 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Jun 11, 2025A major challenge for modern AI is to learn to understand the world and learn to act largely by observation. This paper explores a self-supervised approach that combines internet-scale video data with a small amount of interaction data (robot trajectories), to develop models capable of understanding, predicting, and planning in the physical world. We first pre-train an action-free joint-embedding-predictive architecture, V-JEPA 2, on a video and image dataset comprising over 1 million hours of internet video. V-JEPA 2 achieves strong performance on motion understanding (77.3 top-1 accuracy on Something-Something v2) and state-of-the-art performance on human action anticipation (39.7 recall-at-5 on Epic-Kitchens-100) surpassing previous task-specific models. Additionally, after aligning V-JEPA 2 with a large language model, we demonstrate state-of-the-art performance on multiple video question-answering tasks at the 8 billion parameter scale (e.g., 84.0 on PerceptionTest, 76.9 on TempCompass). Finally, we show how self-supervised learning can be applied to robotic planning tasks by post-training a latent action-conditioned world model, V-JEPA 2-AC, using less than 62 hours of unlabeled robot videos from the Droid dataset. We deploy V-JEPA 2-AC zero-shot on Franka arms in two different labs and enable picking and placing of objects using planning with image goals. Notably, this is achieved without collecting any data from the robots in these environments, and without any task-specific training or reward. This work demonstrates how self-supervised learning from web-scale data and a small amount of robot interaction data can yield a world model capable of planning in the physical world.
Locate 3D: Real-World Object Localization via Self-Supervised Learning in 3D
Apr 19, 2025We present LOCATE 3D, a model for localizing objects in 3D scenes from referring expressions like "the small coffee table between the sofa and the lamp." LOCATE 3D sets a new state-of-the-art on standard referential grounding benchmarks and showcases robust generalization capabilities. Notably, LOCATE 3D operates directly on sensor observation streams (posed RGB-D frames), enabling real-world deployment on robots and AR devices. Key to our approach is 3D-JEPA, a novel self-supervised learning (SSL) algorithm applicable to sensor point clouds. It takes as input a 3D pointcloud featurized using 2D foundation models (CLIP, DINO). Subsequently, masked prediction in latent space is employed as a pretext task to aid the self-supervised learning of contextualized pointcloud features. Once trained, the 3D-JEPA encoder is finetuned alongside a language-conditioned decoder to jointly predict 3D masks and bounding boxes. Additionally, we introduce LOCATE 3D DATASET, a new dataset for 3D referential grounding, spanning multiple capture setups with over 130K annotations. This enables a systematic study of generalization capabilities as well as a stronger model.
NavDreams: Towards Camera-Only RL Navigation Among Humans
Mar 23, 2022



Autonomously navigating a robot in everyday crowded spaces requires solving complex perception and planning challenges. When using only monocular image sensor data as input, classical two-dimensional planning approaches cannot be used. While images present a significant challenge when it comes to perception and planning, they also allow capturing potentially important details, such as complex geometry, body movement, and other visual cues. In order to successfully solve the navigation task from only images, algorithms must be able to model the scene and its dynamics using only this channel of information. We investigate whether the world model concept, which has shown state-of-the-art results for modeling and learning policies in Atari games as well as promising results in 2D LiDAR-based crowd navigation, can also be applied to the camera-based navigation problem. To this end, we create simulated environments where a robot must navigate past static and moving humans without colliding in order to reach its goal. We find that state-of-the-art methods are able to achieve success in solving the navigation problem, and can generate dream-like predictions of future image-sequences which show consistent geometry and moving persons. We are also able to show that policy performance in our high-fidelity sim2real simulation scenario transfers to the real world by testing the policy on a real robot. We make our simulator, models and experiments available at https://github.com/danieldugas/NavDreams.
