 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowR: Flowing from Sparse to Dense 3D Reconstructions
Apr 02, 2025



3D Gaussian splatting enables high-quality novel view synthesis (NVS) at real-time frame rates. However, its quality drops sharply as we depart from the training views. Thus, dense captures are needed to match the high-quality expectations of some applications, e.g. Virtual Reality (VR). However, such dense captures are very laborious and expensive to obtain. Existing works have explored using 2D generative models to alleviate this requirement by distillation or generating additional training views. These methods are often conditioned only on a handful of reference input views and thus do not fully exploit the available 3D information, leading to inconsistent generation results and reconstruction artifacts. To tackle this problem, we propose a multi-view, flow matching model that learns a flow to connect novel view renderings from possibly sparse reconstructions to renderings that we expect from dense reconstructions. This enables augmenting scene captures with novel, generated views to improve reconstruction quality. Our model is trained on a novel dataset of 3.6M image pairs and can process up to 45 views at 540x960 resolution (91K tokens) on one H100 GPU in a single forward pass. Our pipeline consistently improves NVS in sparse- and dense-view scenarios, leading to higher-quality reconstructions than prior works across multiple, widely-used NVS benchmarks.
UniK3D: Universal Camera Monocular 3D Estimation
Mar 20, 2025



Monocular 3D estimation is crucial for visual perception. However, current methods fall short by relying on oversimplified assumptions, such as pinhole camera models or rectified images. These limitations severely restrict their general applicability, causing poor performance in real-world scenarios with fisheye or panoramic images and resulting in substantial context loss. To address this, we present UniK3D, the first generalizable method for monocular 3D estimation able to model any camera. Our method introduces a spherical 3D representation which allows for better disentanglement of camera and scene geometry and enables accurate metric 3D reconstruction for unconstrained camera models. Our camera component features a novel, model-independent representation of the pencil of rays, achieved through a learned superposition of spherical harmonics. We also introduce an angular loss, which, together with the camera module design, prevents the contraction of the 3D outputs for wide-view cameras. A comprehensive zero-shot evaluation on 13 diverse datasets demonstrates the state-of-the-art performance of UniK3D across 3D, depth, and camera metrics, with substantial gains in challenging large-field-of-view and panoramic settings, while maintaining top accuracy in conventional pinhole small-field-of-view domains. Code and models are available at github.com/lpiccinelli-eth/unik3d .
UniDepthV2: Universal Monocular Metric Depth Estimation Made Simpler
Feb 27, 2025



Accurate monocular metric depth estimation (MMDE) is crucial to solving downstream tasks in 3D perception and modeling. However, the remarkable accuracy of recent MMDE methods is confined to their training domains. These methods fail to generalize to unseen domains even in the presence of moderate domain gaps, which hinders their practical applicability. We propose a new model, UniDepthV2, capable of reconstructing metric 3D scenes from solely single images across domains. Departing from the existing MMDE paradigm, UniDepthV2 directly predicts metric 3D points from the input image at inference time without any additional information, striving for a universal and flexible MMDE solution. In particular, UniDepthV2 implements a self-promptable camera module predicting a dense camera representation to condition depth features. Our model exploits a pseudo-spherical output representation, which disentangles the camera and depth representations. In addition, we propose a geometric invariance loss that promotes the invariance of camera-prompted depth features. UniDepthV2 improves its predecessor UniDepth model via a new edge-guided loss which enhances the localization and sharpness of edges in the metric depth outputs, a revisited, simplified and more efficient architectural design, and an additional uncertainty-level output which enables downstream tasks requiring confidence. Thorough evaluations on ten depth datasets in a zero-shot regime consistently demonstrate the superior performance and generalization of UniDepthV2. Code and models are available at https://github.com/lpiccinelli-eth/UniDepth
Samba: Synchronized Set-of-Sequences Modeling for Multiple Object Tracking
Oct 02, 2024



