 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Extremely High Density Crowds as Active Matters
Mar 15, 2025
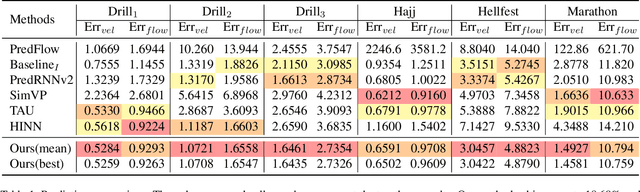

Video-based high-density crowd analysis and prediction has been a long-standing topic in computer vision. It is notoriously difficult due to, but not limited to, the lack of high-quality data and complex crowd dynamics. Consequently, it has been relatively under studied. In this paper, we propose a new approach that aims to learn from in-the-wild videos, often with low quality where it is difficult to track individuals or count heads. The key novelty is a new physics prior to model crowd dynamics. We model high-density crowds as active matter, a continumm with active particles subject to stochastic forces, named 'crowd material'. Our physics model is combined with neural networks, resulting in a neural stochastic differential equation system which can mimic the complex crowd dynamics. Due to the lack of similar research, we adapt a range of existing methods which are close to ours for comparison. Through exhaustive evaluation, we show our model outperforms existing methods in analyzing and forecasting extremely high-density crowds. Furthermore, since our model is a continuous-time physics model, it can be used for simulation and analysis, providing strong interpretability. This is categorically different from most deep learning methods, which are discrete-time models and black-boxes.
Human Motion Prediction under Unexpected Perturbation
Mar 23, 2024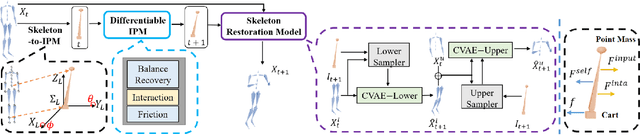
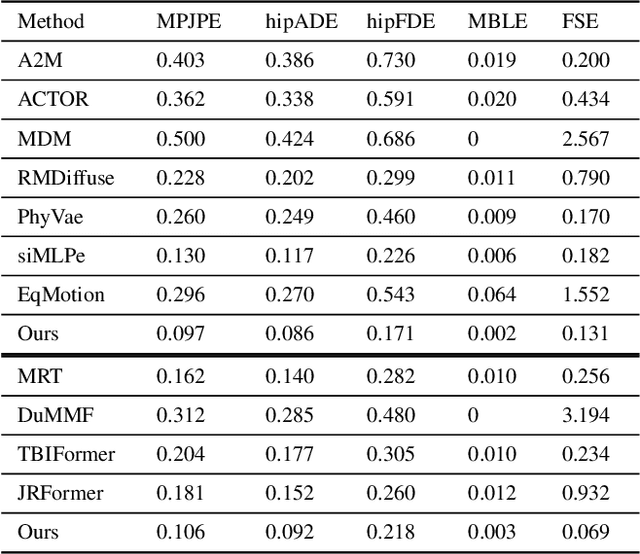
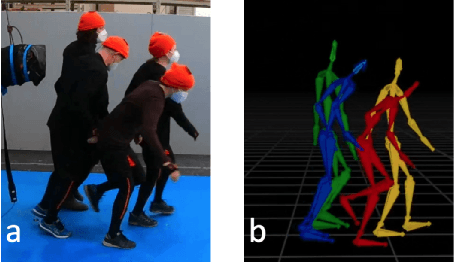
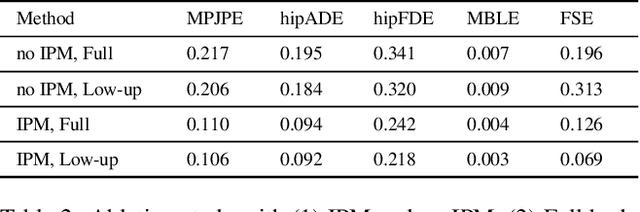
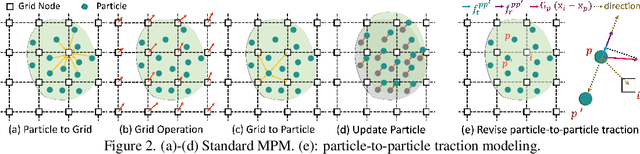
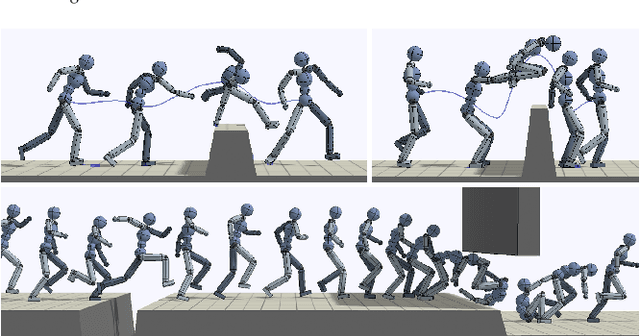
We investigate a new task in human motion prediction, which is predicting motions under unexpected physical perturbation potentially involving multiple people. Compared with existing research, this task involves predicting less controlled, unpremeditated and pure reactive motions in response to external impact and how such motions can propagate through people. It brings new challenges such as data scarcity and predicting complex interactions. To this end, we propose a new method capitalizing differential physics and deep neural networks, leading to an explicit Latent Differential Physics (LDP) model. Through experiments, we demonstrate that LDP has high data efficiency, outstanding prediction accuracy, strong generalizability and good explainability. Since there is no similar research, a comprehensive comparison with 11 adapted baselines from several relevant domains is conducted, showing LDP outperforming existing research both quantitatively and qualitatively, improving prediction accuracy by as much as 70%, and demonstrating significantly stronger generalization.
