 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Depth Propagation
Dec 11, 2025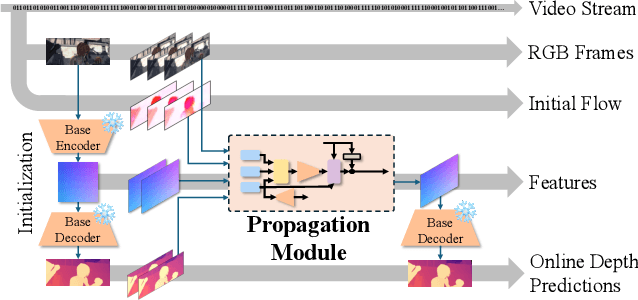
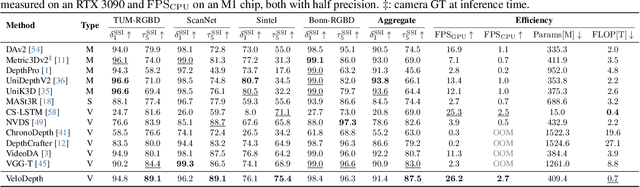
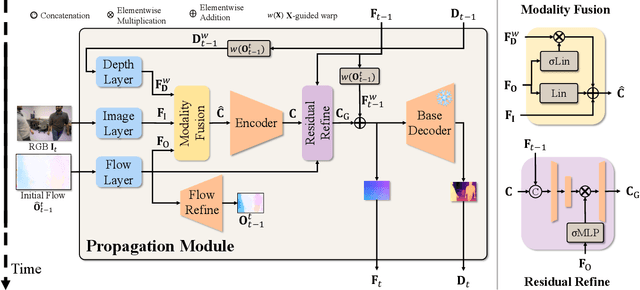
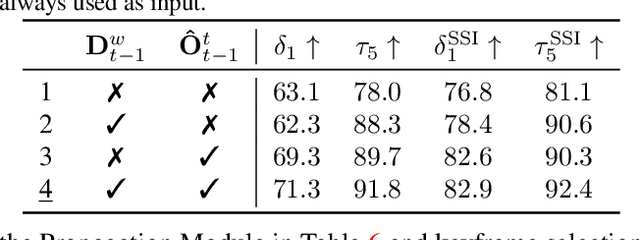
Depth estimation in videos is essential for visual perception in real-world applications. However, existing methods either rely on simple frame-by-frame monocular models, leading to temporal inconsistencies and inaccuracies, or use computationally demanding temporal modeling, unsuitable for real-time applications. These limitations significantly restrict general applicability and performance in practical settings. To address this, we propose VeloDepth, an efficient and robust online video depth estimation pipeline that effectively leverages spatiotemporal priors from previous depth predictions and performs deep feature propagation. Our method introduces a novel Propagation Module that refines and propagates depth features and predictions using flow-based warping coupled with learned residual corrections. In addition, our design structurally enforces temporal consistency, resulting in stable depth predictions across consecutive frames with improved efficiency. Comprehensive zero-shot evaluation on multiple benchmarks demonstrates the state-of-the-art temporal consistency and competitive accuracy of VeloDepth, alongside its significantly faster inference compared to existing video-based depth estimators. VeloDepth thus provides a practical, efficient, and accurate solution for real-time depth estimation suitable for diverse perception tasks. Code and models are available at https://github.com/lpiccinelli-eth/velodepth
UniK3D: Universal Camera Monocular 3D Estimation
Mar 20, 2025



Monocular 3D estimation is crucial for visual perception. However, current methods fall short by relying on oversimplified assumptions, such as pinhole camera models or rectified images. These limitations severely restrict their general applicability, causing poor performance in real-world scenarios with fisheye or panoramic images and resulting in substantial context loss. To address this, we present UniK3D, the first generalizable method for monocular 3D estimation able to model any camera. Our method introduces a spherical 3D representation which allows for better disentanglement of camera and scene geometry and enables accurate metric 3D reconstruction for unconstrained camera models. Our camera component features a novel, model-independent representation of the pencil of rays, achieved through a learned superposition of spherical harmonics. We also introduce an angular loss, which, together with the camera module design, prevents the contraction of the 3D outputs for wide-view cameras. A comprehensive zero-shot evaluation on 13 diverse datasets demonstrates the state-of-the-art performance of UniK3D across 3D, depth, and camera metrics, with substantial gains in challenging large-field-of-view and panoramic settings, while maintaining top accuracy in conventional pinhole small-field-of-view domains. Code and models are available at github.com/lpiccinelli-eth/unik3d .
UniDepthV2: Universal Monocular Metric Depth Estimation Made Simpler
Feb 27, 2025