Crowd against the machine: A simulation-based benchmark tool to evaluate and compare robot capabilities to navigate a human crowd
Apr 29, 2021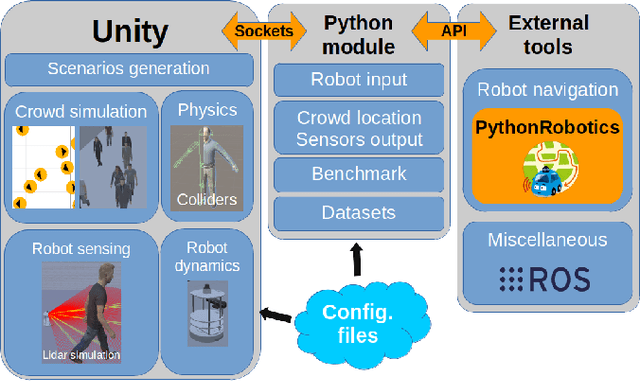
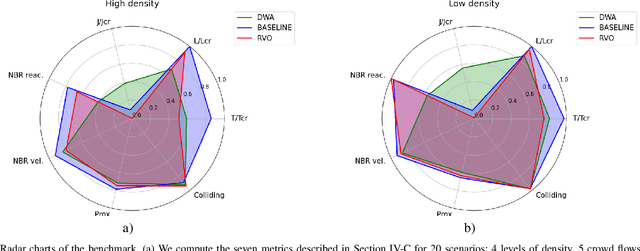
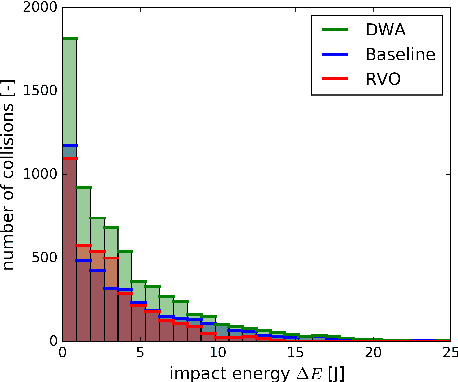
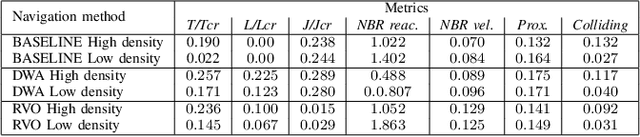
The evaluation of robot capabilities to navigate human crowds is essential to conceive new robots intended to operate in public spaces. This paper initiates the development of a benchmark tool to evaluate such capabilities; our long term vision is to provide the community with a simulation tool that generates virtual crowded environment to test robots, to establish standard scenarios and metrics to evaluate navigation techniques in terms of safety and efficiency, and thus, to install new methods to benchmarking robots' crowd navigation capabilities. This paper presents the architecture of the simulation tools, introduces first scenarios and evaluation metrics, as well as early results to demonstrate that our solution is relevant to be used as a benchmark tool.
NavRep: Unsupervised Representations for Reinforcement Learning of Robot Navigation in Dynamic Human Environments
Dec 08, 2020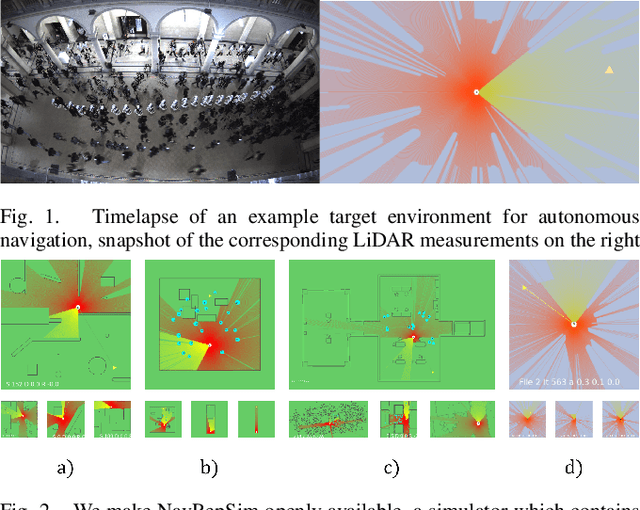
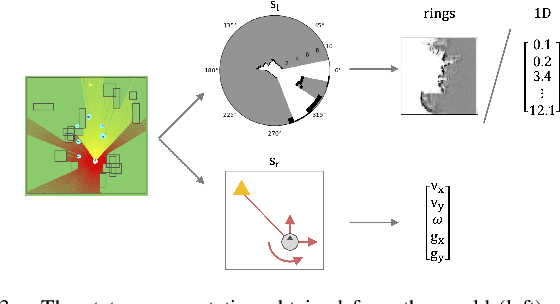
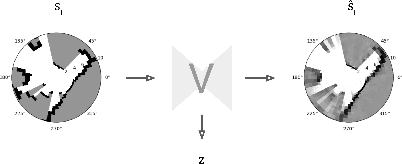
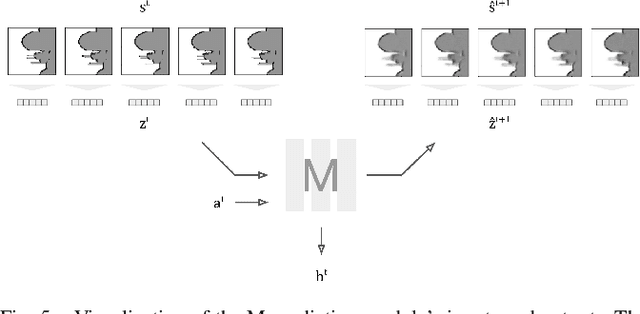
Robot navigation is a task where reinforcement learning approaches are still unable to compete with traditional path planning. State-of-the-art methods differ in small ways, and do not all provide reproducible, openly available implementations. This makes comparing methods a challenge. Recent research has shown that unsupervised learning methods can scale impressively, and be leveraged to solve difficult problems. In this work, we design ways in which unsupervised learning can be used to assist reinforcement learning for robot navigation. We train two end-to-end, and 18 unsupervised-learning-based architectures, and compare them, along with existing approaches, in unseen test cases. We demonstrate our approach working on a real life robot. Our results show that unsupervised learning methods are competitive with end-to-end methods. We also highlight the importance of various components such as input representation, predictive unsupervised learning, and latent features. We make all our models publicly available, as well as training and testing environments, and tools. This release also includes OpenAI-gym-compatible environments designed to emulate the training conditions described by other papers, with as much fidelity as possible. Our hope is that this helps in bringing together the field of RL for robot navigation, and allows meaningful comparisons across state-of-the-art methods.
