 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRoPS: Dynamic 3D Reconstruction of Pre-Scanned Objects
Mar 25, 2026Dynamic scene reconstruction from casual videos has seen recent remarkable progress. Numerous approaches have attempted to overcome the ill-posedness of the task by distilling priors from 2D foundational models and by imposing hand-crafted regularization on the optimized motion. However, these methods struggle to reconstruct scenes from extreme novel viewpoints, especially when highly articulated motions are present. In this paper, we present DRoPS, a novel approach that leverages a static pre-scan of the dynamic object as an explicit geometric and appearance prior. While existing state-of-the-art methods fail to fully exploit the pre-scan, DRoPS leverages our novel setup to effectively constrain the solution space and ensure geometrical consistency throughout the sequence. The core of our novelty is twofold: first, we establish a grid-structured and surface-aligned model by organizing Gaussian primitives into pixel grids anchored to the object surface. Second, by leveraging the grid structure of our primitives, we parameterize motion using a CNN conditioned on those grids, injecting strong implicit regularization and correlating the motion of nearby points. Extensive experiments demonstrate that our method significantly outperforms the current state of the art in rendering quality and 3D tracking accuracy.
FlowR: Flowing from Sparse to Dense 3D Reconstructions
Apr 02, 2025



3D Gaussian splatting enables high-quality novel view synthesis (NVS) at real-time frame rates. However, its quality drops sharply as we depart from the training views. Thus, dense captures are needed to match the high-quality expectations of some applications, e.g. Virtual Reality (VR). However, such dense captures are very laborious and expensive to obtain. Existing works have explored using 2D generative models to alleviate this requirement by distillation or generating additional training views. These methods are often conditioned only on a handful of reference input views and thus do not fully exploit the available 3D information, leading to inconsistent generation results and reconstruction artifacts. To tackle this problem, we propose a multi-view, flow matching model that learns a flow to connect novel view renderings from possibly sparse reconstructions to renderings that we expect from dense reconstructions. This enables augmenting scene captures with novel, generated views to improve reconstruction quality. Our model is trained on a novel dataset of 3.6M image pairs and can process up to 45 views at 540x960 resolution (91K tokens) on one H100 GPU in a single forward pass. Our pipeline consistently improves NVS in sparse- and dense-view scenarios, leading to higher-quality reconstructions than prior works across multiple, widely-used NVS benchmarks.
