 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLost in Translation? Vocabulary Alignment for Source-Free Domain Adaptation in Open-Vocabulary Semantic Segmentation
Sep 18, 2025



We introduce VocAlign, a novel source-free domain adaptation framework specifically designed for VLMs in open-vocabulary semantic segmentation. Our method adopts a student-teacher paradigm enhanced with a vocabulary alignment strategy, which improves pseudo-label generation by incorporating additional class concepts. To ensure efficiency, we use Low-Rank Adaptation (LoRA) to fine-tune the model, preserving its original capabilities while minimizing computational overhead. In addition, we propose a Top-K class selection mechanism for the student model, which significantly reduces memory requirements while further improving adaptation performance. Our approach achieves a notable 6.11 mIoU improvement on the CityScapes dataset and demonstrates superior performance on zero-shot segmentation benchmarks, setting a new standard for source-free adaptation in the open-vocabulary setting.
Semantic Library Adaptation: LoRA Retrieval and Fusion for Open-Vocabulary Semantic Segmentation
Mar 27, 2025Open-vocabulary semantic segmentation models associate vision and text to label pixels from an undefined set of classes using textual queries, providing versatile performance on novel datasets. However, large shifts between training and test domains degrade their performance, requiring fine-tuning for effective real-world applications. We introduce Semantic Library Adaptation (SemLA), a novel framework for training-free, test-time domain adaptation. SemLA leverages a library of LoRA-based adapters indexed with CLIP embeddings, dynamically merging the most relevant adapters based on proximity to the target domain in the embedding space. This approach constructs an ad-hoc model tailored to each specific input without additional training. Our method scales efficiently, enhances explainability by tracking adapter contributions, and inherently protects data privacy, making it ideal for sensitive applications. Comprehensive experiments on a 20-domain benchmark built over 10 standard datasets demonstrate SemLA's superior adaptability and performance across diverse settings, establishing a new standard in domain adaptation for open-vocabulary semantic segmentation.
UniK3D: Universal Camera Monocular 3D Estimation
Mar 20, 2025



Monocular 3D estimation is crucial for visual perception. However, current methods fall short by relying on oversimplified assumptions, such as pinhole camera models or rectified images. These limitations severely restrict their general applicability, causing poor performance in real-world scenarios with fisheye or panoramic images and resulting in substantial context loss. To address this, we present UniK3D, the first generalizable method for monocular 3D estimation able to model any camera. Our method introduces a spherical 3D representation which allows for better disentanglement of camera and scene geometry and enables accurate metric 3D reconstruction for unconstrained camera models. Our camera component features a novel, model-independent representation of the pencil of rays, achieved through a learned superposition of spherical harmonics. We also introduce an angular loss, which, together with the camera module design, prevents the contraction of the 3D outputs for wide-view cameras. A comprehensive zero-shot evaluation on 13 diverse datasets demonstrates the state-of-the-art performance of UniK3D across 3D, depth, and camera metrics, with substantial gains in challenging large-field-of-view and panoramic settings, while maintaining top accuracy in conventional pinhole small-field-of-view domains. Code and models are available at github.com/lpiccinelli-eth/unik3d .
UniDepthV2: Universal Monocular Metric Depth Estimation Made Simpler
Feb 27, 2025



Accurate monocular metric depth estimation (MMDE) is crucial to solving downstream tasks in 3D perception and modeling. However, the remarkable accuracy of recent MMDE methods is confined to their training domains. These methods fail to generalize to unseen domains even in the presence of moderate domain gaps, which hinders their practical applicability. We propose a new model, UniDepthV2, capable of reconstructing metric 3D scenes from solely single images across domains. Departing from the existing MMDE paradigm, UniDepthV2 directly predicts metric 3D points from the input image at inference time without any additional information, striving for a universal and flexible MMDE solution. In particular, UniDepthV2 implements a self-promptable camera module predicting a dense camera representation to condition depth features. Our model exploits a pseudo-spherical output representation, which disentangles the camera and depth representations. In addition, we propose a geometric invariance loss that promotes the invariance of camera-prompted depth features. UniDepthV2 improves its predecessor UniDepth model via a new edge-guided loss which enhances the localization and sharpness of edges in the metric depth outputs, a revisited, simplified and more efficient architectural design, and an additional uncertainty-level output which enables downstream tasks requiring confidence. Thorough evaluations on ten depth datasets in a zero-shot regime consistently demonstrate the superior performance and generalization of UniDepthV2. Code and models are available at https://github.com/lpiccinelli-eth/UniDepth
Samba: Synchronized Set-of-Sequences Modeling for Multiple Object Tracking
Oct 02, 2024



