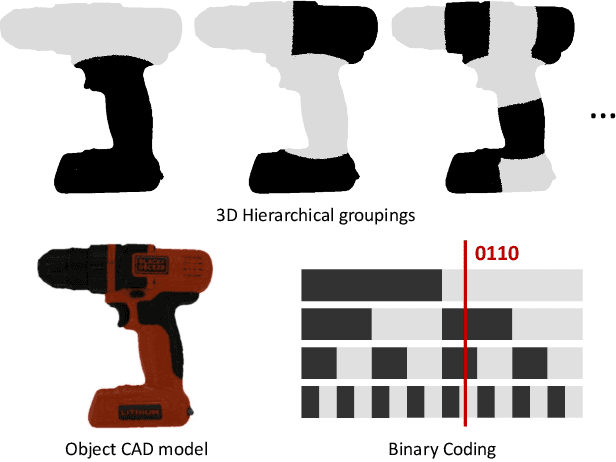
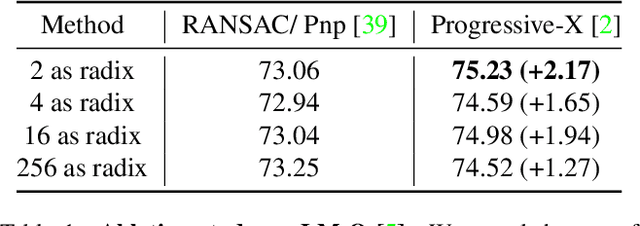
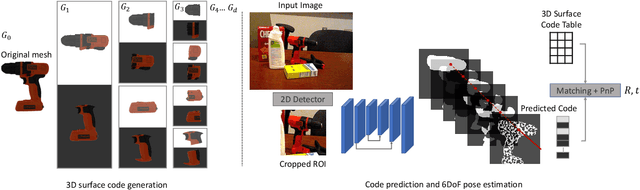

Establishing correspondences from image to 3D has been a key task of 6DoF object pose estimation for a long time. To predict pose more accurately, deeply learned dense maps replaced sparse templates. Dense methods also improved pose estimation in the presence of occlusion. More recently researchers have shown improvements by learning object fragments as segmentation. In this work, we present a discrete descriptor, which can represent the object surface densely. By incorporating a hierarchical binary grouping, we can encode the object surface very efficiently. Moreover, we propose a coarse to fine training strategy, which enables fine-grained correspondence prediction. Finally, by matching predicted codes with object surface and using a PnP solver, we estimate the 6DoF pose. Results on the public LM-O and YCB-V datasets show major improvement over the state of the art w.r.t. ADD(-S) metric, even surpassing RGB-D based methods in some cases.
Accurate 3D Reconstruction of Dynamic Scenes from Monocular Image Sequences with Severe Occlusions
Dec 20, 2017

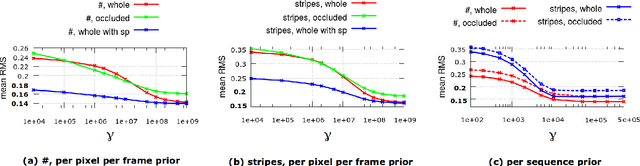

The paper introduces an accurate solution to dense orthographic Non-Rigid Structure from Motion (NRSfM) in scenarios with severe occlusions or, likewise, inaccurate correspondences. We integrate a shape prior term into variational optimisation framework. It allows to penalize irregularities of the time-varying structure on the per-pixel level if correspondence quality indicator such as an occlusion tensor is available. We make a realistic assumption that several non-occluded views of the scene are sufficient to estimate an initial shape prior, though the entire observed scene may exhibit non-rigid deformations. Experiments on synthetic and real image data show that the proposed framework significantly outperforms state of the art methods for correspondence establishment in combination with the state of the art NRSfM methods. Together with the profound insights into optimisation methods, implementation details for heterogeneous platforms are provided.