 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Image-Anomaly Mitigation for Autonomous Mobile Robots
Sep 04, 2021
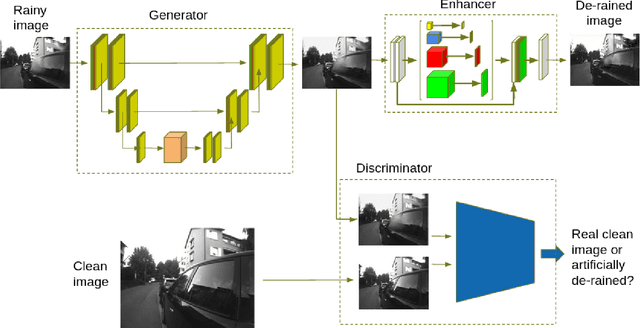
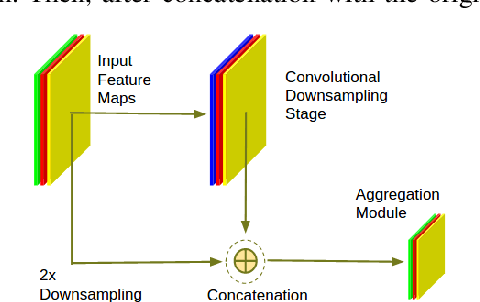

Camera anomalies like rain or dust can severelydegrade image quality and its related tasks, such as localizationand segmentation. In this work we address this importantissue by implementing a pre-processing step that can effectivelymitigate such artifacts in a real-time fashion, thus supportingthe deployment of autonomous systems with limited computecapabilities. We propose a shallow generator with aggregation,trained in an adversarial setting to solve the ill-posed problemof reconstructing the occluded regions. We add an enhancer tofurther preserve high-frequency details and image colorization.We also produce one of the largest publicly available datasets1to train our architecture and use realistic synthetic raindrops toobtain an improved initialization of the model. We benchmarkour framework on existing datasets and on our own imagesobtaining state-of-the-art results while enabling real-time per-formance, with up to 40x faster inference time than existingapproaches.
Leveraging Stereo-Camera Data for Real-Time Dynamic Obstacle Detection and Tracking
Jul 21, 2020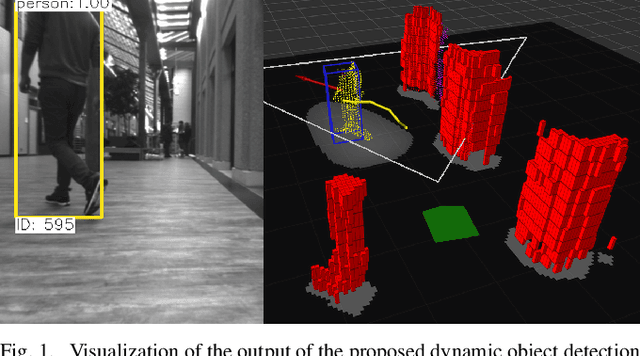
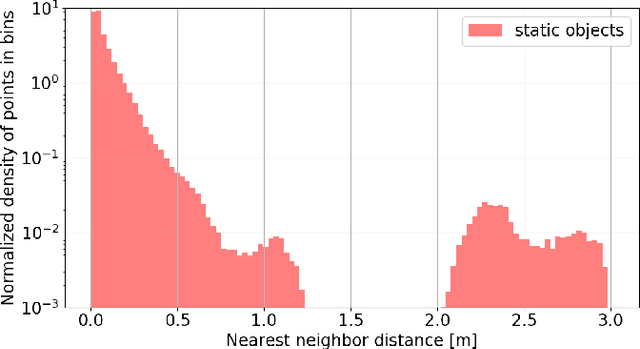


Dynamic obstacle avoidance is one crucial component for compliant navigation in crowded environments. In this paper we present a system for accurate and reliable detection and tracking of dynamic objects using noisy point cloud data generated by stereo cameras. Our solution is real-time capable and specifically designed for the deployment on computationally-constrained unmanned ground vehicles. The proposed approach identifies individual objects in the robot's surroundings and classifies them as either static or dynamic. The dynamic objects are labeled as either a person or a generic dynamic object. We then estimate their velocities to generate a 2D occupancy grid that is suitable for performing obstacle avoidance. We evaluate the system in indoor and outdoor scenarios and achieve real-time performance on a consumer-grade computer. On our test-dataset, we reach a MOTP of $0.07 \pm 0.07m$, and a MOTA of $85.3\%$ for the detection and tracking of dynamic objects. We reach a precision of $96.9\%$ for the detection of static objects.