Multiple object tracking in complex scenarios - such as coordinated dance performances, team sports, or dynamic animal groups - presents unique challenges. In these settings, objects frequently move in coordinated patterns, occlude each other, and exhibit long-term dependencies in their trajectories. However, it remains a key open research question on how to model long-range dependencies within tracklets, interdependencies among tracklets, and the associated temporal occlusions. To this end, we introduce Samba, a novel linear-time set-of-sequences model designed to jointly process multiple tracklets by synchronizing the multiple selective state-spaces used to model each tracklet. Samba autoregressively predicts the future track query for each sequence while maintaining synchronized long-term memory representations across tracklets. By integrating Samba into a tracking-by-propagation framework, we propose SambaMOTR, the first tracker effectively addressing the aforementioned issues, including long-range dependencies, tracklet interdependencies, and temporal occlusions. Additionally, we introduce an effective technique for dealing with uncertain observations (MaskObs) and an efficient training recipe to scale SambaMOTR to longer sequences. By modeling long-range dependencies and interactions among tracked objects, SambaMOTR implicitly learns to track objects accurately through occlusions without any hand-crafted heuristics. Our approach significantly surpasses prior state-of-the-art on the DanceTrack, BFT, and SportsMOT datasets.
Walker: Self-supervised Multiple Object Tracking by Walking on Temporal Appearance Graphs
Sep 25, 2024
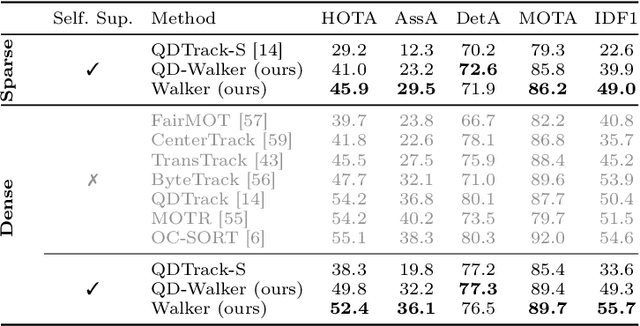

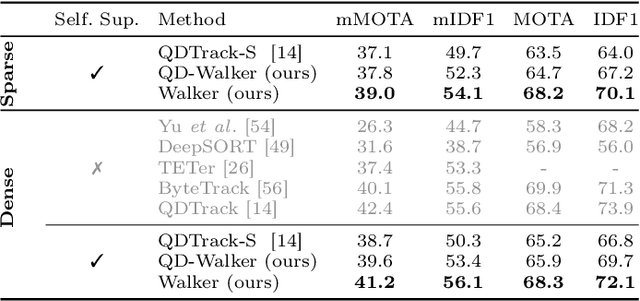
The supervision of state-of-the-art multiple object tracking (MOT) methods requires enormous annotation efforts to provide bounding boxes for all frames of all videos, and instance IDs to associate them through time. To this end, we introduce Walker, the first self-supervised tracker that learns from videos with sparse bounding box annotations, and no tracking labels. First, we design a quasi-dense temporal object appearance graph, and propose a novel multi-positive contrastive objective to optimize random walks on the graph and learn instance similarities. Then, we introduce an algorithm to enforce mutually-exclusive connective properties across instances in the graph, optimizing the learned topology for MOT. At inference time, we propose to associate detected instances to tracklets based on the max-likelihood transition state under motion-constrained bi-directional walks. Walker is the first self-supervised tracker to achieve competitive performance on MOT17, DanceTrack, and BDD100K. Remarkably, our proposal outperforms the previous self-supervised trackers even when drastically reducing the annotation requirements by up to 400x.
Matching Anything by Segmenting Anything
Jun 06, 2024