Reward Function Design for Crowd Simulation via Reinforcement Learning
Sep 22, 2023



Crowd simulation is important for video-games design, since it enables to populate virtual worlds with autonomous avatars that navigate in a human-like manner. Reinforcement learning has shown great potential in simulating virtual crowds, but the design of the reward function is critical to achieving effective and efficient results. In this work, we explore the design of reward functions for reinforcement learning-based crowd simulation. We provide theoretical insights on the validity of certain reward functions according to their analytical properties, and evaluate them empirically using a range of scenarios, using the energy efficiency as the metric. Our experiments show that directly minimizing the energy usage is a viable strategy as long as it is paired with an appropriately scaled guiding potential, and enable us to study the impact of the different reward components on the behavior of the simulated crowd. Our findings can inform the development of new crowd simulation techniques, and contribute to the wider study of human-like navigation.
UGAE: A Novel Approach to Non-exponential Discounting
Feb 11, 2023



The discounting mechanism in Reinforcement Learning determines the relative importance of future and present rewards. While exponential discounting is widely used in practice, non-exponential discounting methods that align with human behavior are often desirable for creating human-like agents. However, non-exponential discounting methods cannot be directly applied in modern on-policy actor-critic algorithms. To address this issue, we propose Universal Generalized Advantage Estimation (UGAE), which allows for the computation of GAE advantage values with arbitrary discounting. Additionally, we introduce Beta-weighted discounting, a continuous interpolation between exponential and hyperbolic discounting, to increase flexibility in choosing a discounting method. To showcase the utility of UGAE, we provide an analysis of the properties of various discounting methods. We also show experimentally that agents with non-exponential discounting trained via UGAE outperform variants trained with Monte Carlo advantage estimation. Through analysis of various discounting methods and experiments, we demonstrate the superior performance of UGAE with Beta-weighted discounting over the Monte Carlo baseline on standard RL benchmarks. UGAE is simple and easily integrated into any advantage-based algorithm as a replacement for the standard recursive GAE.
