 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGG-T$^3$: Offline Feed-Forward 3D Reconstruction at Scale
Feb 26, 2026We present a scalable 3D reconstruction model that addresses a critical limitation in offline feed-forward methods: their computational and memory requirements grow quadratically w.r.t. the number of input images. Our approach is built on the key insight that this bottleneck stems from the varying-length Key-Value (KV) space representation of scene geometry, which we distill into a fixed-size Multi-Layer Perceptron (MLP) via test-time training. VGG-T$^3$ (Visual Geometry Grounded Test Time Training) scales linearly w.r.t. the number of input views, similar to online models, and reconstructs a $1k$ image collection in just $54$ seconds, achieving a $11.6\times$ speed-up over baselines that rely on softmax attention. Since our method retains global scene aggregation capability, our point map reconstruction error outperforming other linear-time methods by large margins. Finally, we demonstrate visual localization capabilities of our model by querying the scene representation with unseen images.
Lidar Panoptic Segmentation in an Open World
Sep 22, 2024Addressing Lidar Panoptic Segmentation (LPS ) is crucial for safe deployment of autonomous vehicles. LPS aims to recognize and segment lidar points w.r.t. a pre-defined vocabulary of semantic classes, including thing classes of countable objects (e.g., pedestrians and vehicles) and stuff classes of amorphous regions (e.g., vegetation and road). Importantly, LPS requires segmenting individual thing instances (e.g., every single vehicle). Current LPS methods make an unrealistic assumption that the semantic class vocabulary is fixed in the real open world, but in fact, class ontologies usually evolve over time as robots encounter instances of novel classes that are considered to be unknowns w.r.t. the pre-defined class vocabulary. To address this unrealistic assumption, we study LPS in the Open World (LiPSOW): we train models on a dataset with a pre-defined semantic class vocabulary and study their generalization to a larger dataset where novel instances of thing and stuff classes can appear. This experimental setting leads to interesting conclusions. While prior art train class-specific instance segmentation methods and obtain state-of-the-art results on known classes, methods based on class-agnostic bottom-up grouping perform favorably on classes outside of the initial class vocabulary (i.e., unknown classes). Unfortunately, these methods do not perform on-par with fully data-driven methods on known classes. Our work suggests a middle ground: we perform class-agnostic point clustering and over-segment the input cloud in a hierarchical fashion, followed by binary point segment classification, akin to Region Proposal Network [1]. We obtain the final point cloud segmentation by computing a cut in the weighted hierarchical tree of point segments, independently of semantic classification. Remarkably, this unified approach leads to strong performance on both known and unknown classes.