SegMap: Segment-based mapping and localization using data-driven descriptors
Sep 27, 2019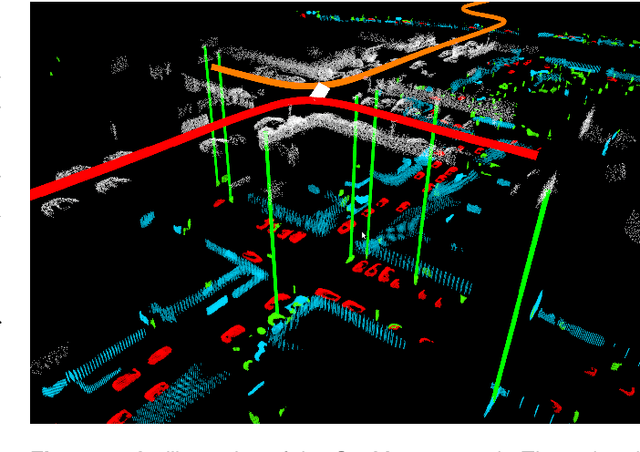
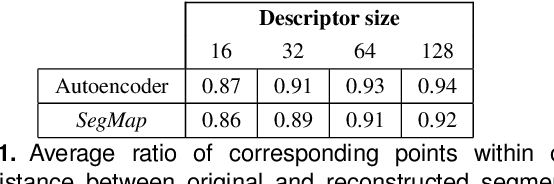

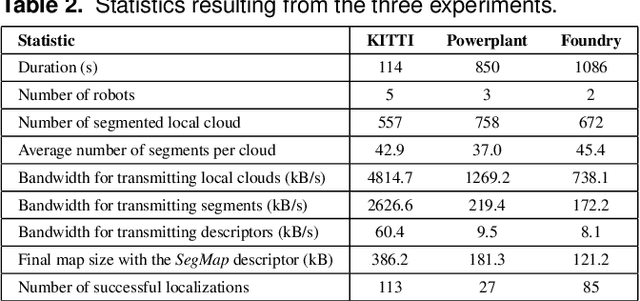
Precisely estimating a robot's pose in a prior, global map is a fundamental capability for mobile robotics, e.g. autonomous driving or exploration in disaster zones. This task, however, remains challenging in unstructured, dynamic environments, where local features are not discriminative enough and global scene descriptors only provide coarse information. We therefore present SegMap: a map representation solution for localization and mapping based on the extraction of segments in 3D point clouds. Working at the level of segments offers increased invariance to view-point and local structural changes, and facilitates real-time processing of large-scale 3D data. SegMap exploits a single compact data-driven descriptor for performing multiple tasks: global localization, 3D dense map reconstruction, and semantic information extraction. The performance of SegMap is evaluated in multiple urban driving and search and rescue experiments. We show that the learned SegMap descriptor has superior segment retrieval capabilities, compared to state-of-the-art handcrafted descriptors. In consequence, we achieve a higher localization accuracy and a 6% increase in recall over state-of-the-art. These segment-based localizations allow us to reduce the open-loop odometry drift by up to 50%. SegMap is open-source available along with easy to run demonstrations.