Understanding reinforcement learned crowds
Sep 19, 2022
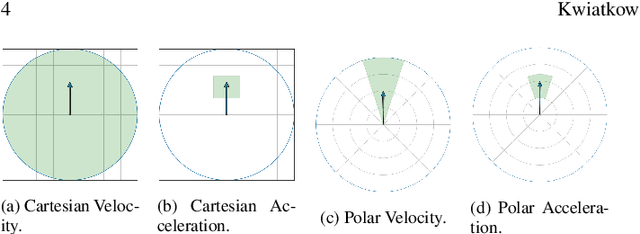
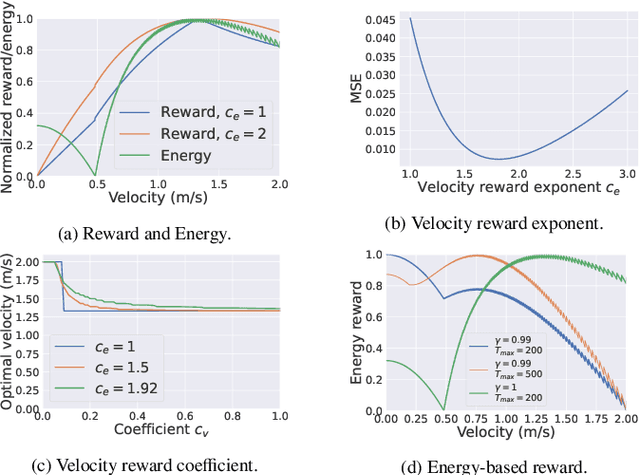
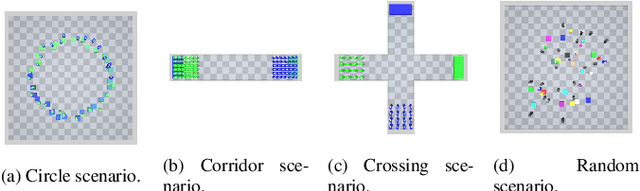
Simulating trajectories of virtual crowds is a commonly encountered task in Computer Graphics. Several recent works have applied Reinforcement Learning methods to animate virtual agents, however they often make different design choices when it comes to the fundamental simulation setup. Each of these choices comes with a reasonable justification for its use, so it is not obvious what is their real impact, and how they affect the results. In this work, we analyze some of these arbitrary choices in terms of their impact on the learning performance, as well as the quality of the resulting simulation measured in terms of the energy efficiency. We perform a theoretical analysis of the properties of the reward function design, and empirically evaluate the impact of using certain observation and action spaces on a variety of scenarios, with the reward function and energy usage as metrics. We show that directly using the neighboring agents' information as observation generally outperforms the more widely used raycasting. Similarly, using nonholonomic controls with egocentric observations tends to produce more efficient behaviors than holonomic controls with absolute observations. Each of these choices has a significant, and potentially nontrivial impact on the results, and so researchers should be mindful about choosing and reporting them in their work.
A Survey on Reinforcement Learning Methods in Character Animation
Mar 07, 2022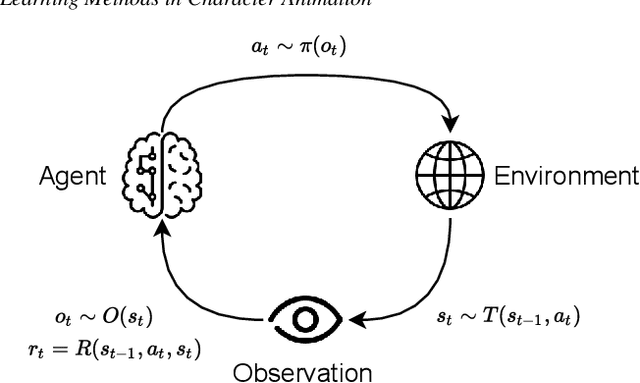
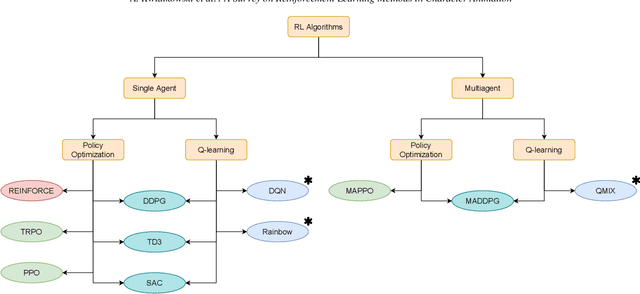
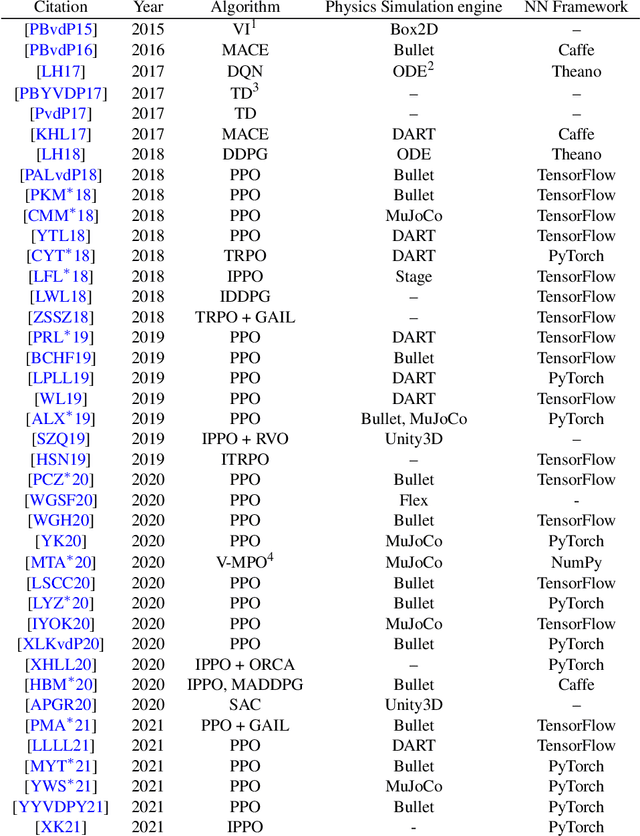
Reinforcement Learning is an area of Machine Learning focused on how agents can be trained to make sequential decisions, and achieve a particular goal within an arbitrary environment. While learning, they repeatedly take actions based on their observation of the environment, and receive appropriate rewards which define the objective. This experience is then used to progressively improve the policy controlling the agent's behavior, typically represented by a neural