 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurgeoNet: Realtime 3D Pose Estimation of Articulated Surgical Instruments from Stereo Images using a Synthetically-trained Network
Oct 02, 2024



Surgery monitoring in Mixed Reality (MR) environments has recently received substantial focus due to its importance in image-based decisions, skill assessment, and robot-assisted surgery. Tracking hands and articulated surgical instruments is crucial for the success of these applications. Due to the lack of annotated datasets and the complexity of the task, only a few works have addressed this problem. In this work, we present SurgeoNet, a real-time neural network pipeline to accurately detect and track surgical instruments from a stereo VR view. Our multi-stage approach is inspired by state-of-the-art neural-network architectural design, like YOLO and Transformers. We demonstrate the generalization capabilities of SurgeoNet in challenging real-world scenarios, achieved solely through training on synthetic data. The approach can be easily extended to any new set of articulated surgical instruments. SurgeoNet's code and data are publicly available.
ShapeGraFormer: GraFormer-Based Network for Hand-Object Reconstruction from a Single Depth Map
Oct 18, 2023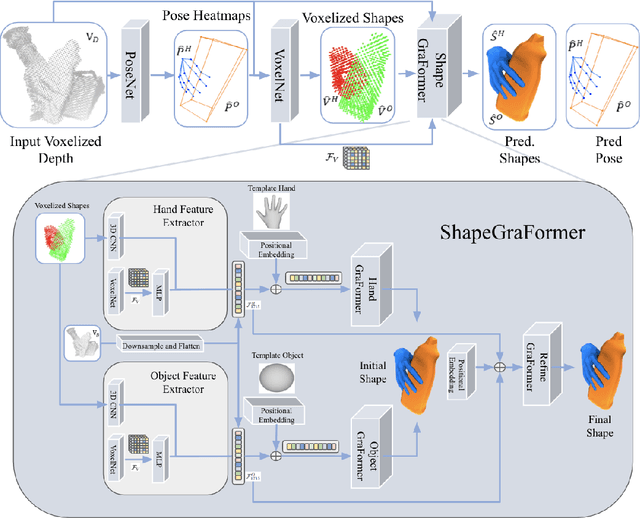



3D reconstruction of hand-object manipulations is important for emulating human actions. Most methods dealing with challenging object manipulation scenarios, focus on hands reconstruction in isolation, ignoring physical and kinematic constraints due to object contact. Some approaches produce more realistic results by jointly reconstructing 3D hand-object interactions. However, they focus on coarse pose estimation or rely upon known hand and object shapes. We propose the first approach for realistic 3D hand-object shape and pose reconstruction from a single depth map. Unlike previous work, our voxel-based reconstruction network regresses the vertex coordinates of a hand and an object and reconstructs more realistic interaction. Our pipeline additionally predicts voxelized hand-object shapes, having a one-to-one mapping to the input voxelized depth. Thereafter, we exploit the graph nature of the hand and object shapes, by utilizing the recent GraFormer network with positional embedding to reconstruct shapes from template meshes. In addition, we show the impact of adding another GraFormer component that refines the reconstructed shapes based on the hand-object interactions and its ability to reconstruct more accurate object shapes. We perform an extensive evaluation on the HO-3D and DexYCB datasets and show that our method outperforms existing approaches in hand reconstruction and produces plausible reconstructions for the objects
THOR-Net: End-to-end Graformer-based Realistic Two Hands and Object Reconstruction with Self-supervision
Oct 25, 2022



Realistic reconstruction of two hands interacting with objects is a new and challenging problem that is essential for building personalized Virtual and Augmented Reality environments. Graph Convolutional networks (GCNs) allow for the preservation of the topologies of hands poses and shapes by modeling them as a graph. In this work, we propose the THOR-Net which combines the power of GCNs, Transformer, and self-supervision to realistically reconstruct two hands and an object from a single RGB image. Our network comprises two stages; namely the features extraction stage and the reconstruction stage. In the features extraction stage, a Keypoint RCNN is used to extract 2D poses, features maps, heatmaps, and bounding boxes from a monocular RGB image. Thereafter, this 2D information is modeled as two graphs and passed to the two branches of the reconstruction stage. The shape reconstruction branch estimates meshes of two hands and an object using our novel coarse-to-fine GraFormer shape network. The 3D poses of the hands and objects are reconstructed by the other branch using a GraFormer network. Finally, a self-supervised photometric loss is used to directly regress the realistic textured of each vertex in the hands' meshes. Our approach achieves State-of-the-art results in Hand shape estimation on the HO-3D dataset (10.0mm) exceeding ArtiBoost (10.8mm). It also surpasses other methods in hand pose estimation on the challenging two hands and object (H2O) dataset by 5mm on the left-hand pose and 1 mm on the right-hand pose.
General Automatic Human Shape and Motion Capture Using Volumetric Contour Cues
Oct 21, 2016