Text2Pos: Text-to-Point-Cloud Cross-Modal Localization
Apr 05, 2022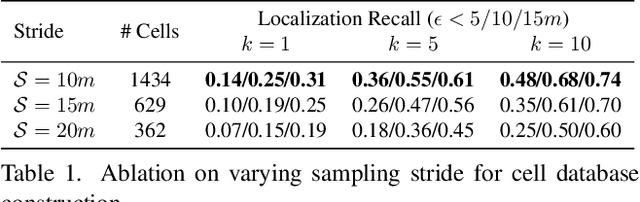
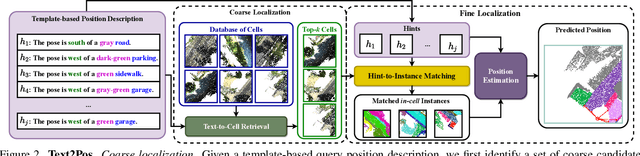
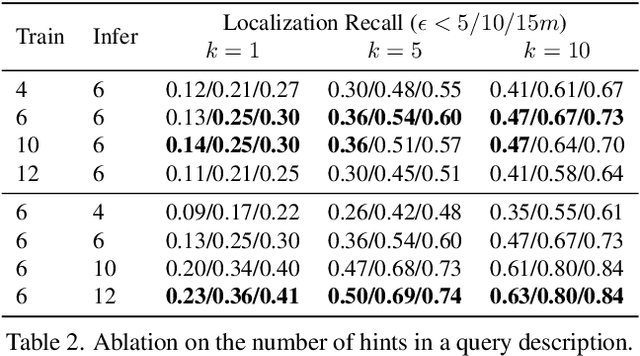
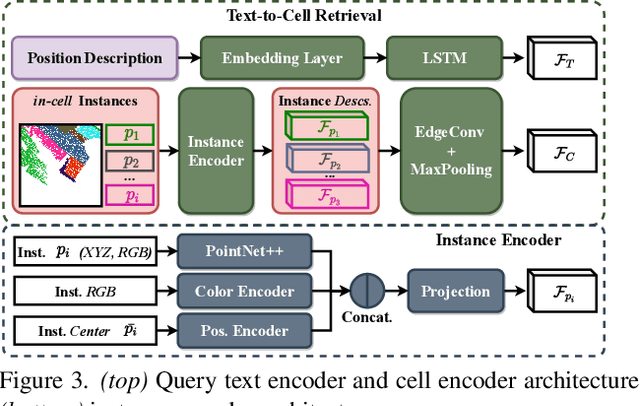
Natural language-based communication with mobile devices and home appliances is becoming increasingly popular and has the potential to become natural for communicating with mobile robots in the future. Towards this goal, we investigate cross-modal text-to-point-cloud localization that will allow us to specify, for example, a vehicle pick-up or goods delivery location. In particular, we propose Text2Pos, a cross-modal localization module that learns to align textual descriptions with localization cues in a coarse- to-fine manner. Given a point cloud of the environment, Text2Pos locates a position that is specified via a natural language-based description of the immediate surroundings. To train Text2Pos and study its performance, we construct KITTI360Pose, the first dataset for this task based on the recently introduced KITTI360 dataset. Our experiments show that we can localize 65% of textual queries within 15m distance to query locations for top-10 retrieved locations. This is a starting point that we hope will spark future developments towards language-based navigation.
Is Geometry Enough for Matching in Visual Localization?
Mar 24, 2022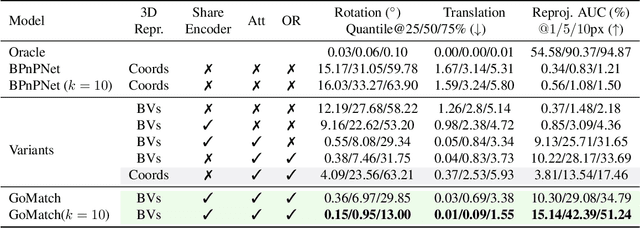
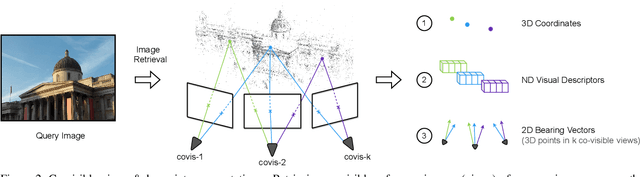
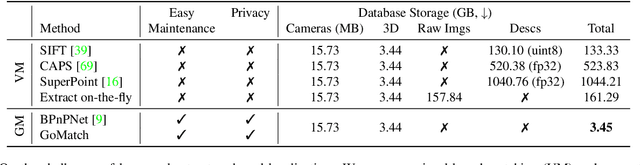
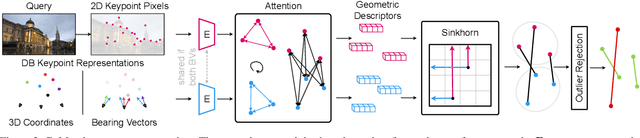
In this paper, we propose to go beyond the well-established approach to vision-based localization that relies on visual descriptor matching between a query image and a 3D point cloud. While matching keypoints via visual descriptors makes localization highly accurate, it has significant storage demands, raises privacy concerns and increases map maintenance complexity. To elegantly address those practical challenges for large-scale localization, we present GoMatch, an alternative to visual-based matching that solely relies on geometric information for matching image keypoints to maps, represented as sets of bearing vectors. Our novel bearing vectors representation of 3D points, significantly relieves the cross-domain challenge in geometric-based matching that prevented prior work to tackle localization in a realistic environment. With additional careful architecture design, GoMatch improves over prior geometric-based matching work with a reduction of ($10.67m, 95.7^{\circ}$) and ($1.43m$, $34.7^{\circ}$) in average median pose errors on Cambridge Landmarks and 7-Scenes, while requiring as little as $1.5/1.7\%$ of storage capacity in comparison to the best visual-based matching methods. This confirms its potential and feasibility for real-world localization and opens the door to future efforts in advancing city-scale visual localization methods that do not require storing visual descriptors.