network. This trained module can then be reused for similar problems, which makes this approach promising for the animation of autonomous, yet reactive characters in simulators, video games or virtual reality environments. This paper surveys the modern Deep Reinforcement Learning methods and discusses their possible applications in Character Animation, from skeletal control of a single, physically-based character to navigation controllers for individual agents and virtual crowds. It also describes the practical side of training DRL systems, comparing the different frameworks available to build such agents.
A Perceptually-Validated Metric for Crowd Trajectory Quality Evaluation
Sep 04, 2021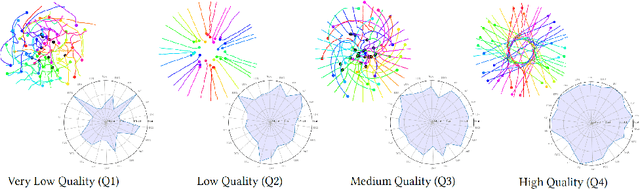

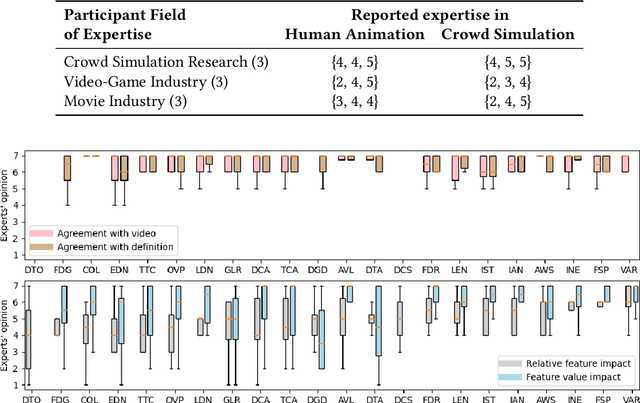
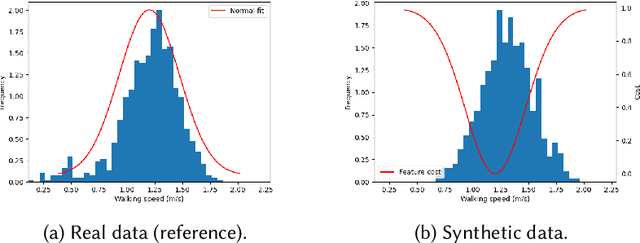
Simulating crowds requires controlling a very large number of trajectories and is usually performed using crowd motion algorithms for which appropriate parameter values need to be found. The study of the relation between parametric values for simulation techniques and the quality of the resulting trajectories has been studied either through perceptual experiments or by comparison with real crowd trajectories. In this paper, we integrate both strategies. A quality metric, QF, is proposed to abstract from reference data while capturing the most salient features that affect the perception of trajectory realism. QF weights and combines cost functions that are based on several individual, local and global properties of trajectories. These trajectory features are selected from the literature and from interviews with experts. To validate the capacity of QF to capture perceived trajectory quality, we conduct an online experiment that demonstrates the high agreement between the automatic quality score and non-expert users. To further demonstrate the usefulness of QF, we use it in a data-free parameter tuning application able to tune any parametric microscopic crowd simulation model that outputs independent trajectories for characters. The learnt parameters for the tuned crowd motion model maintain the influence of the reference data which was used to weight the terms of QF.