SplaTAM: Splat, Track & Map 3D Gaussians for Dense RGB-D SLAM
Dec 04, 2023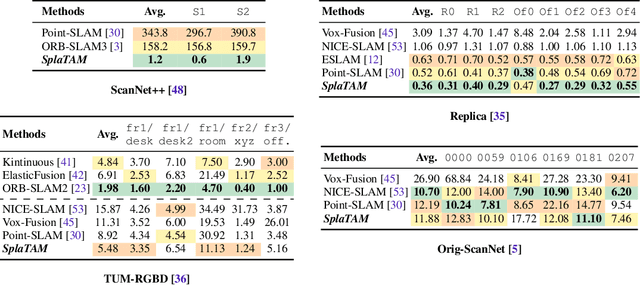
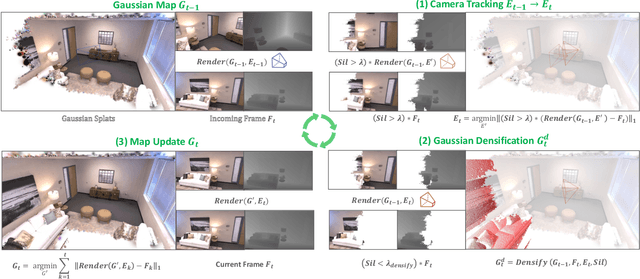
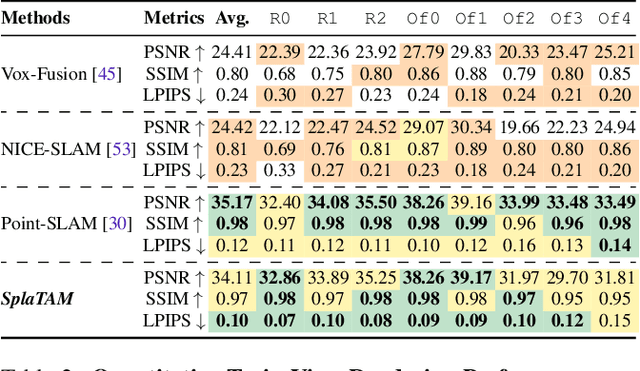

Dense simultaneous localization and mapping (SLAM) is pivotal for embodied scene understanding. Recent work has shown that 3D Gaussians enable high-quality reconstruction and real-time rendering of scenes using multiple posed cameras. In this light, we show for the first time that representing a scene by 3D Gaussians can enable dense SLAM using a single unposed monocular RGB-D camera. Our method, SplaTAM, addresses the limitations of prior radiance field-based representations, including fast rendering and optimization, the ability to determine if areas have been previously mapped, and structured map expansion by adding more Gaussians. We employ an online tracking and mapping pipeline while tailoring it to specifically use an underlying Gaussian representation and silhouette-guided optimization via differentiable rendering. Extensive experiments show that SplaTAM achieves up to 2X state-of-the-art performance in camera pose estimation, map construction, and novel-view synthesis, demonstrating its superiority over existing approaches, while allowing real-time rendering of a high-resolution dense 3D map.
Dynamic 3D Gaussians: Tracking by Persistent Dynamic View Synthesis
Aug 18, 2023



We present a method that simultaneously addresses the tasks of dynamic scene novel-view synthesis and six degree-of-freedom (6-DOF) tracking of all dense scene elements. We follow an analysis-by-synthesis framework, inspired by recent work that models scenes as a collection of 3D Gaussians which are optimized to reconstruct input images via differentiable rendering. To model dynamic scenes, we allow Gaussians to move and rotate over time while enforcing that they have persistent color, opacity, and size. By regularizing Gaussians' motion and rotation with local-rigidity constraints, we show that our Dynamic 3D Gaussians correctly model the same area of physical space over time, including the rotation of that space. Dense 6-DOF tracking and dynamic reconstruction emerges naturally from persistent dynamic view synthesis, without requiring any correspondence or flow as input. We demonstrate a large number of downstream applications enabled by our representation, including first-person view synthesis, dynamic compositional scene synthesis, and 4D video editing.
TarViS: A Unified Approach for Target-based Video Segmentation
Jan 06, 2023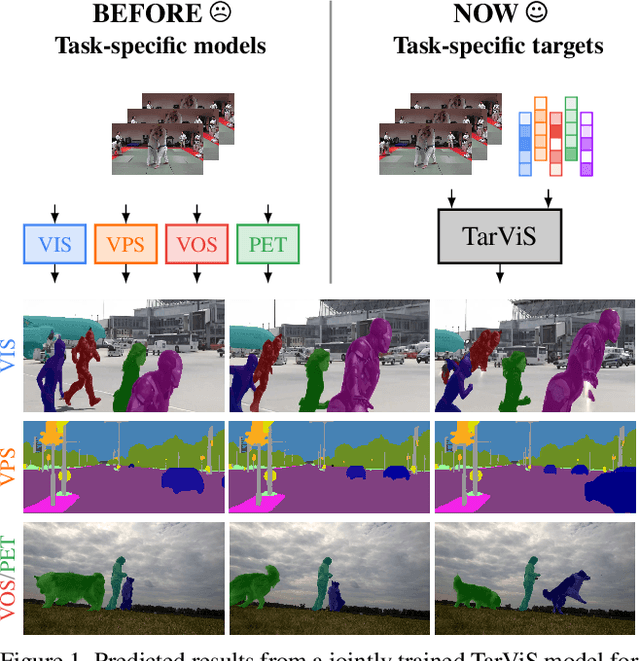
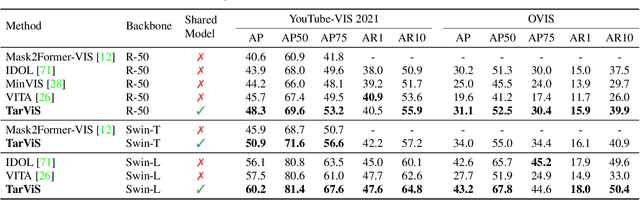
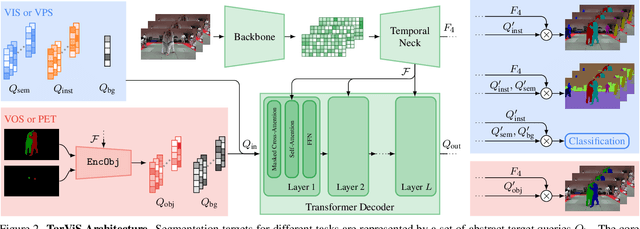