SegMatch: Segment based loop-closure for 3D point clouds
Jan 15, 2019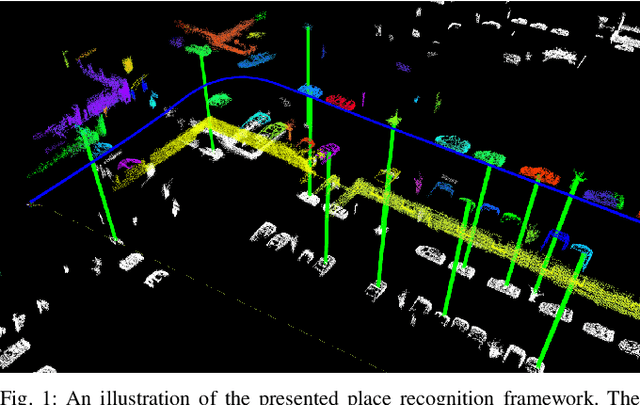
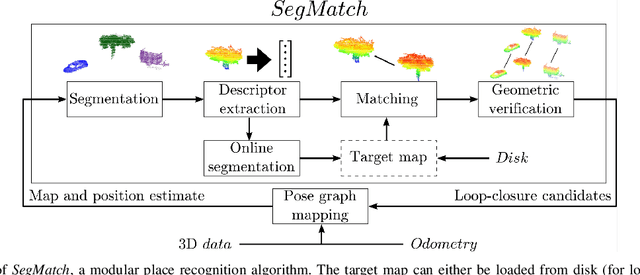
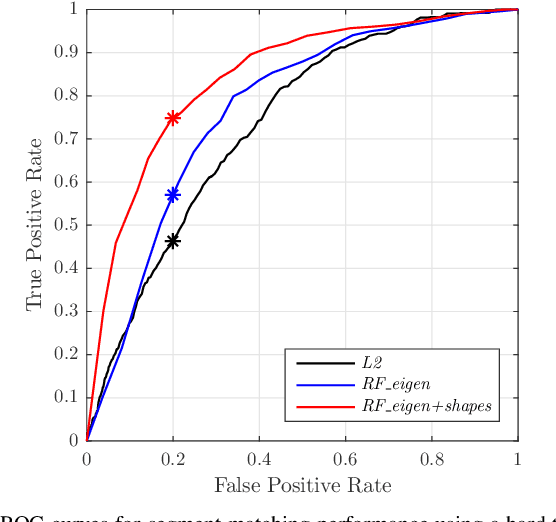
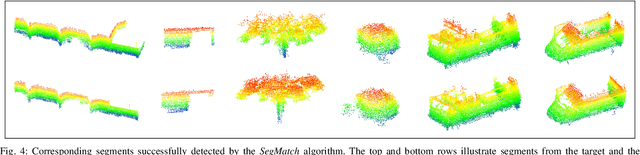
Loop-closure detection on 3D data is a challenging task that has been commonly approached by adapting image-based solutions. Methods based on local features suffer from ambiguity and from robustness to environment changes while methods based on global features are viewpoint dependent. We propose SegMatch, a reliable loop-closure detection algorithm based on the matching of 3D segments. Segments provide a good compromise between local and global descriptions, incorporating their strengths while reducing their individual drawbacks. SegMatch does not rely on assumptions of "perfect segmentation", or on the existence of "objects" in the environment, which allows for reliable execution on large scale, unstructured environments. We quantitatively demonstrate that SegMatch can achieve accurate localization at a frequency of 1Hz on the largest sequence of the KITTI odometry dataset. We furthermore show how this algorithm can reliably detect and close loops in real-time, during online operation. In addition, the source code for the SegMatch algorithm will be made available after publication.
SegMap: 3D Segment Mapping using Data-Driven Descriptors
Jan 15, 2019



When performing localization and mapping, working at the level of structure can be advantageous in terms of robustness to environmental changes and differences in illumination. This paper presents SegMap: a map representation solution to the localization and mapping problem based on the extraction of segments in 3D point clouds. In addition to facilitating the computationally intensive task of processing 3D point clouds, working at the level of segments addresses the data compression requirements of real-time single- and multi-robot systems. While current methods extract descriptors for the single task of localization, SegMap leverages a data-driven descriptor in order to extract meaningful features that can also be used for reconstructing a dense 3D map of the environment and for extracting semantic information. This is particularly interesting for navigation tasks and for providing visual feedback to end-users such as robot operators, for example in search and rescue scenarios. These capabilities are demonstrated in multiple urban driving and search and rescue experiments. Our method leads to an increase of area under the ROC curve of 28.3% over current state of the art using eigenvalue based features. We also obtain very similar reconstruction capabilities to a model specifically trained for this task. The SegMap implementation will be made available open-source along with easy to run demonstrations at www.github.com/ethz-asl/segmap. A video demonstration is available at https://youtu.be/CMk4w4eRobg.