Accurate monocular metric depth estimation (MMDE) is crucial to solving downstream tasks in 3D perception and modeling. However, the remarkable accuracy of recent MMDE methods is confined to their training domains. These methods fail to generalize to unseen domains even in the presence of moderate domain gaps, which hinders their practical applicability. We propose a new model, UniDepthV2, capable of reconstructing metric 3D scenes from solely single images across domains. Departing from the existing MMDE paradigm, UniDepthV2 directly predicts metric 3D points from the input image at inference time without any additional information, striving for a universal and flexible MMDE solution. In particular, UniDepthV2 implements a self-promptable camera module predicting a dense camera representation to condition depth features. Our model exploits a pseudo-spherical output representation, which disentangles the camera and depth representations. In addition, we propose a geometric invariance loss that promotes the invariance of camera-prompted depth features. UniDepthV2 improves its predecessor UniDepth model via a new edge-guided loss which enhances the localization and sharpness of edges in the metric depth outputs, a revisited, simplified and more efficient architectural design, and an additional uncertainty-level output which enables downstream tasks requiring confidence. Thorough evaluations on ten depth datasets in a zero-shot regime consistently demonstrate the superior performance and generalization of UniDepthV2. Code and models are available at https://github.com/lpiccinelli-eth/UniDepth
Samba: Synchronized Set-of-Sequences Modeling for Multiple Object Tracking
Oct 02, 2024



Multiple object tracking in complex scenarios - such as coordinated dance performances, team sports, or dynamic animal groups - presents unique challenges. In these settings, objects frequently move in coordinated patterns, occlude each other, and exhibit long-term dependencies in their trajectories. However, it remains a key open research question on how to model long-range dependencies within tracklets, interdependencies among tracklets, and the associated temporal occlusions. To this end, we introduce Samba, a novel linear-time set-of-sequences model designed to jointly process multiple tracklets by synchronizing the multiple selective state-spaces used to model each tracklet. Samba autoregressively predicts the future track query for each sequence while maintaining synchronized long-term memory representations across tracklets. By integrating Samba into a tracking-by-propagation framework, we propose SambaMOTR, the first tracker effectively addressing the aforementioned issues, including long-range dependencies, tracklet interdependencies, and temporal occlusions. Additionally, we introduce an effective technique for dealing with uncertain observations (MaskObs) and an efficient training recipe to scale SambaMOTR to longer sequences. By modeling long-range dependencies and interactions among tracked objects, SambaMOTR implicitly learns to track objects accurately through occlusions without any hand-crafted heuristics. Our approach significantly surpasses prior state-of-the-art on the DanceTrack, BFT, and SportsMOT datasets.
Walker: Self-supervised Multiple Object Tracking by Walking on Temporal Appearance Graphs
Sep 25, 2024
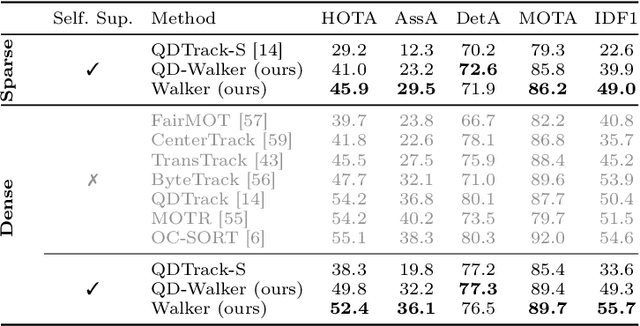

