 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Image-Anomaly Mitigation for Autonomous Mobile Robots
Sep 04, 2021
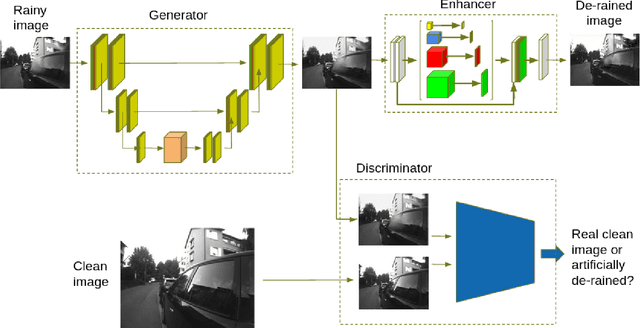
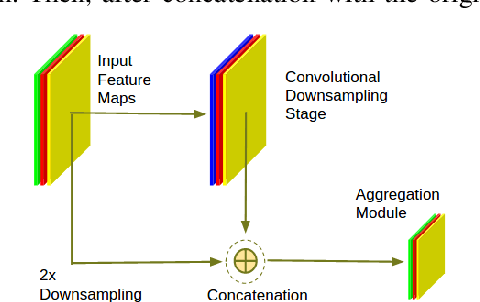

Camera anomalies like rain or dust can severelydegrade image quality and its related tasks, such as localizationand segmentation. In this work we address this importantissue by implementing a pre-processing step that can effectivelymitigate such artifacts in a real-time fashion, thus supportingthe deployment of autonomous systems with limited computecapabilities. We propose a shallow generator with aggregation,trained in an adversarial setting to solve the ill-posed problemof reconstructing the occluded regions. We add an enhancer tofurther preserve high-frequency details and image colorization.We also produce one of the largest publicly available datasets1to train our architecture and use realistic synthetic raindrops toobtain an improved initialization of the model. We benchmarkour framework on existing datasets and on our own imagesobtaining state-of-the-art results while enabling real-time per-formance, with up to 40x faster inference time than existingapproaches.
Depth-Aware Action Recognition: Pose-Motion Encoding through Temporal Heatmaps
Nov 26, 2020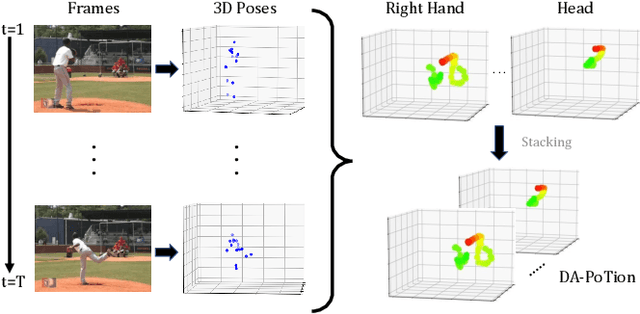

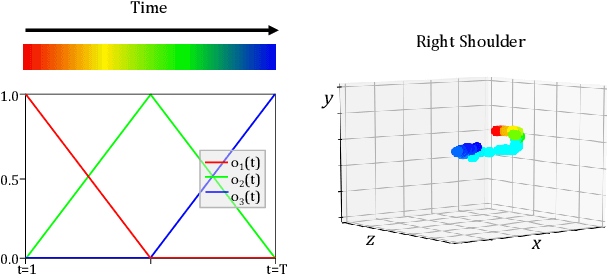
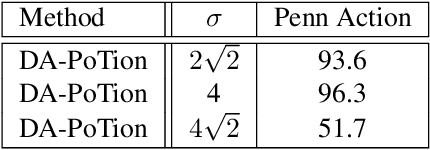
Most state-of-the-art methods for action recognition rely only on 2D spatial features encoding appearance, motion or pose. However, 2D data lacks the depth information, which is crucial for recognizing fine-grained actions. In this paper, we propose a depth-aware volumetric descriptor that encodes pose and motion information in a unified representation for action classification in-the-wild. Our framework is robust to many challenges inherent to action recognition, e.g. variation in viewpoint, scene, clothing and body shape. The key component of our method is the Depth-Aware Pose Motion representation (DA-PoTion), a new video descriptor that encodes the 3D movement of semantic keypoints of the human body. Given a video, we produce human joint heatmaps for each frame using a state-of-the-art 3D human pose regressor and we give each of them a unique color code according to the relative time in the clip. Then, we aggregate such 3D time-encoded heatmaps for all human joints to obtain a fixed-size descriptor (DA-PoTion), which is suitable for classifying actions using a shallow 3D convolutional neural network (CNN). The DA-PoTion alone defines a new state-of-the-art on the Penn Action Dataset. Moreover, we leverage the intrinsic complementarity of our pose motion descriptor with appearance based approaches by combining it with Inflated 3D ConvNet (I3D) to define a new state-of-the-art on the JHMDB Dataset.