OneShot Global Localization: Instant LiDAR-Visual Pose Estimation
Mar 31, 2020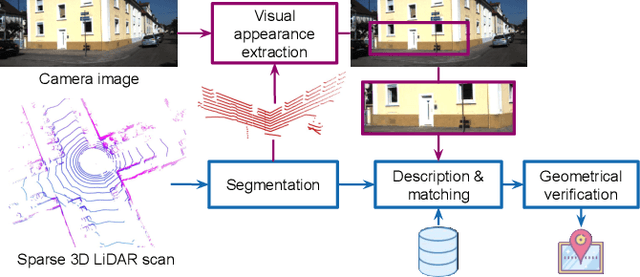


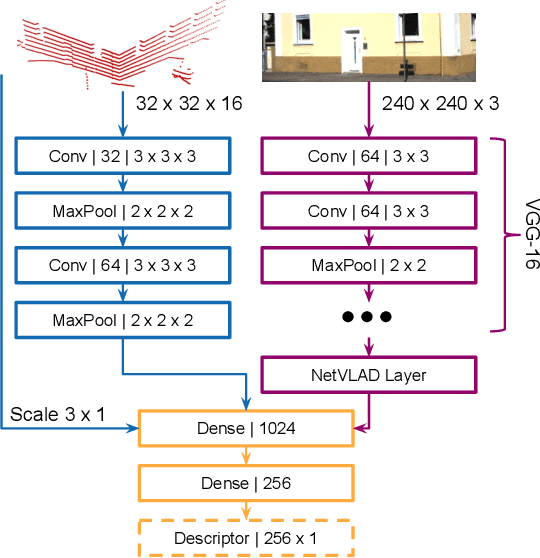
Globally localizing in a given map is a crucial ability for robots to perform a wide range of autonomous navigation tasks. This paper presents OneShot - a global localization algorithm that uses only a single 3D LiDAR scan at a time, while outperforming approaches based on integrating a sequence of point clouds. Our approach, which does not require the robot to move, relies on learning-based descriptors of point cloud segments and computes the full 6 degree-of-freedom pose in a map. The segments are extracted from the current LiDAR scan and are matched against a database using the computed descriptors. Candidate matches are then verified with a geometric consistency test. We additionally present a strategy to further improve the performance of the segment descriptors by augmenting them with visual information provided by a camera. For this purpose, a custom-tailored neural network architecture is proposed. We demonstrate that our LiDAR-only approach outperforms a state-of-the-art baseline on a sequence of the KITTI dataset and also evaluate its performance on the challenging NCLT dataset. Finally, we show that fusing in visual information boosts segment retrieval rates by up to 26% compared to LiDAR-only description.