Crowd against the machine: A simulation-based benchmark tool to evaluate and compare robot capabilities to navigate a human crowd
Apr 29, 2021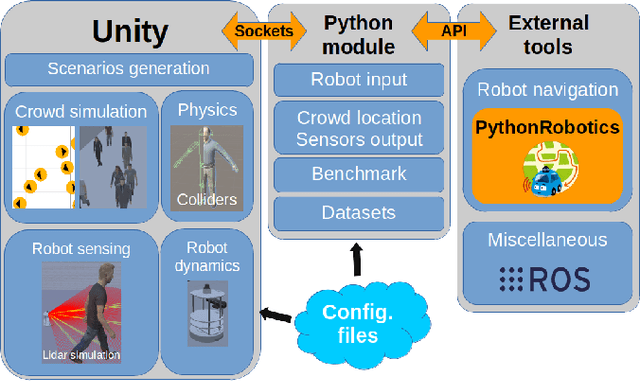
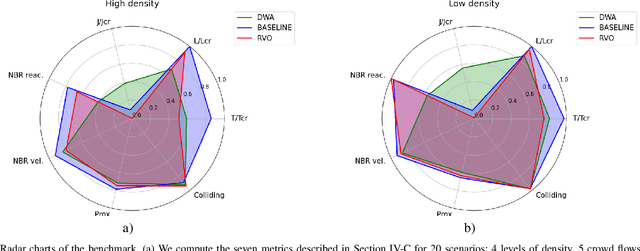
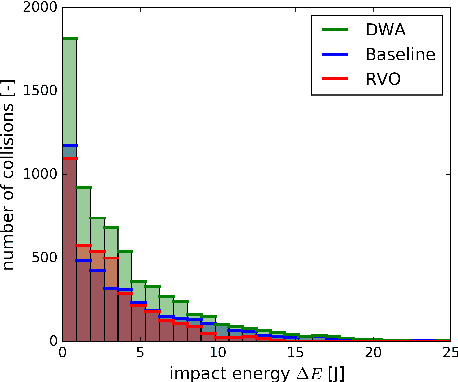
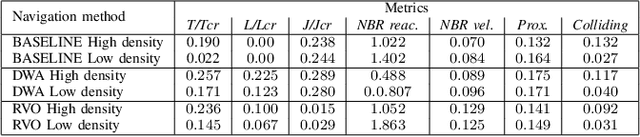
The evaluation of robot capabilities to navigate human crowds is essential to conceive new robots intended to operate in public spaces. This paper initiates the development of a benchmark tool to evaluate such capabilities; our long term vision is to provide the community with a simulation tool that generates virtual crowded environment to test robots, to establish standard scenarios and metrics to evaluate navigation techniques in terms of safety and efficiency, and thus, to install new methods to benchmarking robots' crowd navigation capabilities. This paper presents the architecture of the simulation tools, introduces first scenarios and evaluation metrics, as well as early results to demonstrate that our solution is relevant to be used as a benchmark tool.