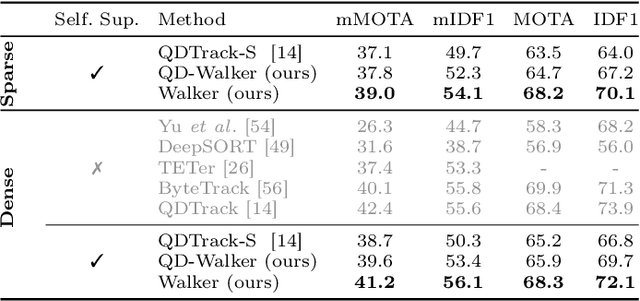
The supervision of state-of-the-art multiple object tracking (MOT) methods requires enormous annotation efforts to provide bounding boxes for all frames of all videos, and instance IDs to associate them through time. To this end, we introduce Walker, the first self-supervised tracker that learns from videos with sparse bounding box annotations, and no tracking labels. First, we design a quasi-dense temporal object appearance graph, and propose a novel multi-positive contrastive objective to optimize random walks on the graph and learn instance similarities. Then, we introduce an algorithm to enforce mutually-exclusive connective properties across instances in the graph, optimizing the learned topology for MOT. At inference time, we propose to associate detected instances to tracklets based on the max-likelihood transition state under motion-constrained bi-directional walks. Walker is the first self-supervised tracker to achieve competitive performance on MOT17, DanceTrack, and BDD100K. Remarkably, our proposal outperforms the previous self-supervised trackers even when drastically reducing the annotation requirements by up to 400x.
SLAck: Semantic, Location, and Appearance Aware Open-Vocabulary Tracking
Sep 17, 2024
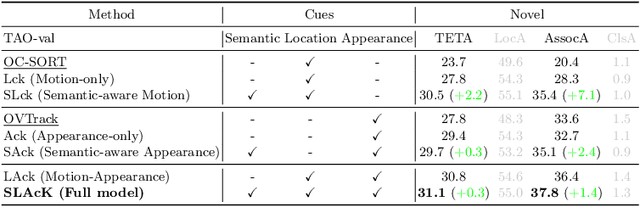
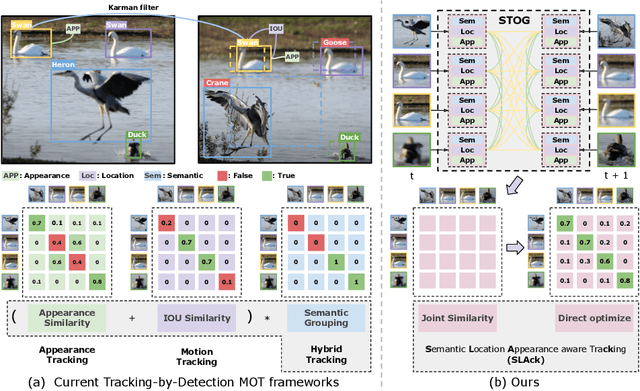

Open-vocabulary Multiple Object Tracking (MOT) aims to generalize trackers to novel categories not in the training set. Currently, the best-performing methods are mainly based on pure appearance matching. Due to the complexity of motion patterns in the large-vocabulary scenarios and unstable classification of the novel objects, the motion and semantics cues are either ignored or applied based on heuristics in the final matching steps by existing methods. In this paper, we present a unified framework SLAck that jointly considers semantics, location, and appearance priors in the early steps of association and learns how to integrate all valuable information through a lightweight spatial and temporal object graph. Our method eliminates complex post-processing heuristics for fusing different cues and boosts the association performance significantly for large-scale open-vocabulary tracking. Without bells and whistles, we outperform previous state-of-the-art methods for novel classes tracking on the open-vocabulary MOT and TAO TETA benchmarks. Our code is available at \href{https://github.com/siyuanliii/SLAck}{github.com/siyuanliii/SLAck}.
Matching Anything by Segmenting Anything
Jun 06, 2024



The robust association of the same objects across video frames in complex scenes is crucial for many applications, especially Multiple Object Tracking (MOT). Current methods predominantly rely on labeled domain-specific video datasets, which limits the cross-domain generalization of learned similarity embeddings. We propose MASA, a novel method for robust instance association learning, capable of matching any objects within videos across diverse domains without tracking labels. Leveraging the rich object segmentation from the Segment Anything Model (SAM), MASA learns instance-level correspondence through exhaustive data transformations. We treat the SAM outputs as dense object region proposals and learn to match those regions from a vast image collection. We further design a universal MASA adapter which can work in tandem with foundational segmentation or detection models and enable them to track any detected objects. Those combinations present strong zero-shot tracking ability in complex domains. Extensive tests on multiple challenging MOT and MOTS benchmarks indicate that the proposed method, using only unlabeled static images, achieves even better performance than state-of-the-art methods trained with fully annotated in-domain video sequences, in zero-shot association. Project Page: https://matchinganything.github.io/
UniDepth: Universal Monocular Metric Depth Estimation
Mar 27, 2024