MOTSynth: How Can Synthetic Data Help Pedestrian Detection and Tracking?
Aug 21, 2021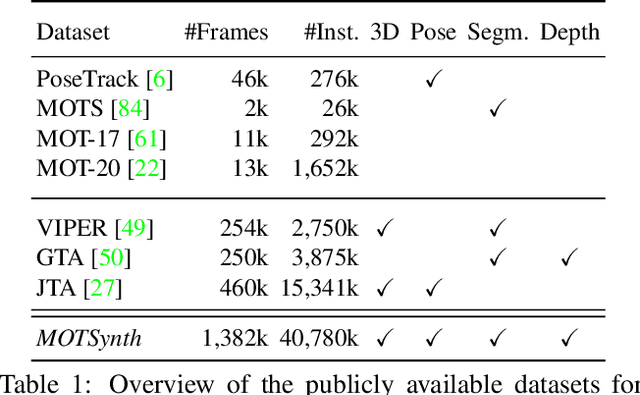

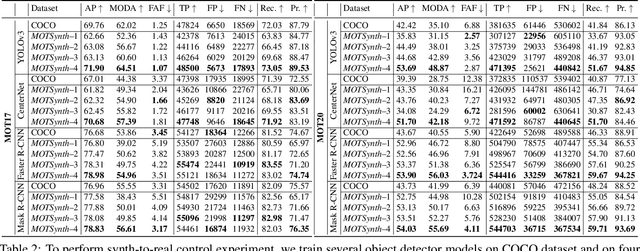
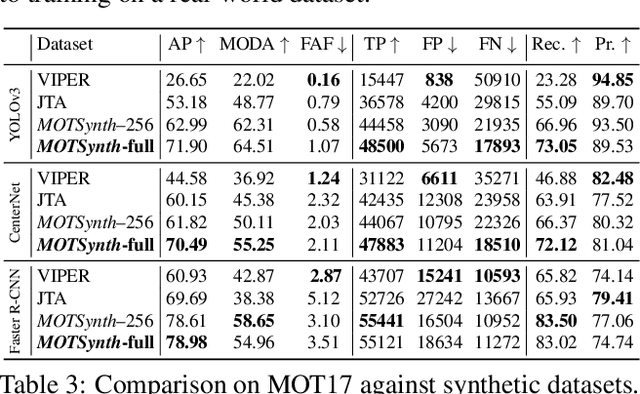
Deep learning-based methods for video pedestrian detection and tracking require large volumes of training data to achieve good performance. However, data acquisition in crowded public environments raises data privacy concerns -- we are not allowed to simply record and store data without the explicit consent of all participants. Furthermore, the annotation of such data for computer vision applications usually requires a substantial amount of manual effort, especially in the video domain. Labeling instances of pedestrians in highly crowded scenarios can be challenging even for human annotators and may introduce errors in the training data. In this paper, we study how we can advance different aspects of multi-person tracking using solely synthetic data. To this end, we generate MOTSynth, a large, highly diverse synthetic dataset for object detection and tracking using a rendering game engine. Our experiments show that MOTSynth can be used as a replacement for real data on tasks such as pedestrian detection, re-identification, segmentation, and tracking.