Multiple object tracking in complex scenarios - such as coordinated dance performances, team sports, or dynamic animal groups - presents unique challenges. In these settings, objects frequently move in coordinated patterns, occlude each other, and exhibit long-term dependencies in their trajectories. However, it remains a key open research question on how to model long-range dependencies within tracklets, interdependencies among tracklets, and the associated temporal occlusions. To this end, we introduce Samba, a novel linear-time set-of-sequences model designed to jointly process multiple tracklets by synchronizing the multiple selective state-spaces used to model each tracklet. Samba autoregressively predicts the future track query for each sequence while maintaining synchronized long-term memory representations across tracklets. By integrating Samba into a tracking-by-propagation framework, we propose SambaMOTR, the first tracker effectively addressing the aforementioned issues, including long-range dependencies, tracklet interdependencies, and temporal occlusions. Additionally, we introduce an effective technique for dealing with uncertain observations (MaskObs) and an efficient training recipe to scale SambaMOTR to longer sequences. By modeling long-range dependencies and interactions among tracked objects, SambaMOTR implicitly learns to track objects accurately through occlusions without any hand-crafted heuristics. Our approach significantly surpasses prior state-of-the-art on the DanceTrack, BFT, and SportsMOT datasets.
SLAck: Semantic, Location, and Appearance Aware Open-Vocabulary Tracking
Sep 17, 2024
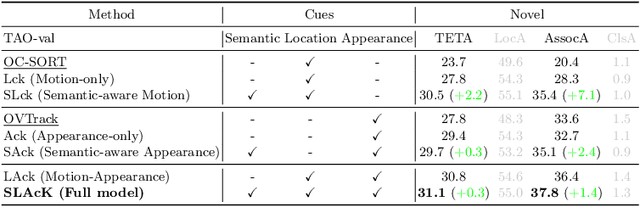
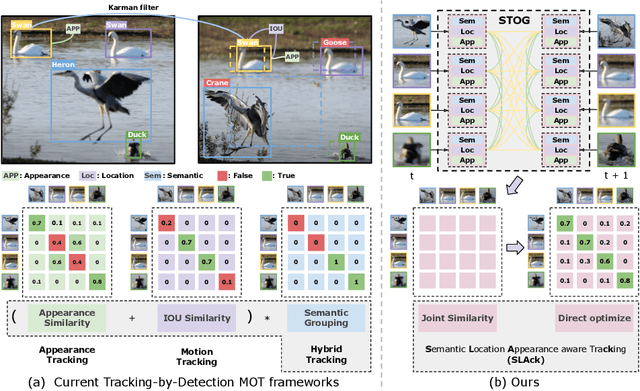

Open-vocabulary Multiple Object Tracking (MOT) aims to generalize trackers to novel categories not in the training set. Currently, the best-performing methods are mainly based on pure appearance matching. Due to the complexity of motion patterns in the large-vocabulary scenarios and unstable classification of the novel objects, the motion and semantics cues are either ignored or applied based on heuristics in the final matching steps by existing methods. In this paper, we present a unified framework SLAck that jointly considers semantics, location, and appearance priors in the early steps of association and learns how to integrate all valuable information through a lightweight spatial and temporal object graph. Our method eliminates complex post-processing heuristics for fusing different cues and boosts the association performance significantly for large-scale open-vocabulary tracking. Without bells and whistles, we outperform previous state-of-the-art methods for novel classes tracking on the open-vocabulary MOT and TAO TETA benchmarks. Our code is available at \href{https://github.com/siyuanliii/SLAck}{github.com/siyuanliii/SLAck}.
UniDepth: Universal Monocular Metric Depth Estimation
Mar 27, 2024



Accurate monocular metric depth estimation (MMDE) is crucial to solving downstream tasks in 3D perception and modeling. However, the remarkable accuracy of recent MMDE methods is confined to their training domains. These methods fail to generalize to unseen domains even in the presence of moderate domain gaps, which hinders their practical applicability. We propose a new model, UniDepth, capable of reconstructing metric 3D scenes from solely single images across domains. Departing from the existing MMDE methods, UniDepth directly predicts metric 3D points from the input image at inference time without any additional information, striving for a universal and flexible MMDE solution. In particular, UniDepth implements a self-promptable camera module predicting dense camera representation to condition depth features. Our model exploits a pseudo-spherical output representation, which disentangles camera and depth representations. In addition, we propose a geometric invariance loss that promotes the invariance of camera-prompted depth features. Thorough evaluations on ten datasets in a zero-shot regime consistently demonstrate the superior performance of UniDepth, even when compared with methods directly trained on the testing domains. Code and models are available at: https://github.com/lpiccinelli-eth/unidepth
CR3DT: Camera-RADAR Fusion for 3D Detection and Tracking
Mar 22, 2024