SegMap: Segment-based mapping and localization using data-driven descriptors
Sep 27, 2019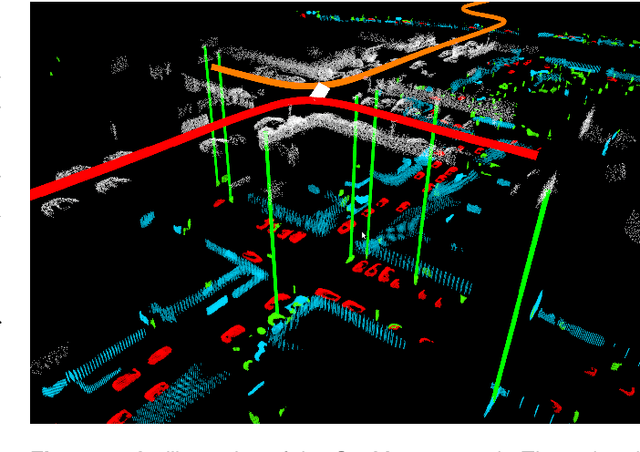
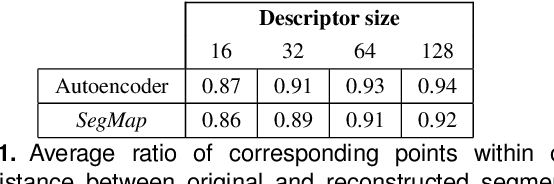

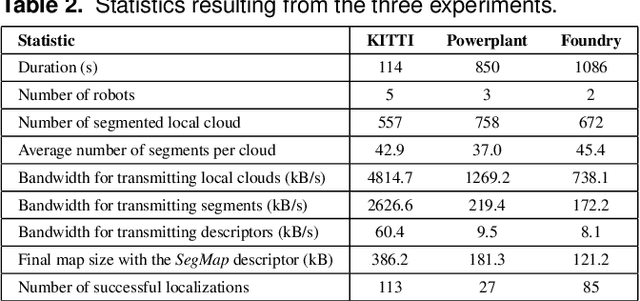
Precisely estimating a robot's pose in a prior, global map is a fundamental capability for mobile robotics, e.g. autonomous driving or exploration in disaster zones. This task, however, remains challenging in unstructured, dynamic environments, where local features are not discriminative enough and global scene descriptors only provide coarse information. We therefore present SegMap: a map representation solution for localization and mapping based on the extraction of segments in 3D point clouds. Working at the level of segments offers increased invariance to view-point and local structural changes, and facilitates real-time processing of large-scale 3D data. SegMap exploits a single compact data-driven descriptor for performing multiple tasks: global localization, 3D dense map reconstruction, and semantic information extraction. The performance of SegMap is evaluated in multiple urban driving and search and rescue experiments. We show that the learned SegMap descriptor has superior segment retrieval capabilities, compared to state-of-the-art handcrafted descriptors. In consequence, we achieve a higher localization accuracy and a 6% increase in recall over state-of-the-art. These segment-based localizations allow us to reduce the open-loop odometry drift by up to 50%. SegMap is open-source available along with easy to run demonstrations.
VIZARD: Reliable Visual Localization for Autonomous Vehicles in Urban Outdoor Environments
Feb 12, 2019
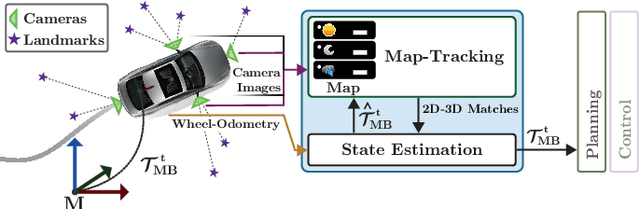
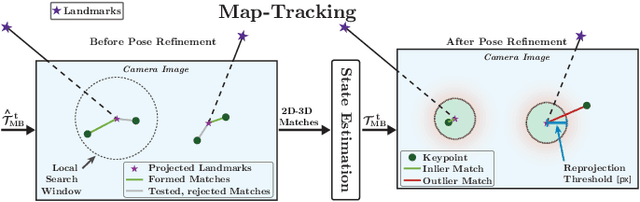
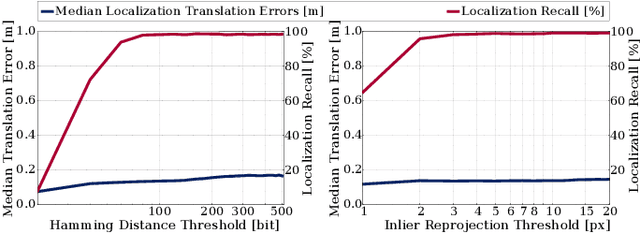
Changes in appearance is one of the main sources of failure in visual localization systems in outdoor environments. To address this challenge, we present VIZARD, a visual localization system for urban outdoor environments. By combining a local localization algorithm with the use of multi-session maps, a high localization recall can be achieved across vastly different appearance conditions. The fusion of the visual localization constraints with wheel-odometry in a state estimation framework further guarantees smooth and accurate pose estimates. In an extensive experimental evaluation on several hundreds of driving kilometers in challenging urban outdoor environments, we analyze the recall and accuracy of our localization system, investigate its key parameters and boundary conditions, and compare different types of feature descriptors. Our results show that VIZARD is able to achieve nearly 100% recall with a localization accuracy below 0.5m under varying outdoor appearance conditions, including at night-time.