The robust association of the same objects across video frames in complex scenes is crucial for many applications, especially Multiple Object Tracking (MOT). Current methods predominantly rely on labeled domain-specific video datasets, which limits the cross-domain generalization of learned similarity embeddings. We propose MASA, a novel method for robust instance association learning, capable of matching any objects within videos across diverse domains without tracking labels. Leveraging the rich object segmentation from the Segment Anything Model (SAM), MASA learns instance-level correspondence through exhaustive data transformations. We treat the SAM outputs as dense object region proposals and learn to match those regions from a vast image collection. We further design a universal MASA adapter which can work in tandem with foundational segmentation or detection models and enable them to track any detected objects. Those combinations present strong zero-shot tracking ability in complex domains. Extensive tests on multiple challenging MOT and MOTS benchmarks indicate that the proposed method, using only unlabeled static images, achieves even better performance than state-of-the-art methods trained with fully annotated in-domain video sequences, in zero-shot association. Project Page: https://matchinganything.github.io/
Know Your Neighbors: Improving Single-View Reconstruction via Spatial Vision-Language Reasoning
Apr 04, 2024Recovering the 3D scene geometry from a single view is a fundamental yet ill-posed problem in computer vision. While classical depth estimation methods infer only a 2.5D scene representation limited to the image plane, recent approaches based on radiance fields reconstruct a full 3D representation. However, these methods still struggle with occluded regions since inferring geometry without visual observation requires (i) semantic knowledge of the surroundings, and (ii) reasoning about spatial context. We propose KYN, a novel method for single-view scene reconstruction that reasons about semantic and spatial context to predict each point's density. We introduce a vision-language modulation module to enrich point features with fine-grained semantic information. We aggregate point representations across the scene through a language-guided spatial attention mechanism to yield per-point density predictions aware of the 3D semantic context. We show that KYN improves 3D shape recovery compared to predicting density for each 3D point in isolation. We achieve state-of-the-art results in scene and object reconstruction on KITTI-360, and show improved zero-shot generalization compared to prior work. Project page: https://ruili3.github.io/kyn.
UniDepth: Universal Monocular Metric Depth Estimation
Mar 27, 2024



Accurate monocular metric depth estimation (MMDE) is crucial to solving downstream tasks in 3D perception and modeling. However, the remarkable accuracy of recent MMDE methods is confined to their training domains. These methods fail to generalize to unseen domains even in the presence of moderate domain gaps, which hinders their practical applicability. We propose a new model, UniDepth, capable of reconstructing metric 3D scenes from solely single images across domains. Departing from the existing MMDE methods, UniDepth directly predicts metric 3D points from the input image at inference time without any additional information, striving for a universal and flexible MMDE solution. In particular, UniDepth implements a self-promptable camera module predicting dense camera representation to condition depth features. Our model exploits a pseudo-spherical output representation, which disentangles camera and depth representations. In addition, we propose a geometric invariance loss that promotes the invariance of camera-prompted depth features. Thorough evaluations on ten datasets in a zero-shot regime consistently demonstrate the superior performance of UniDepth, even when compared with methods directly trained on the testing domains. Code and models are available at: https://github.com/lpiccinelli-eth/unidepth
COOLer: Class-Incremental Learning for Appearance-Based Multiple Object Tracking
Oct 05, 2023



Continual learning allows a model to learn multiple tasks sequentially while retaining the old knowledge without the training data of the preceding tasks. This paper extends the scope of continual learning research to class-incremental learning for multiple object tracking (MOT), which is desirable to accommodate the continuously evolving needs of autonomous systems. Previous solutions for continual learning of object detectors do not address the data association stage of appearance-based trackers, leading to catastrophic forgetting of previous classes' re-identification features. We introduce COOLer, a COntrastive- and cOntinual-Learning-based tracker, which incrementally learns to track new categories while preserving past knowledge by training on a combination of currently available ground truth labels and pseudo-labels generated by the past tracker. To further exacerbate the disentanglement of instance representations, we introduce a novel contrastive class-incremental instance representation learning technique. Finally, we propose a practical evaluation protocol for continual learning for MOT and conduct experiments on the BDD100K and SHIFT datasets. Experimental results demonstrate that COOLer continually learns while effectively addressing catastrophic forgetting of both tracking and detection. The code is available at https://github.com/BoSmallEar/COOLer.