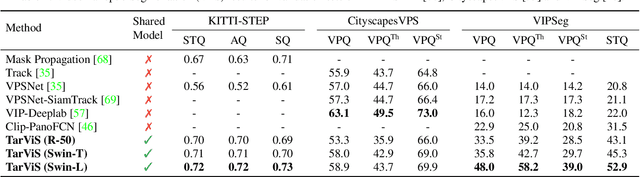
The general domain of video segmentation is currently fragmented into different tasks spanning multiple benchmarks. Despite rapid progress in the state-of-the-art, current methods are overwhelmingly task-specific and cannot conceptually generalize to other tasks. Inspired by recent approaches with multi-task capability, we propose TarViS: a novel, unified network architecture that can be applied to any task that requires segmenting a set of arbitrarily defined 'targets' in video. Our approach is flexible with respect to how tasks define these targets, since it models the latter as abstract 'queries' which are then used to predict pixel-precise target masks. A single TarViS model can be trained jointly on a collection of datasets spanning different tasks, and can hot-swap between tasks during inference without any task-specific retraining. To demonstrate its effectiveness, we apply TarViS to four different tasks, namely Video Instance Segmentation (VIS), Video Panoptic Segmentation (VPS), Video Object Segmentation (VOS) and Point Exemplar-guided Tracking (PET). Our unified, jointly trained model achieves state-of-the-art performance on 5/7 benchmarks spanning these four tasks, and competitive performance on the remaining two.
BURST: A Benchmark for Unifying Object Recognition, Segmentation and Tracking in Video
Sep 25, 2022
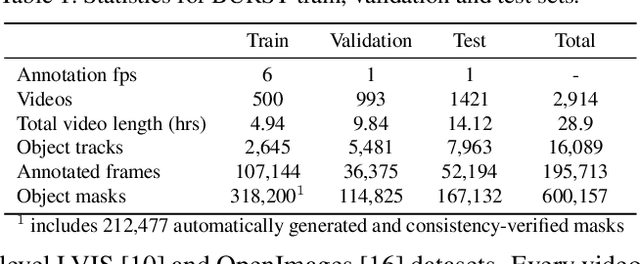
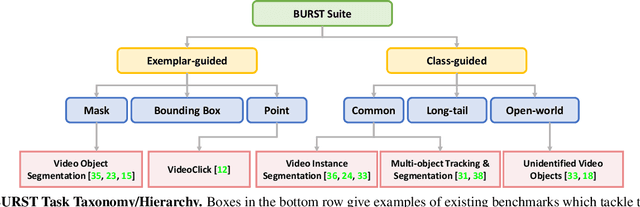
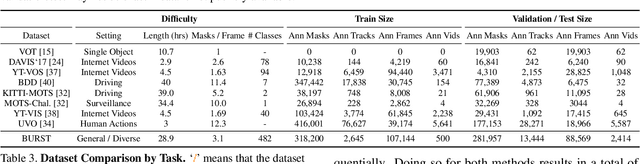
Multiple existing benchmarks involve tracking and segmenting objects in video e.g., Video Object Segmentation (VOS) and Multi-Object Tracking and Segmentation (MOTS), but there is little interaction between them due to the use of disparate benchmark datasets and metrics (e.g. J&F, mAP, sMOTSA). As a result, published works usually target a particular benchmark, and are not easily comparable to each another. We believe that the development of generalized methods that can tackle multiple tasks requires greater cohesion among these research sub-communities. In this paper, we aim to facilitate this by proposing BURST, a dataset which contains thousands of diverse videos with high-quality object masks, and an associated benchmark with six tasks involving object tracking and segmentation in video. All tasks are evaluated using the same data and comparable metrics, which enables researchers to consider them in unison, and hence, more effectively pool knowledge from different methods across different tasks. Additionally, we demonstrate several baselines for all tasks and show that approaches for one task can be applied to another with a quantifiable and explainable performance difference. Dataset annotations and evaluation code is available at: https://github.com/Ali2500/BURST-benchmark.
