 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoarse-to-Real: Generative Rendering for Populated Dynamic Scenes
Jan 29, 2026Traditional rendering pipelines rely on complex assets, accurate materials and lighting, and substantial computational resources to produce realistic imagery, yet they still face challenges in scalability and realism for populated dynamic scenes. We present C2R (Coarse-to-Real), a generative rendering framework that synthesizes real-style urban crowd videos from coarse 3D simulations. Our approach uses coarse 3D renderings to explicitly control scene layout, camera motion, and human trajectories, while a learned neural renderer generates realistic appearance, lighting, and fine-scale dynamics guided by text prompts. To overcome the lack of paired training data between coarse simulations and real videos, we adopt a two-phase mixed CG-real training strategy that learns a strong generative prior from large-scale real footage and introduces controllability through shared implicit spatio-temporal features across domains. The resulting system supports coarse-to-fine control, generalizes across diverse CG and game inputs, and produces temporally consistent, controllable, and realistic urban scene videos from minimal 3D input. We will release the model and project webpage at https://gonzalognogales.github.io/coarse2real/.
Learning Extremely High Density Crowds as Active Matters
Mar 15, 2025
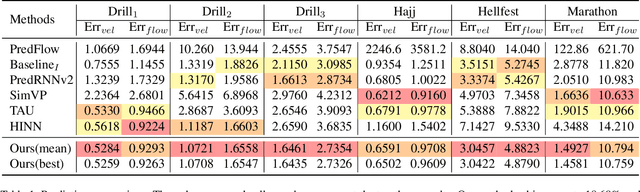
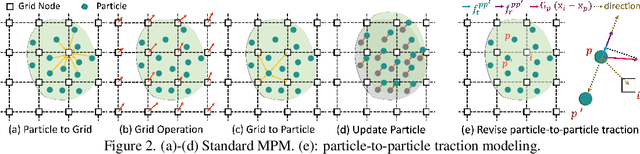

Video-based high-density crowd analysis and prediction has been a long-standing topic in computer vision. It is notoriously difficult due to, but not limited to, the lack of high-quality data and complex crowd dynamics. Consequently, it has been relatively under studied. In this paper, we propose a new approach that aims to learn from in-the-wild videos, often with low quality where it is difficult to track individuals or count heads. The key novelty is a new physics prior to model crowd dynamics. We model high-density crowds as active matter, a continumm with active particles subject to stochastic forces, named 'crowd material'. Our physics model is combined with neural networks, resulting in a neural stochastic differential equation system which can mimic the complex crowd dynamics. Due to the lack of similar research, we adapt a range of existing methods which are close to ours for comparison. Through exhaustive evaluation, we show our model outperforms existing methods in analyzing and forecasting extremely high-density crowds. Furthermore, since our model is a continuous-time physics model, it can be used for simulation and analysis, providing strong interpretability. This is categorically different from most deep learning methods, which are discrete-time models and black-boxes.
TexTile: A Differentiable Metric for Texture Tileability
Mar 19, 2024
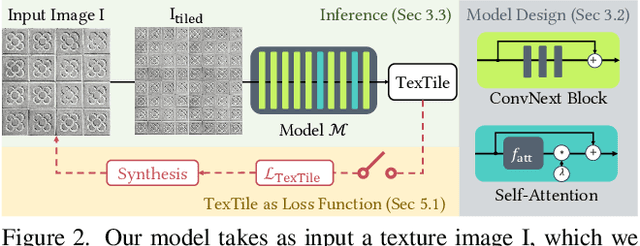
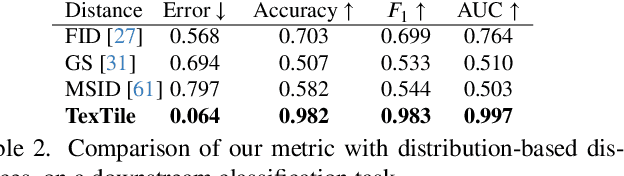

We introduce TexTile, a novel differentiable metric to quantify the degree upon which a texture image can be concatenated with itself without introducing repeating artifacts (i.e., the tileability). Existing methods for tileable texture synthesis focus on general texture quality, but lack explicit analysis of the intrinsic repeatability properties of a texture. In contrast, our TexTile metric effectively evaluates the tileable properties of a texture, opening the door to more informed synthesis and analysis of tileable textures. Under the hood, TexTile is formulated as a binary classifier carefully built from a large dataset of textures of different styles, semantics, regularities, and human annotations.Key to our method is a set of architectural modifications to baseline pre-train image classifiers to overcome their shortcomings at measuring tileability, along with a custom data augmentation and training regime aimed at increasing robustness and accuracy. We demonstrate that TexTile can be plugged into different state-of-the-art texture synthesis methods, including diffusion-based strategies, and generate tileable textures while keeping or even improving the overall texture quality. Furthermore, we show that TexTile can objectively evaluate any tileable texture synthesis method, whereas the current mix of existing metrics produces uncorrelated scores which heavily hinders progress in the field.