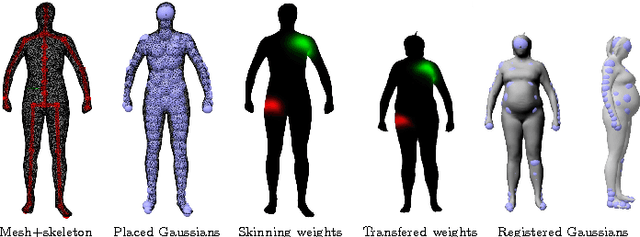

Markerless motion capture algorithms require a 3D body with properly personalized skeleton dimension and/or body shape and appearance to successfully track a person. Unfortunately, many tracking methods consider model personalization a different problem and use manual or semi-automatic model initialization, which greatly reduces applicability. In this paper, we propose a fully automatic algorithm that jointly creates a rigged actor model commonly used for animation - skeleton, volumetric shape, appearance, and optionally a body surface - and estimates the actor's motion from multi-view video input only. The approach is rigorously designed to work on footage of general outdoor scenes recorded with very few cameras and without background subtraction. Our method uses a new image formation model with analytic visibility and analytically differentiable alignment energy. For reconstruction, 3D body shape is approximated as Gaussian density field. For pose and shape estimation, we minimize a new edge-based alignment energy inspired by volume raycasting in an absorbing medium. We further propose a new statistical human body model that represents the body surface, volumetric Gaussian density, as well as variability in skeleton shape. Given any multi-view sequence, our method jointly optimizes the pose and shape parameters of this model fully automatically in a spatiotemporal way.
Model-based Outdoor Performance Capture
Oct 21, 2016
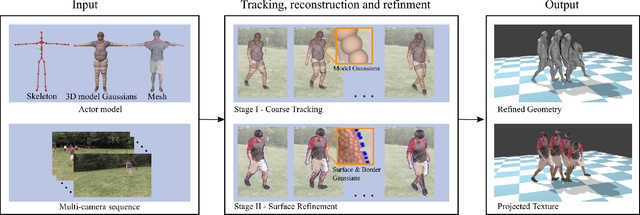

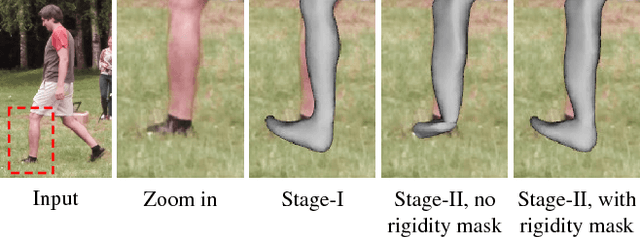
We propose a new model-based method to accurately reconstruct human performances captured outdoors in a multi-camera setup. Starting from a template of the actor model, we introduce a new unified implicit representation for both, articulated skeleton tracking and nonrigid surface shape refinement. Our method fits the template to unsegmented video frames in two stages - first, the coarse skeletal pose is estimated, and subsequently non-rigid surface shape and body pose are jointly refined. Particularly for surface shape refinement we propose a new combination of 3D Gaussians designed to align the projected model with likely silhouette contours without explicit segmentation or edge detection. We obtain reconstructions of much higher quality in outdoor settings than existing methods, and show that we are on par with state-of-the-art methods on indoor scenes for which they were designed
A Versatile Scene Model with Differentiable Visibility Applied to Generative Pose Estimation
Feb 11, 2016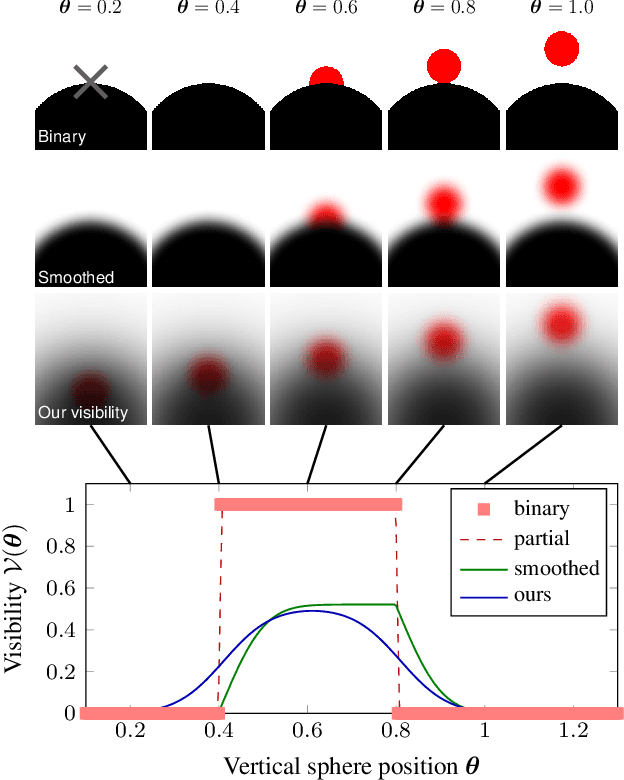
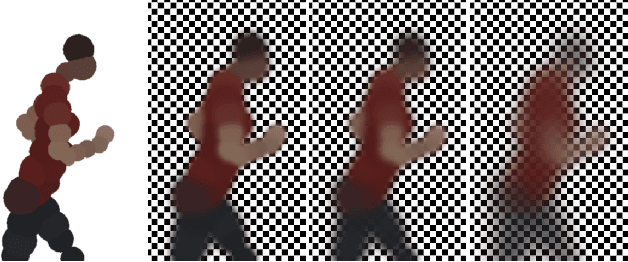