Accurate monocular metric depth estimation (MMDE) is crucial to solving downstream tasks in 3D perception and modeling. However, the remarkable accuracy of recent MMDE methods is confined to their training domains. These methods fail to generalize to unseen domains even in the presence of moderate domain gaps, which hinders their practical applicability. We propose a new model, UniDepth, capable of reconstructing metric 3D scenes from solely single images across domains. Departing from the existing MMDE methods, UniDepth directly predicts metric 3D points from the input image at inference time without any additional information, striving for a universal and flexible MMDE solution. In particular, UniDepth implements a self-promptable camera module predicting dense camera representation to condition depth features. Our model exploits a pseudo-spherical output representation, which disentangles camera and depth representations. In addition, we propose a geometric invariance loss that promotes the invariance of camera-prompted depth features. Thorough evaluations on ten datasets in a zero-shot regime consistently demonstrate the superior performance of UniDepth, even when compared with methods directly trained on the testing domains. Code and models are available at: https://github.com/lpiccinelli-eth/unidepth
iDisc: Internal Discretization for Monocular Depth Estimation
Apr 13, 2023


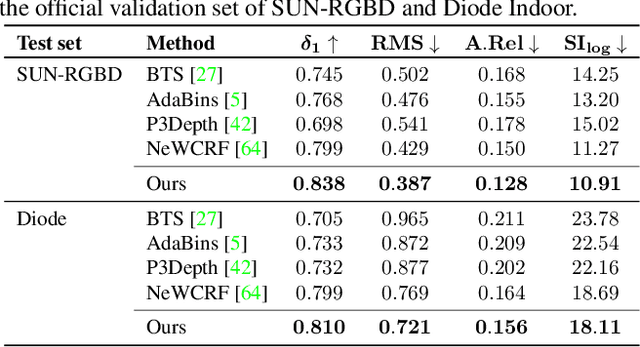
Monocular depth estimation is fundamental for 3D scene understanding and downstream applications. However, even under the supervised setup, it is still challenging and ill-posed due to the lack of full geometric constraints. Although a scene can consist of millions of pixels, there are fewer high-level patterns. We propose iDisc to learn those patterns with internal discretized representations. The method implicitly partitions the scene into a set of high-level patterns. In particular, our new module, Internal Discretization (ID), implements a continuous-discrete-continuous bottleneck to learn those concepts without supervision. In contrast to state-of-the-art methods, the proposed model does not enforce any explicit constraints or priors on the depth output. The whole network with the ID module can be trained end-to-end, thanks to the bottleneck module based on attention. Our method sets the new state of the art with significant improvements on NYU-Depth v2 and KITTI, outperforming all published methods on the official KITTI benchmark. iDisc can also achieve state-of-the-art results on surface normal estimation. Further, we explore the model generalization capability via zero-shot testing. We observe the compelling need to promote diversification in the outdoor scenario. Hence, we introduce splits of two autonomous driving datasets, DDAD and Argoverse. Code is available at http://vis.xyz/pub/idisc .
Multi-scale Feature Alignment for Continual Learning of Unlabeled Domains
Feb 02, 2023Methods for unsupervised domain adaptation (UDA) help to improve the performance of deep neural networks on unseen domains without any labeled data. Especially in medical disciplines such as histopathology, this is crucial since large datasets with detailed annotations are scarce. While the majority of existing UDA methods focus on the adaptation from a labeled source to a single unlabeled target domain, many real-world applications with a long life cycle involve more than one target domain. Thus, the ability to sequentially adapt to multiple target domains becomes essential. In settings where the data from previously seen domains cannot be stored, e.g., due to data protection regulations, the above becomes a challenging continual learning problem. To this end, we propose to use generative feature-driven image replay in conjunction with a dual-purpose discriminator that not only enables the generation of images with realistic features for replay, but also promotes feature alignment during domain adaptation. We evaluate our approach extensively on a sequence of three histopathological datasets for tissue-type classification, achieving state-of-the-art results. We present detailed ablation experiments studying our proposed method components and demonstrate a possible use-case of our continual UDA method for an unsupervised patch-based segmentation task given high-resolution tissue images.