SMPLitex: A Generative Model and Dataset for 3D Human Texture Estimation from Single Image
Sep 07, 2023

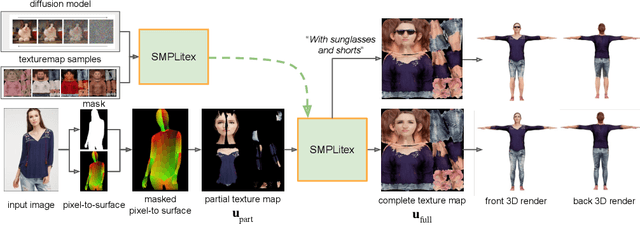

We propose SMPLitex, a method for estimating and manipulating the complete 3D appearance of humans captured from a single image. SMPLitex builds upon the recently proposed generative models for 2D images, and extends their use to the 3D domain through pixel-to-surface correspondences computed on the input image. To this end, we first train a generative model for complete 3D human appearance, and then fit it into the input image by conditioning the generative model to the visible parts of the subject. Furthermore, we propose a new dataset of high-quality human textures built by sampling SMPLitex conditioned on subject descriptions and images. We quantitatively and qualitatively evaluate our method in 3 publicly available datasets, demonstrating that SMPLitex significantly outperforms existing methods for human texture estimation while allowing for a wider variety of tasks such as editing, synthesis, and manipulation
How Will It Drape Like? Capturing Fabric Mechanics from Depth Images
Apr 13, 2023We propose a method to estimate the mechanical parameters of fabrics using a casual capture setup with a depth camera. Our approach enables to create mechanically-correct digital representations of real-world textile materials, which is a fundamental step for many interactive design and engineering applications. As opposed to existing capture methods, which typically require expensive setups, video sequences, or manual intervention, our solution can capture at scale, is agnostic to the optical appearance of the textile, and facilitates fabric arrangement by non-expert operators. To this end, we propose a sim-to-real strategy to train a learning-based framework that can take as input one or multiple images and outputs a full set of mechanical parameters. Thanks to carefully designed data augmentation and transfer learning protocols, our solution generalizes to real images despite being trained only on synthetic data, hence successfully closing the sim-to-real loop.Key in our work is to demonstrate that evaluating the regression accuracy based on the similarity at parameter space leads to an inaccurate distances that do not match the human perception. To overcome this, we propose a novel metric for fabric drape similarity that operates on the image domain instead on the parameter space, allowing us to evaluate our estimation within the context of a similarity rank. We show that out metric correlates with human judgments about the perception of drape similarity, and that our model predictions produce perceptually accurate results compared to the ground truth parameters.
PERGAMO: Personalized 3D Garments from Monocular Video
Oct 26, 2022Clothing plays a fundamental role in digital humans. Current approaches to animate 3D garments are mostly based on realistic physics simulation, however, they typically suffer from two main issues: high computational run-time cost, which hinders their development; and simulation-to-real gap, which impedes the synthesis of specific real-world cloth samples. To circumvent both issues we propose PERGAMO, a data-driven approach to learn a deformable model for 3D garments from monocular images. To this end, we first introduce a novel method to reconstruct the 3D geometry of garments from a single image, and use it to build a dataset of clothing from monocular videos. We use these 3D reconstructions to train a regression model that accurately predicts how the garment deforms as a function of the underlying body pose. We show that our method is capable of producing garment animations that match the real-world behaviour, and generalizes to unseen body motions extracted from motion capture dataset.