STEP: Segmenting and Tracking Every Pixel
Feb 23, 2021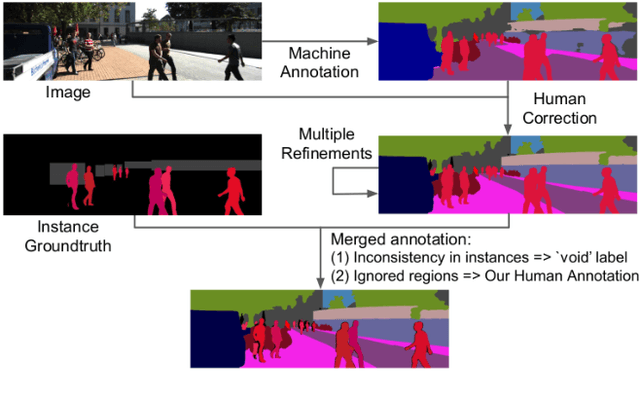
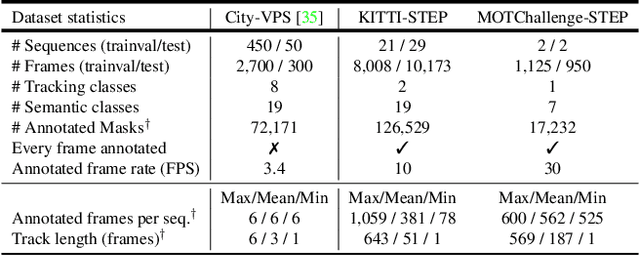


In this paper, we tackle video panoptic segmentation, a task that requires assigning semantic classes and track identities to all pixels in a video. To study this important problem in a setting that requires a continuous interpretation of sensory data, we present a new benchmark: Segmenting and Tracking Every Pixel (STEP), encompassing two datasets, KITTI-STEP, and MOTChallenge-STEP together with a new evaluation metric. Our work is the first that targets this task in a real-world setting that requires dense interpretation in both spatial and temporal domains. As the ground-truth for this task is difficult and expensive to obtain, existing datasets are either constructed synthetically or only sparsely annotated within short video clips. By contrast, our datasets contain long video sequences, providing challenging examples and a test-bed for studying long-term pixel-precise segmentation and tracking. For measuring the performance, we propose a novel evaluation metric Segmentation and Tracking Quality (STQ) that fairly balances semantic and tracking aspects of this task and is suitable for evaluating sequences of arbitrary length. We will make our datasets, metric, and baselines publicly available.
HOTA: A Higher Order Metric for Evaluating Multi-Object Tracking
Sep 29, 2020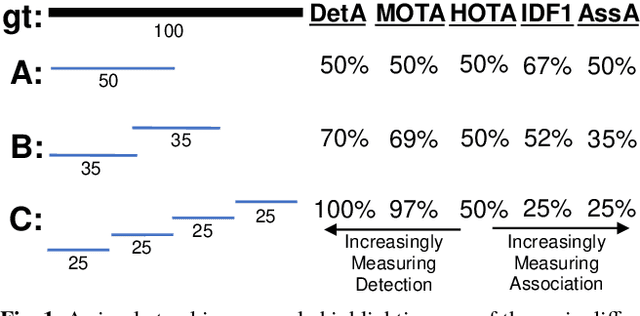
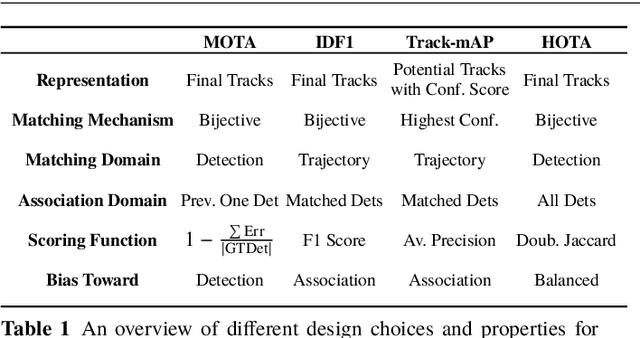
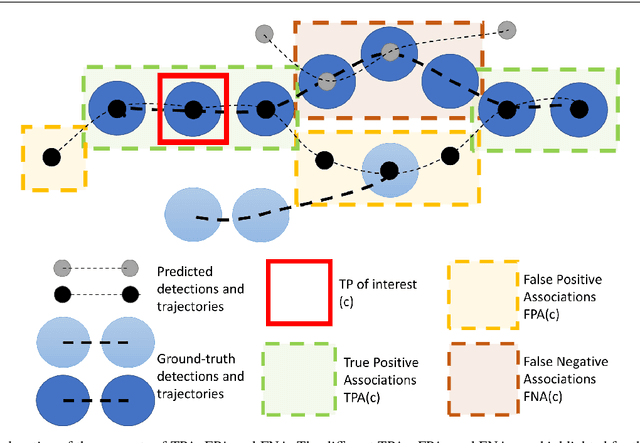
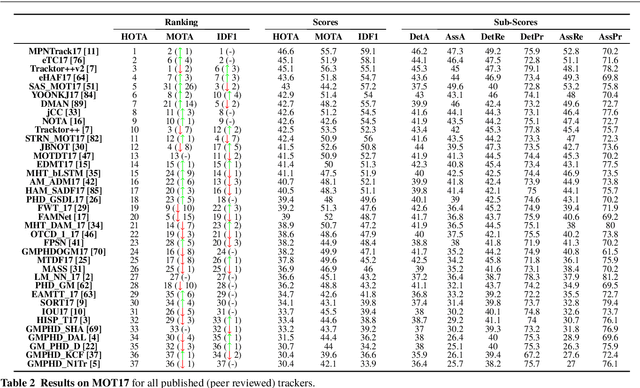
Multi-Object Tracking (MOT) has been notoriously difficult to evaluate. Previous metrics overemphasize the importance of either detection or association. To address this, we present a novel MOT evaluation metric, HOTA (Higher Order Tracking Accuracy), which explicitly balances the effect of performing accurate detection, association and localization into a