Differentiable Soft-Masked Attention
Jun 01, 2022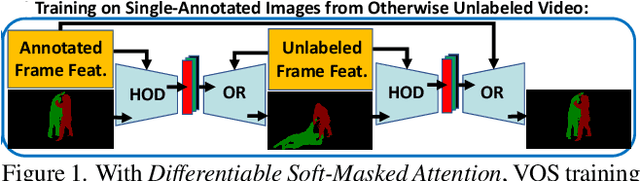
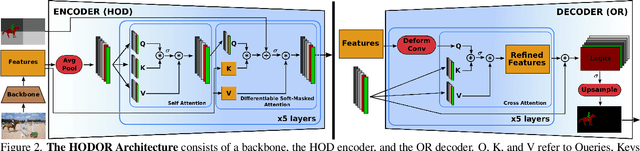

Transformers have become prevalent in computer vision due to their performance and flexibility in modelling complex operations. Of particular significance is the 'cross-attention' operation, which allows a vector representation (e.g. of an object in an image) to be learned by attending to an arbitrarily sized set of input features. Recently, "Masked Attention" was proposed in which a given object representation only attends to those image pixel features for which the segmentation mask of that object is active. This specialization of attention proved beneficial for various image and video segmentation tasks. In this paper, we propose another specialization of attention which enables attending over `soft-masks' (those with continuous mask probabilities instead of binary values), and is also differentiable through these mask probabilities, thus allowing the mask used for attention to be learned within the network without requiring direct loss supervision. This can be useful for several applications. Specifically, we employ our "Differentiable Soft-Masked Attention" for the task of Weakly-Supervised Video Object Segmentation (VOS), where we develop a transformer-based network for VOS which only requires a single annotated image frame for training, but can also benefit from cycle consistency training on a video with just one annotated frame. Although there is no loss for masks in unlabeled frames, the network is still able to segment objects in those frames due to our novel attention formulation.