Data-Driven Crowd Simulation with Generative Adversarial Networks
May 23, 2019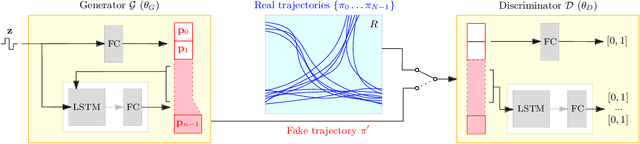
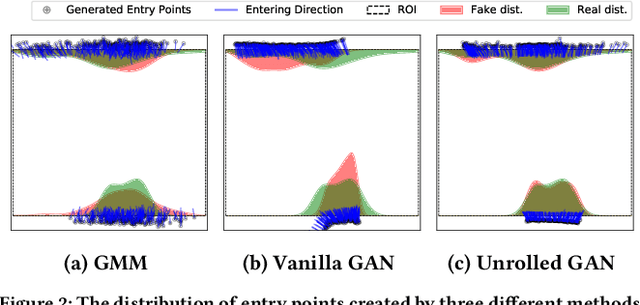

This paper presents a novel data-driven crowd simulation method that can mimic the observed traffic of pedestrians in a given environment. Given a set of observed trajectories, we use a recent form of neural networks, Generative Adversarial Networks (GANs), to learn the properties of this set and generate new trajectories with similar properties. We define a way for simulated pedestrians (agents) to follow such a trajectory while handling local collision avoidance. As such, the system can generate a crowd that behaves similarly to observations, while still enabling real-time interactions between agents. Via experiments with real-world data, we show that our simulated trajectories preserve the statistical properties of their input. Our method simulates crowds in real time that resemble existing crowds, while also allowing insertion of extra agents, combination with other simulation methods, and user interaction.