single unified metric for comparing trackers. HOTA decomposes into a family of sub-metrics which are able to evaluate each of five basic error types separately, which enables clear analysis of tracking performance. We evaluate the effectiveness of HOTA on the MOTChallenge benchmark, and show that it is able to capture important aspects of MOT performance not previously taken into account by established metrics. Furthermore, we show HOTA scores better align with human visual evaluation of tracking performance.
AlignNet-3D: Fast Point Cloud Registration of Partially Observed Objects
Oct 10, 2019
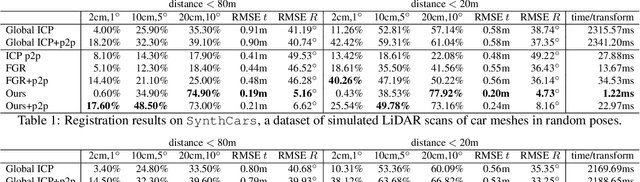
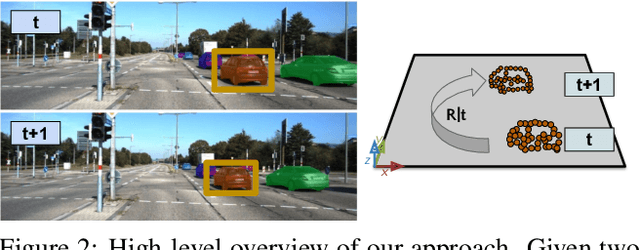
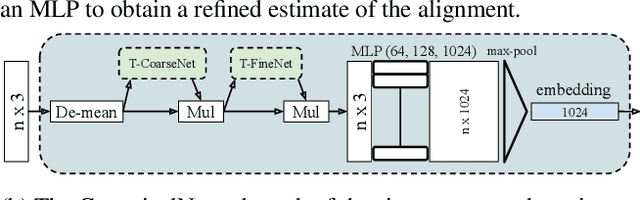
Methods tackling multi-object tracking need to estimate the number of targets in the sensing area as well as to estimate their continuous state. While the majority of existing methods focus on data association, precise state (3D pose) estimation is often only coarsely estimated by approximating targets with centroids or (3D) bounding boxes. However, in automotive scenarios, motion perception of surrounding agents is critical and inaccuracies in the vehicle close-range can have catastrophic consequences. In this work, we focus on precise 3D track state estimation and propose a learning-based approach for object-centric relative motion estimation of partially observed objects. Instead of approximating targets with their centroids, our approach is capable of utilizing noisy 3D point segments of objects to estimate their motion. To that end, we propose a simple, yet effective and efficient network, \method, that learns to align point clouds. Our evaluation on two different datasets demonstrates that our method outperforms computationally expensive, global 3D registration methods while being significantly more efficient. We make our data, code, and models available at https://www.vision.rwth-aachen.de/page/alignnet.