From Coarse to Fine: Robust Hierarchical Localization at Large Scale
Dec 09, 2018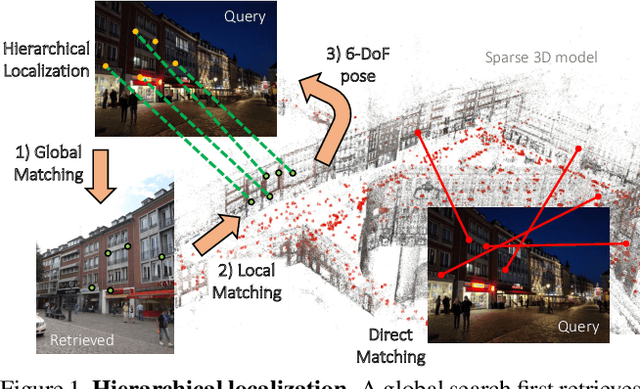

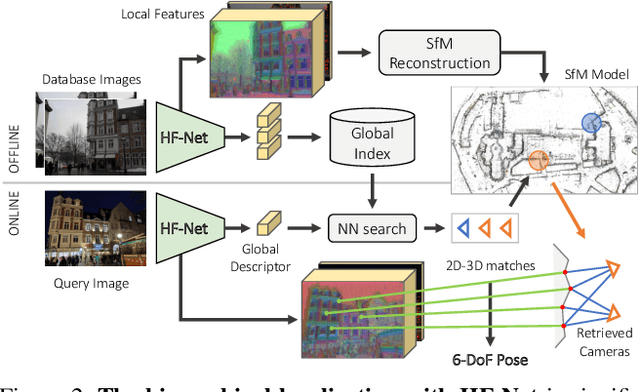
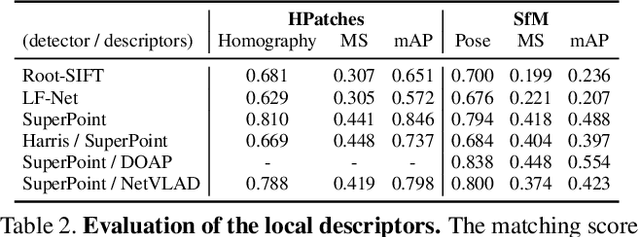
Robust and accurate visual localization is a fundamental capability for numerous applications, such as autonomous driving, mobile robotics, or augmented reality. It remains, however, a challenging task, particularly for large-scale environments and in presence of significant appearance changes. State-of-the-art methods not only struggle with such scenarios, but are often too resource intensive for certain real-time applications. In this paper we propose HF-Net, a hierarchical localization approach based on a monolithic CNN that simultaneously predicts local features and global descriptors for accurate 6-DoF localization. We exploit the coarse-to-fine localization paradigm: we first perform a global retrieval to obtain location hypotheses and only later match local features within those candidate places. This hierarchical approach incurs significant runtime savings and makes our system suitable for real-time operation. By leveraging learned descriptors, our method achieves remarkable localization robustness across large variations of appearance. Consequently, we demonstrate new state-of-the-art performance on two challenging benchmarks for large-scale 6-DoF localization. The code of our method will be made publicly available.
Leveraging Deep Visual Descriptors for Hierarchical Efficient Localization
Sep 18, 2018



Many robotics applications require precise pose estimates despite operating in large and changing environments. This can be addressed by visual localization, using a pre-computed 3D model of the surroundings. The pose estimation then amounts to finding correspondences between 2D keypoints in a query image and 3D points in the model using local descriptors. However, computational power is often limited on robotic platforms, making this task challenging in large-scale environments. Binary feature descriptors significantly speed up this 2D-3D matching, and have become popular in the robotics community, but also strongly impair the robustness to perceptual aliasing and changes in viewpoint, illumination and scene structure. In this work, we propose to leverage recent advances in deep learning to perform an efficient hierarchical localization. We first localize at the map level using learned image-wide global descriptors, and subsequently estimate a precise pose from 2D-3D matches computed in the candidate places only. This restricts the local search and thus allows to efficiently exploit powerful non-binary descriptors usually dismissed on resource-constrained devices. Our approach results in state-of-the-art localization performance while running in real-time on a popular mobile platform, enabling new prospects for robotics research.