HandFlow: Quantifying View-Dependent 3D Ambiguity in Two-Hand Reconstruction with Normalizing Flow
Oct 04, 2022
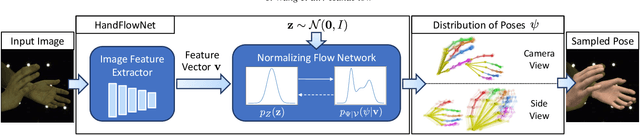
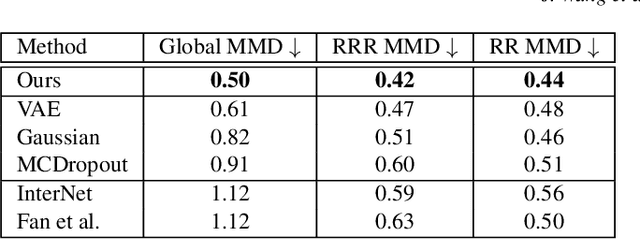
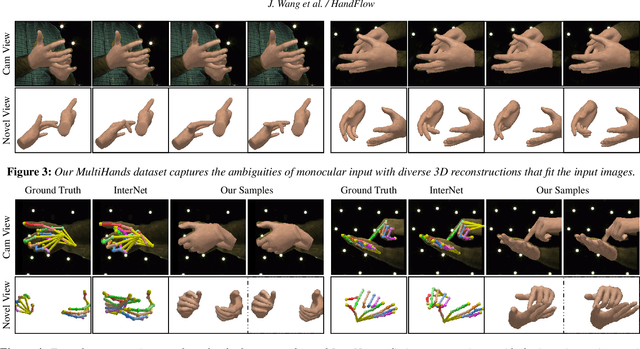
Reconstructing two-hand interactions from a single image is a challenging problem due to ambiguities that stem from projective geometry and heavy occlusions. Existing methods are designed to estimate only a single pose, despite the fact that there exist other valid reconstructions that fit the image evidence equally well. In this paper we propose to address this issue by explicitly modeling the distribution of plausible reconstructions in a conditional normalizing flow framework. This allows us to directly supervise the posterior distribution through a novel determinant magnitude regularization, which is key to varied 3D hand pose samples that project well into the input image. We also demonstrate that metrics commonly used to assess reconstruction quality are insufficient to evaluate pose predictions under such severe ambiguity. To address this, we release the first dataset with multiple plausible annotations per image called MultiHands. The additional annotations enable us to evaluate the estimated distribution using the maximum mean discrepancy metric. Through this, we demonstrate the quality of our probabilistic reconstruction and show that explicit ambiguity modeling is better-suited for this challenging problem.
SNUG: Self-Supervised Neural Dynamic Garments
Apr 05, 2022



We present a self-supervised method to learn dynamic 3D deformations of garments worn by parametric human bodies. State-of-the-art data-driven approaches to model 3D garment deformations are trained using supervised strategies that require large datasets, usually obtained by expensive physics-based simulation methods or professional multi-camera capture setups. In contrast, we propose a new training scheme that removes the need for ground-truth samples, enabling self-supervised training of dynamic 3D garment deformations. Our key contribution is to realize that physics-based deformation models, traditionally solved in a frame-by-frame basis by implicit integrators, can be recasted as an optimization problem. We leverage such optimization-based scheme to formulate a set of physics-based loss terms that can be used to train neural networks without precomputing ground-truth data. This allows us to learn models for interactive garments, including dynamic deformations and fine wrinkles, with two orders of magnitude speed up in training time compared to state-of-the-art supervised methods
A Survey on Intrinsic Images: Delving Deep Into Lambert and Beyond
Dec 07, 2021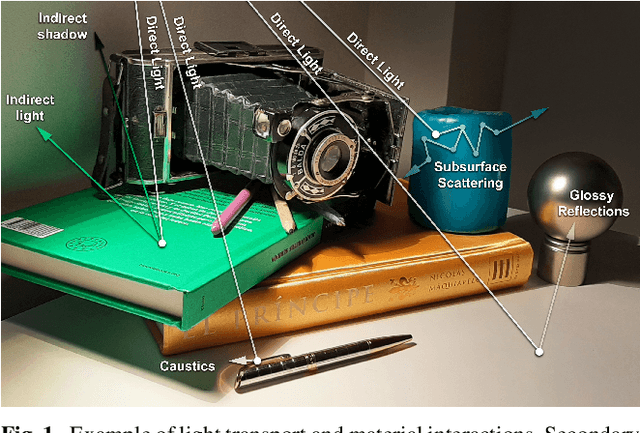
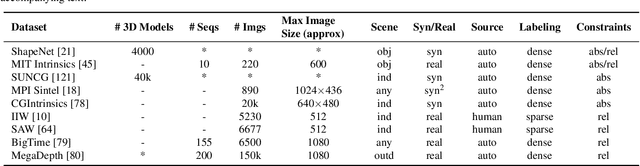
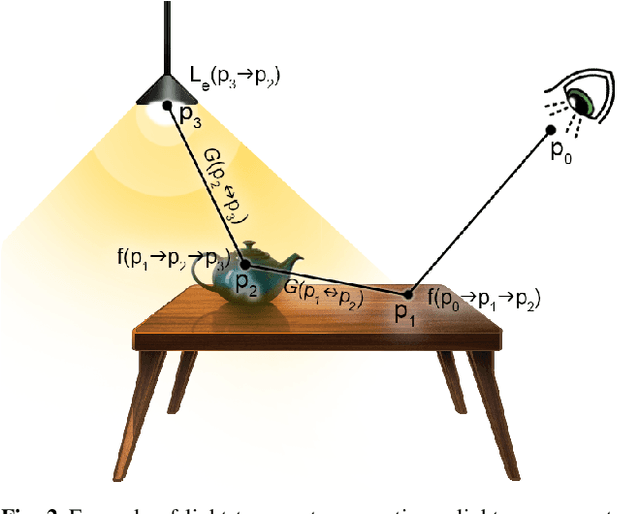
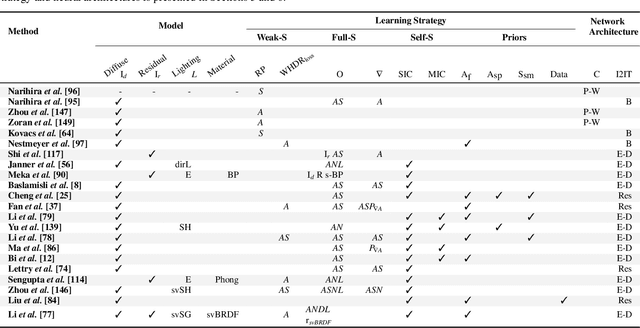