How do walkers avoid a mobile robot crossing their way?
Sep 26, 2016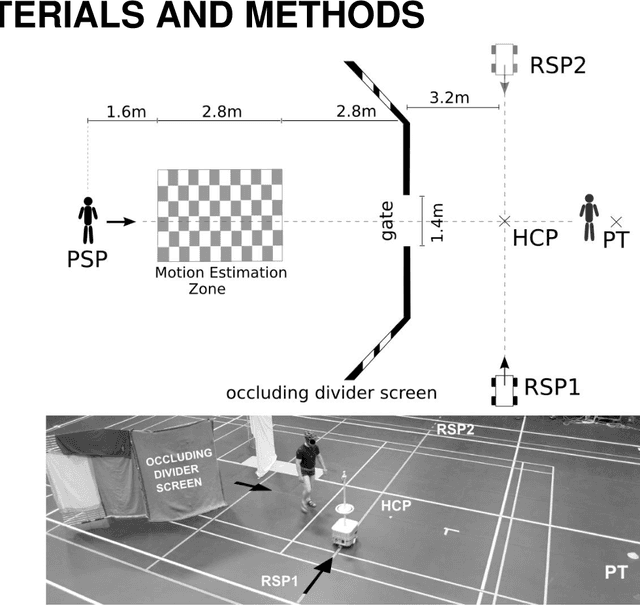
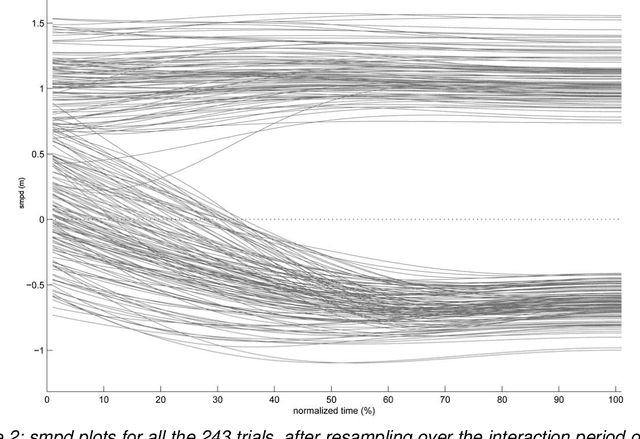
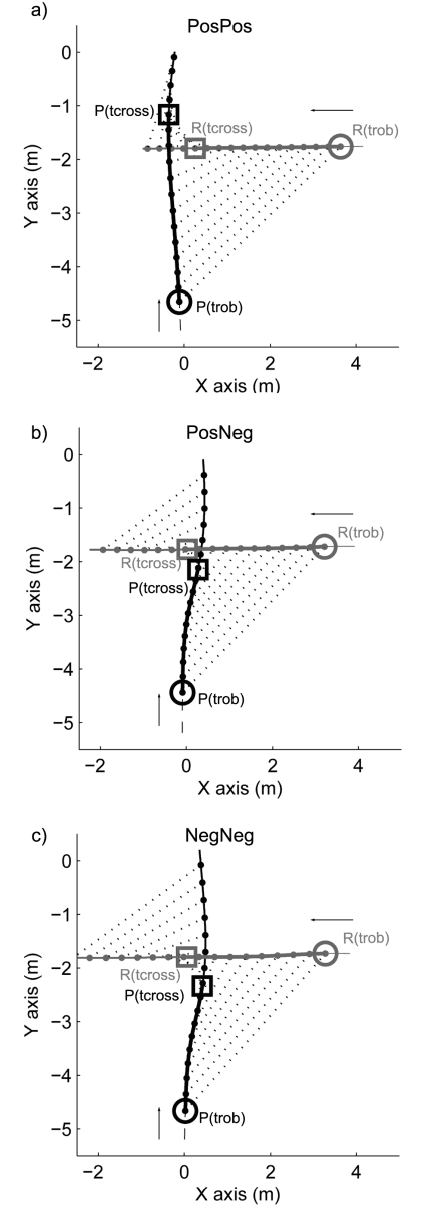
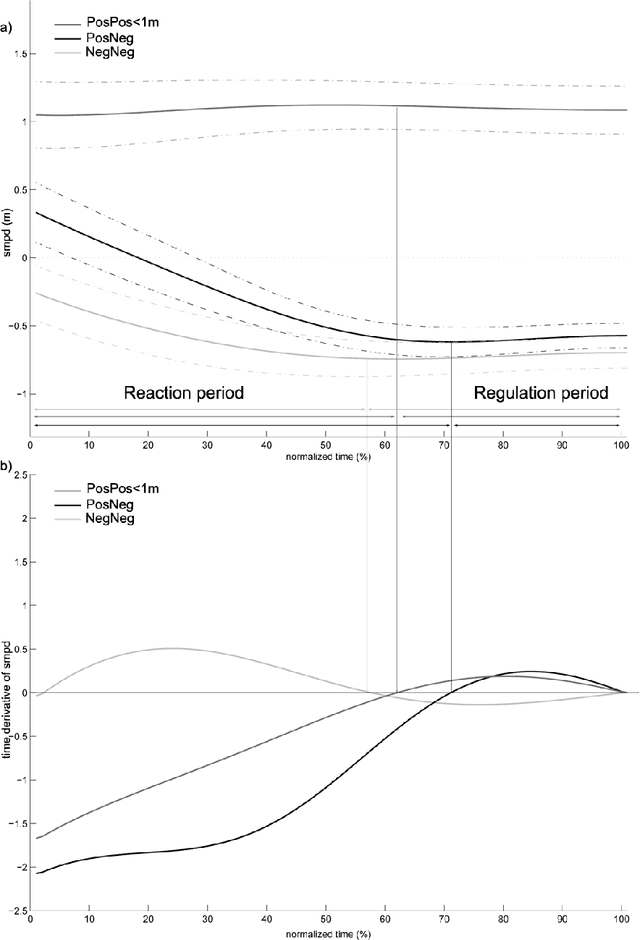
Robots and Humans have to share the same environment more and more often. In the aim of steering robots in a safe and convenient manner among humans it is required to understand how humans interact with them. This work focuses on collision avoidance between a human and a robot during locomotion. Having in mind previous results on human obstacle avoidance, as well as the description of the main principles which guide collision avoidance strategies, we observe how humans adapt a goal-directed locomotion task when they have to interfere with a mobile robot. Our results show differences in the strategy set by humans to avoid a robot in comparison with avoiding another human. Humans prefer to give the way to the robot even when they are likely to pass first at the beginning of the interaction.