Forecasting from LiDAR via Future Object Detection
Mar 31, 2022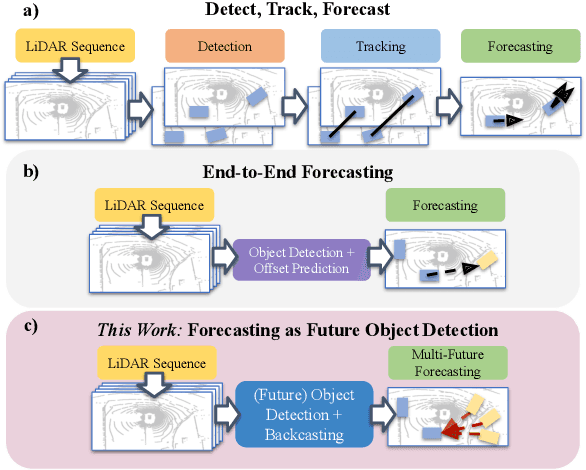

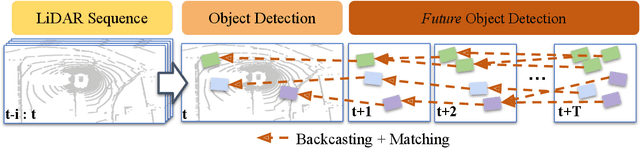
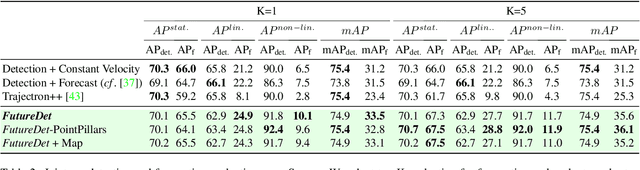
Object detection and forecasting are fundamental components of embodied perception. These two problems, however, are largely studied in isolation by the community. In this paper, we propose an end-to-end approach for detection and motion forecasting based on raw sensor measurement as opposed to ground truth tracks. Instead of predicting the current frame locations and forecasting forward in time, we directly predict future object locations and backcast to determine where each trajectory began. Our approach not only improves overall accuracy compared to other modular or end-to-end baselines, it also prompts us to rethink the role of explicit tracking for embodied perception. Additionally, by linking future and current locations in a many-to-one manner, our approach is able to reason about multiple futures, a capability that was previously considered difficult for end-to-end approaches. We conduct extensive experiments on the popular nuScenes dataset and demonstrate the empirical effectiveness of our approach. In addition, we investigate the appropriateness of reusing standard forecasting metrics for an end-to-end setup, and find a number of limitations which allow us to build simple baselines to game these metrics. We address this issue with a novel set of joint forecasting and detection metrics that extend the commonly used AP metrics from the detection community to measuring forecasting accuracy. Our code is available at https://github.com/neeharperi/FutureDet
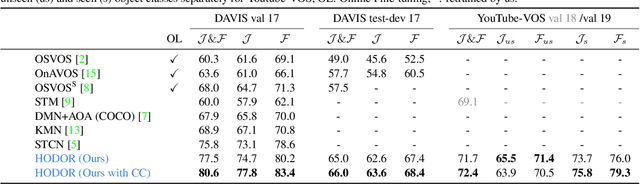
HODOR: High-level Object Descriptors for Object Re-segmentation in Video Learned from Static Images
Dec 16, 2021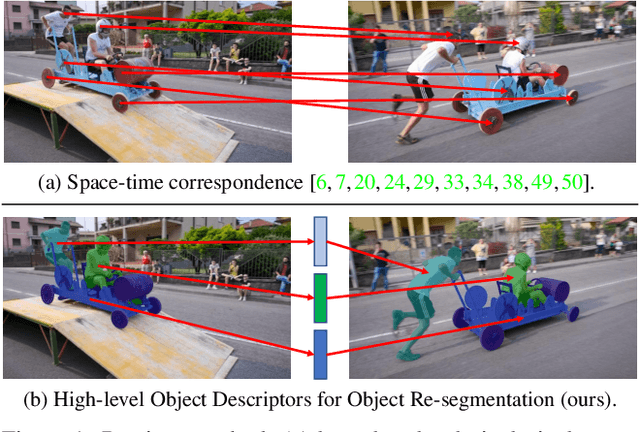
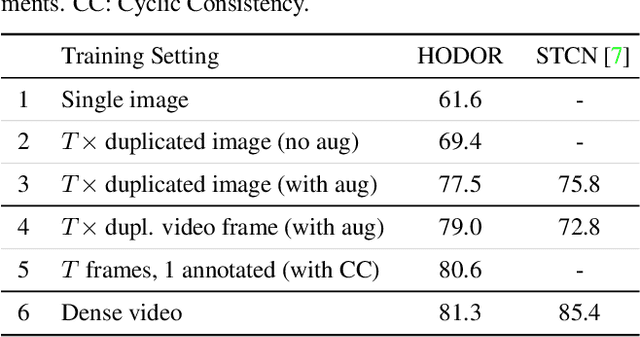

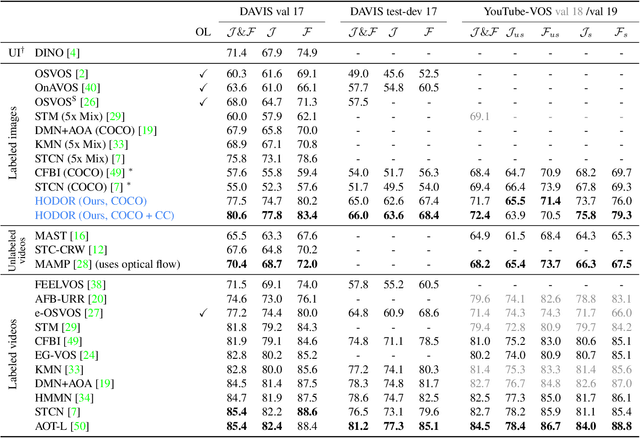