Map Management for Efficient Long-Term Visual Localization in Outdoor Environments
Aug 08, 2018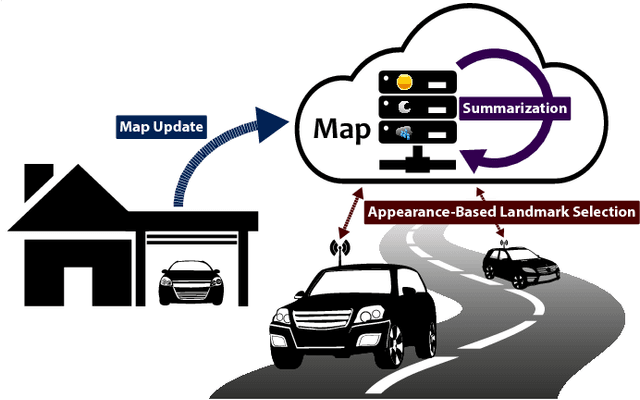
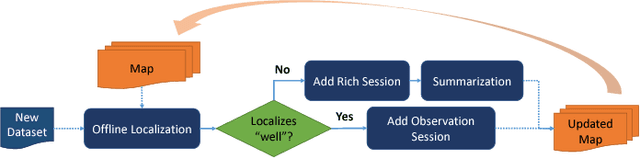
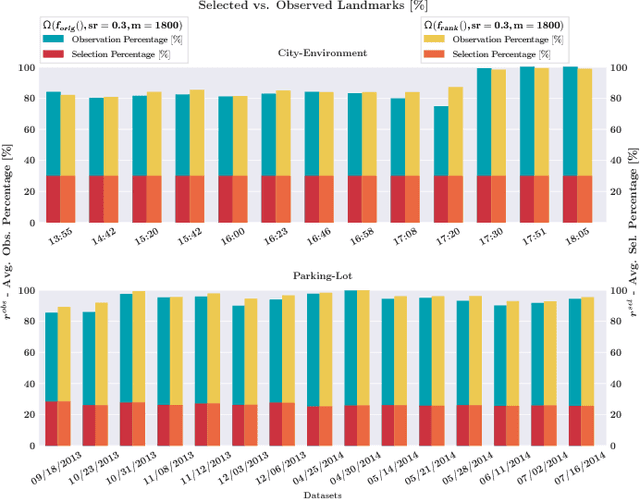
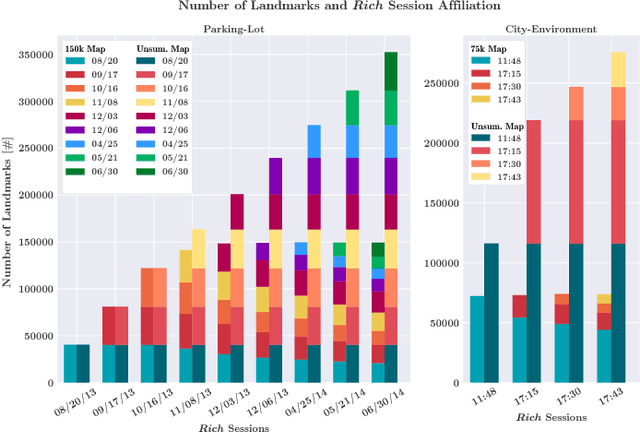
We present a complete map management process for a visual localization system designed for multi-vehicle long- term operations in resource constrained outdoor environments. Outdoor visual localization generates large amounts of data that need to be incorporated into a lifelong visual map in order to allow localization at all times and under all appearance conditions. Processing these large quantities of data is non- trivial, as it is subject to limited computational and storage capabilities both on the vehicle and on the mapping backend. We address this problem with a two-fold map update paradigm capable of, either, adding new visual cues to the map, or updating co-observation statistics. The former, in combination with offline map summarization techniques, allows enhancing the appearance coverage of the lifelong map while keeping the map size limited. On the other hand, the latter is able to significantly boost the appearance-based landmark selection for efficient online localization without incurring any additional computational or storage burden. Our evaluation in challenging outdoor conditions shows that our proposed map management process allows building and maintaining maps for precise visual localization over long time spans in a tractable and scalable fashion.