MOTS: Multi-Object Tracking and Segmentation
Apr 08, 2019
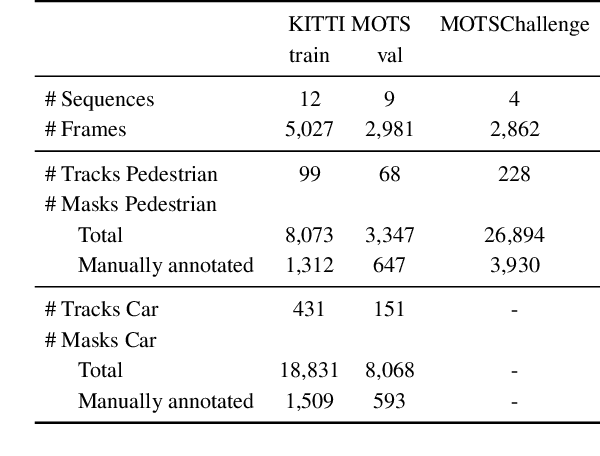

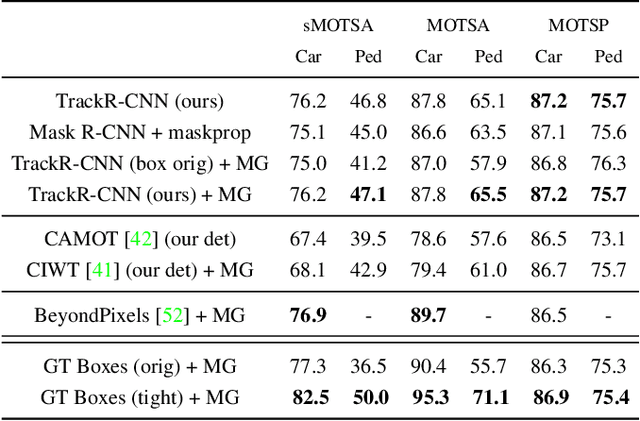
This paper extends the popular task of multi-object tracking to multi-object tracking and segmentation (MOTS). Towards this goal, we create dense pixel-level annotations for two existing tracking datasets using a semi-automatic annotation procedure. Our new annotations comprise 65,213 pixel masks for 977 distinct objects (cars and pedestrians) in 10,870 video frames. For evaluation, we extend existing multi-object tracking metrics to this new task. Moreover, we propose a new baseline method which jointly addresses detection, tracking, and segmentation with a single convolutional network. We demonstrate the value of our datasets by achieving improvements in performance when training on MOTS annotations. We believe that our datasets, metrics and baseline will become a valuable resource towards developing multi-object tracking approaches that go beyond 2D bounding boxes. We make our annotations, code, and models available at https://www.vision.rwth-aachen.de/page/mots.