Accurate detection and tracking of surrounding objects is essential to enable self-driving vehicles. While Light Detection and Ranging (LiDAR) sensors have set the benchmark for high performance, the appeal of camera-only solutions lies in their cost-effectiveness. Notably, despite the prevalent use of Radio Detection and Ranging (RADAR) sensors in automotive systems, their potential in 3D detection and tracking has been largely disregarded due to data sparsity and measurement noise. As a recent development, the combination of RADARs and cameras is emerging as a promising solution. This paper presents Camera-RADAR 3D Detection and Tracking (CR3DT), a camera-RADAR fusion model for 3D object detection, and Multi-Object Tracking (MOT). Building upon the foundations of the State-of-the-Art (SotA) camera-only BEVDet architecture, CR3DT demonstrates substantial improvements in both detection and tracking capabilities, by incorporating the spatial and velocity information of the RADAR sensor. Experimental results demonstrate an absolute improvement in detection performance of 5.3% in mean Average Precision (mAP) and a 14.9% increase in Average Multi-Object Tracking Accuracy (AMOTA) on the nuScenes dataset when leveraging both modalities. CR3DT bridges the gap between high-performance and cost-effective perception systems in autonomous driving, by capitalizing on the ubiquitous presence of RADAR in automotive applications.
CC-3DT: Panoramic 3D Object Tracking via Cross-Camera Fusion
Dec 02, 2022



To track the 3D locations and trajectories of the other traffic participants at any given time, modern autonomous vehicles are equipped with multiple cameras that cover the vehicle's full surroundings. Yet, camera-based 3D object tracking methods prioritize optimizing the single-camera setup and resort to post-hoc fusion in a multi-camera setup. In this paper, we propose a method for panoramic 3D object tracking, called CC-3DT, that associates and models object trajectories both temporally and across views, and improves the overall tracking consistency. In particular, our method fuses 3D detections from multiple cameras before association, reducing identity switches significantly and improving motion modeling. Our experiments on large-scale driving datasets show that fusion before association leads to a large margin of improvement over post-hoc fusion. We set a new state-of-the-art with 12.6% improvement in average multi-object tracking accuracy (AMOTA) among all camera-based methods on the competitive NuScenes 3D tracking benchmark, outperforming previously published methods by 6.5% in AMOTA with the same 3D detector.
Dense Prediction with Attentive Feature Aggregation
Nov 01, 2021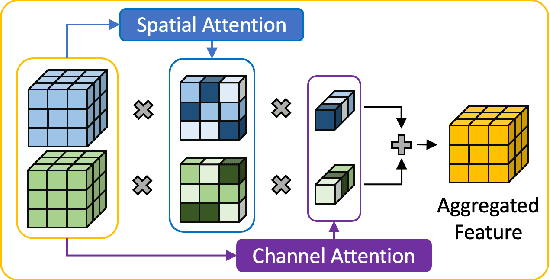