Intrinsic imaging or intrinsic image decomposition has traditionally been described as the problem of decomposing an image into two layers: a reflectance, the albedo invariant color of the material; and a shading, produced by the interaction between light and geometry. Deep learning techniques have been broadly applied in recent years to increase the accuracy of those separations. In this survey, we overview those results in context of well-known intrinsic image data sets and relevant metrics used in the literature, discussing their suitability to predict a desirable intrinsic image decomposition. Although the Lambertian assumption is still a foundational basis for many methods, we show that there is increasing awareness on the potential of more sophisticated physically-principled components of the image formation process, that is, optically accurate material models and geometry, and more complete inverse light transport estimations. We classify these methods in terms of the type of decomposition, considering the priors and models used, as well as the learning architecture and methodology driving the decomposition process. We also provide insights about future directions for research, given the recent advances in neural, inverse and differentiable rendering techniques.
RGB2Hands: Real-Time Tracking of 3D Hand Interactions from Monocular RGB Video
Jun 22, 2021

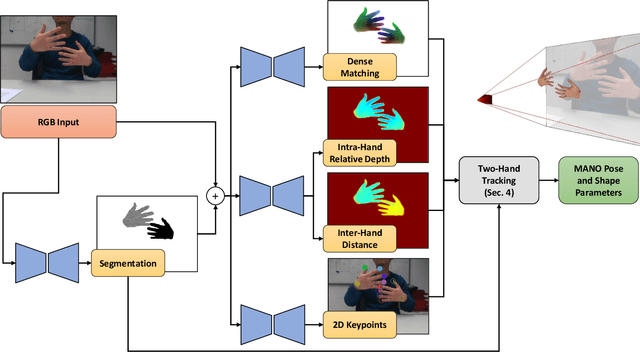
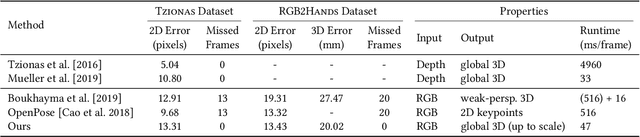
Tracking and reconstructing the 3D pose and geometry of two hands in interaction is a challenging problem that has a high relevance for several human-computer interaction applications, including AR/VR, robotics, or sign language recognition. Existing works are either limited to simpler tracking settings (e.g., considering only a single hand or two spatially separated hands), or rely on less ubiquitous sensors, such as depth cameras. In contrast, in this work we present the first real-time method for motion capture of skeletal pose and 3D surface geometry of hands from a single RGB camera that explicitly considers close interactions. In order to address the inherent depth ambiguities in RGB data, we propose a novel multi-task CNN that regresses multiple complementary pieces of information, including segmentation, dense matchings to a 3D hand model, and 2D keypoint positions, together with newly proposed intra-hand relative depth and inter-hand distance maps. These predictions are subsequently used in a generative model fitting framework in order to estimate pose and shape parameters of a 3D hand model for both hands. We experimentally verify the individual components of our RGB two-hand tracking and 3D reconstruction pipeline through an extensive ablation study. Moreover, we demonstrate that our approach offers previously unseen two-hand tracking performance from RGB, and quantitatively and qualitatively outperforms existing RGB-based methods that were not explicitly designed for two-hand interactions. Moreover, our method even performs on-par with depth-based real-time methods.
* SIGGRAPH Asia 2020