LandmarkBoost: Efficient Visual Context Classifiers for Robust Localization
Jul 13, 2018



The growing popularity of autonomous systems creates a need for reliable and efficient metric pose retrieval algorithms. Currently used approaches tend to rely on nearest neighbor search of binary descriptors to perform the 2D-3D matching and guarantee realtime capabilities on mobile platforms. These methods struggle, however, with the growing size of the map, changes in viewpoint or appearance, and visual aliasing present in the environment. The rigidly defined descriptor patterns only capture a limited neighborhood of the keypoint and completely ignore the overall visual context. We propose LandmarkBoost - an approach that, in contrast to the conventional 2D-3D matching methods, casts the search problem as a landmark classification task. We use a boosted classifier to classify landmark observations and directly obtain correspondences as classifier scores. We also introduce a formulation of visual context that is flexible, efficient to compute, and can capture relationships in the entire image plane. The original binary descriptors are augmented with contextual information and informative features are selected by the boosting framework. Through detailed experiments, we evaluate the retrieval quality and performance of LandmarkBoost, demonstrating that it outperforms common state-of-the-art descriptor matching methods.
Dynamic Objects Segmentation for Visual Localization in Urban Environments
Jul 09, 2018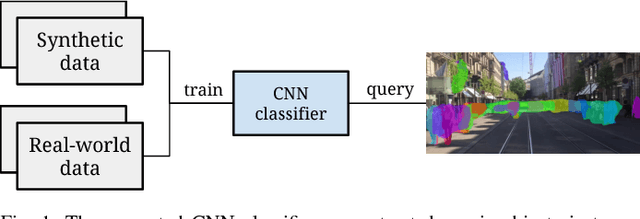
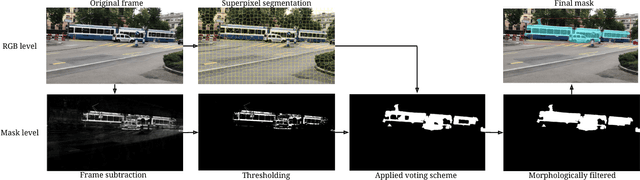
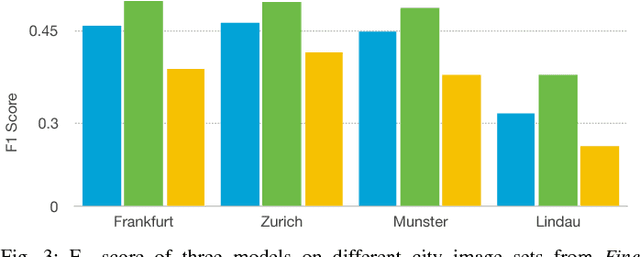

Visual localization and mapping is a crucial capability to address many challenges in mobile robotics. It constitutes a robust, accurate and cost-effective approach for local and global pose estimation within prior maps. Yet, in highly dynamic environments, like crowded city streets, problems arise as major parts of the image can be covered by dynamic objects. Consequently, visual odometry pipelines often diverge and the localization systems malfunction as detected features are not consistent with the precomputed 3D model. In this work, we present an approach to automatically detect dynamic object instances to improve the robustness of vision-based localization and mapping in crowded environments. By training a convolutional neural network model with a combination of synthetic and real-world data, dynamic object instance masks are learned in a semi-supervised way. The real-world data can be collected with a standard camera and requires minimal further post-processing. Our experiments show that a wide range of dynamic objects can be reliably detected using the presented method. Promising performance is demonstrated on our own and also publicly available datasets, which also shows the generalization capabilities of this approach.