Existing state-of-the-art methods for Video Object Segmentation (VOS) learn low-level pixel-to-pixel correspondences between frames to propagate object masks across video. This requires a large amount of densely annotated video data, which is costly to annotate, and largely redundant since frames within a video are highly correlated. In light of this, we propose HODOR: a novel method that tackles VOS by effectively leveraging annotated static images for understanding object appearance and scene context. We encode object instances and scene information from an image frame into robust high-level descriptors which can then be used to re-segment those objects in different frames. As a result, HODOR achieves state-of-the-art performance on the DAVIS and YouTube-VOS benchmarks compared to existing methods trained without video annotations. Without any architectural modification, HODOR can also learn from video context around single annotated video frames by utilizing cyclic consistency, whereas other methods rely on dense, temporally consistent annotations.
Opening up Open-World Tracking
Apr 22, 2021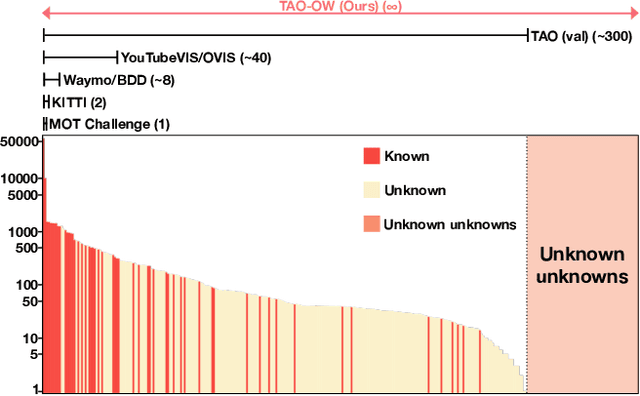


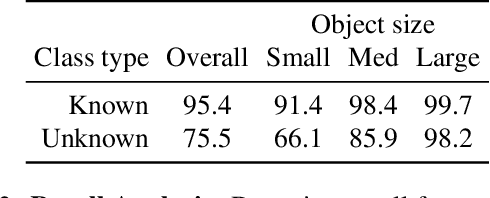
In this paper, we propose and study Open-World Tracking (OWT). Open-world tracking goes beyond current multi-object tracking benchmarks and methods which focus on tracking object classes that belong to a predefined closed-set of frequently observed object classes. In OWT, we relax this assumption: we may encounter objects at inference time that were not labeled for training. The main contribution of this paper is the formalization of the OWT task, along with an evaluation protocol and metric (Open-World Tracking Accuracy, OWTA), which decomposes into two intuitive terms, one for measuring recall, and another for measuring track association accuracy. This allows us to perform a rigorous evaluation of several different baselines that follow design patterns proposed in the multi-object tracking community. Further we show that our Open-World Tracking Baseline, while performing well in the OWT setting, also achieves near state-of-the-art results on traditional closed-world benchmarks, without any adjustments or tuning. We believe that this paper is an initial step towards studying multi-object tracking in the open world, a task of crucial importance for future intelligent agents that will need to understand, react to, and learn from, an infinite variety of objects that can appear in an open world.