Generative reconstruction methods compute the 3D configuration (such as pose and/or geometry) of a shape by optimizing the overlap of the projected 3D shape model with images. Proper handling of occlusions is a big challenge, since the visibility function that indicates if a surface point is seen from a camera can often not be formulated in closed form, and is in general discrete and non-differentiable at occlusion boundaries. We present a new scene representation that enables an analytically differentiable closed-form formulation of surface visibility. In contrast to previous methods, this yields smooth, analytically differentiable, and efficient to optimize pose similarity energies with rigorous occlusion handling, fewer local minima, and experimentally verified improved convergence of numerical optimization. The underlying idea is a new image formation model that represents opaque objects by a translucent medium with a smooth Gaussian density distribution which turns visibility into a smooth phenomenon. We demonstrate the advantages of our versatile scene model in several generative pose estimation problems, namely marker-less multi-object pose estimation, marker-less human motion capture with few cameras, and image-based 3D geometry estimation.
Efficient Multi-view Performance Capture of Fine-Scale Surface Detail
Feb 05, 2016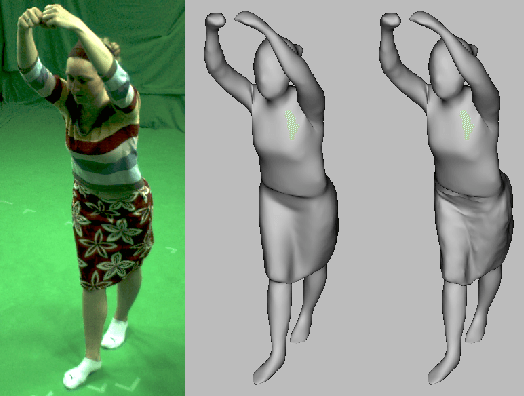
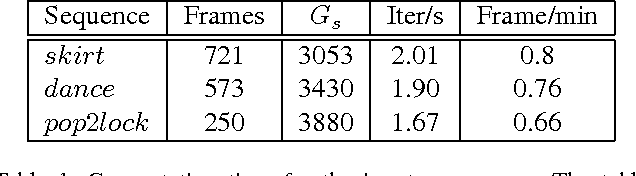

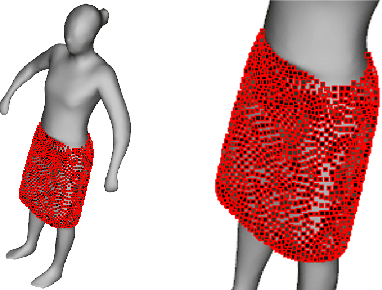
We present a new effective way for performance capture of deforming meshes with fine-scale time-varying surface detail from multi-view video. Our method builds up on coarse 4D surface reconstructions, as obtained with commonly used template-based methods. As they only capture models of coarse-to-medium scale detail, fine scale deformation detail is often done in a second pass by using stereo constraints, features, or shading-based refinement. In this paper, we propose a new effective and stable solution to this second step. Our framework creates an implicit representation of the deformable mesh using a dense collection of 3D Gaussian functions on the surface, and a set of 2D Gaussians for the images. The fine scale deformation of all mesh vertices that maximizes photo-consistency can be efficiently found by densely optimizing a new model-to-image consistency energy on all vertex positions. A principal advantage is that our problem formulation yields a smooth closed form energy with implicit occlusion handling and analytic derivatives. Error-prone correspondence finding, or discrete sampling of surface displacement values are also not needed. We show several reconstructions of human subjects wearing loose clothing, and we qualitatively and quantitatively show that we robustly capture more detail than related methods.