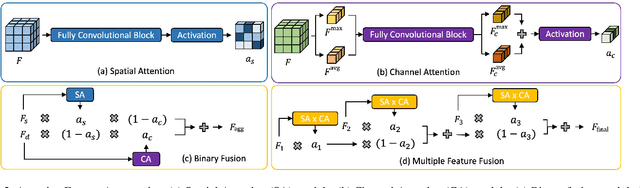
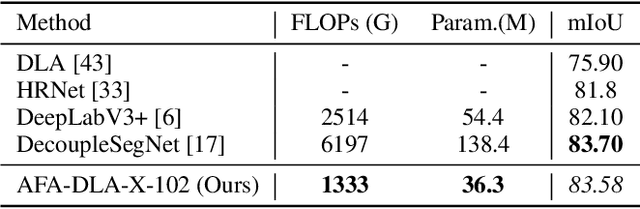
Aggregating information from features across different layers is an essential operation for dense prediction models. Despite its limited expressiveness, feature concatenation dominates the choice of aggregation operations. In this paper, we introduce Attentive Feature Aggregation (AFA) to fuse different network layers with more expressive non-linear operations. AFA exploits both spatial and channel attention to compute weighted average of the layer activations. Inspired by neural volume rendering, we extend AFA with Scale-Space Rendering (SSR) to perform late fusion of multi-scale predictions. AFA is applicable to a wide range of existing network designs. Our experiments show consistent and significant improvements on challenging semantic segmentation benchmarks, including Cityscapes, BDD100K, and Mapillary Vistas, at negligible computational and parameter overhead. In particular, AFA improves the performance of the Deep Layer Aggregation (DLA) model by nearly 6% mIoU on Cityscapes. Our experimental analyses show that AFA learns to progressively refine segmentation maps and to improve boundary details, leading to new state-of-the-art results on boundary detection benchmarks on BSDS500 and NYUDv2. Code and video resources are available at http://vis.xyz/pub/dla-afa.
Monocular Quasi-Dense 3D Object Tracking
Mar 12, 2021
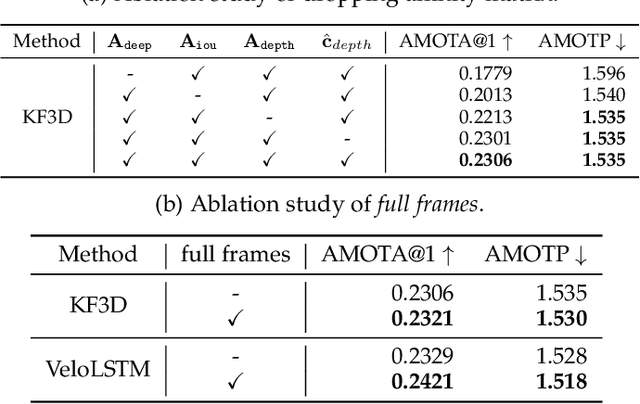
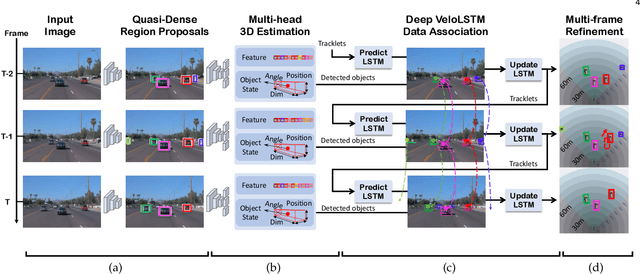
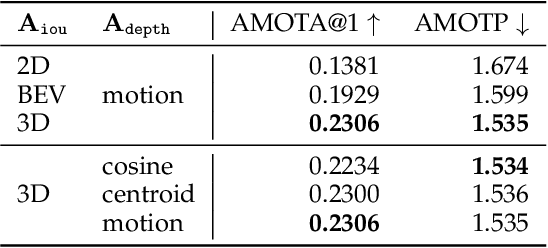
A reliable and accurate 3D tracking framework is essential for predicting future locations of surrounding objects and planning the observer's actions in numerous applications such as autonomous driving. We propose a framework that can effectively associate moving objects over time and estimate their full 3D bounding box information from a sequence of 2D images captured on a moving platform. The object association leverages quasi-dense similarity learning to identify objects in various poses and viewpoints with appearance cues only. After initial 2D association, we further utilize 3D bounding boxes depth-ordering heuristics for robust instance association and motion-based 3D trajectory prediction for re-identification of occluded vehicles. In the end, an LSTM-based object velocity learning module aggregates the long-term trajectory information for more accurate motion extrapolation. Experiments on our proposed simulation data and real-world benchmarks, including KITTI, nuScenes, and Waymo datasets, show that our tracking framework offers robust object association and tracking on urban-driving scenarios. On the Waymo Open benchmark, we establish the first camera-only baseline in the 3D tracking and 3D detection challenges. Our quasi-dense 3D tracking pipeline achieves impressive improvements on the nuScenes 3D tracking benchmark with near five times tracking accuracy of the best vision-only submission among all published methods. Our code, data and trained models are available at https://github.com/SysCV/qd-3dt.