* CVPR 2019 camera-ready version
Large-Scale Object Mining for Object Discovery from Unlabeled Video
Feb 28, 2019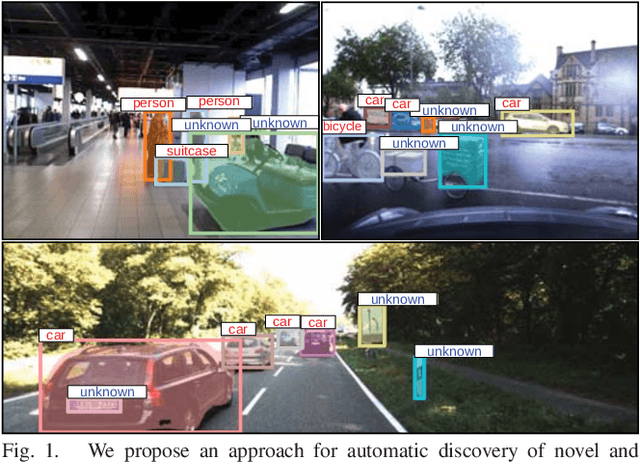
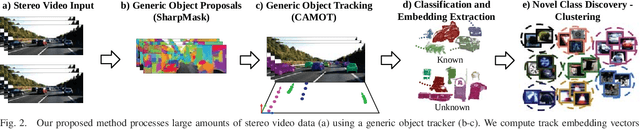
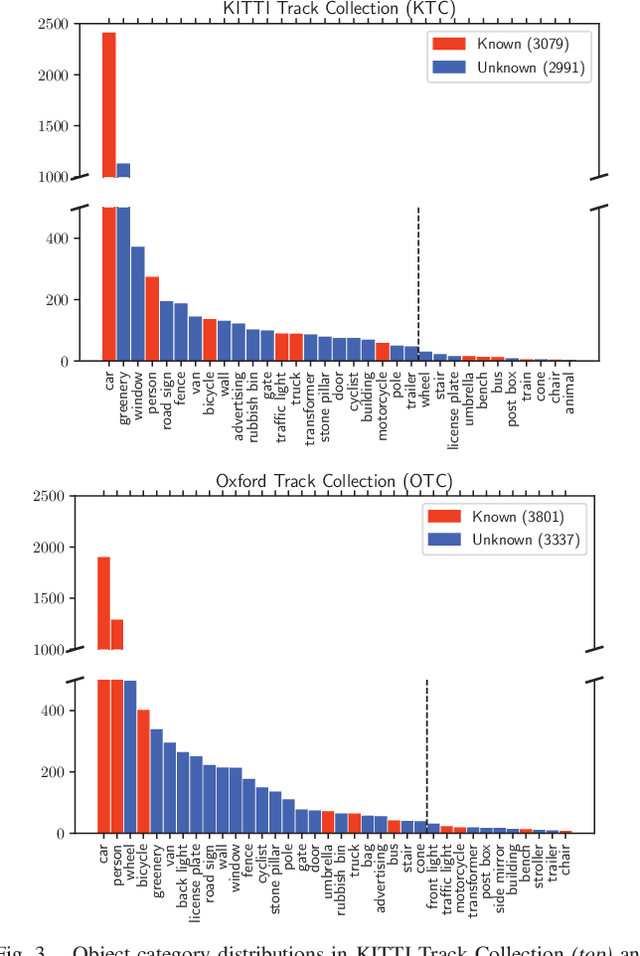
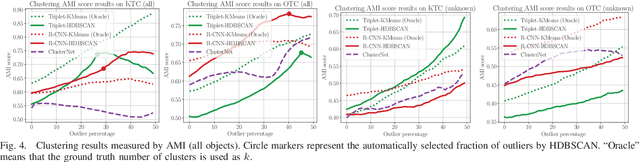
This paper addresses the problem of object discovery from unlabeled driving videos captured in a realistic automotive setting. Identifying recurring object categories in such raw video streams is a very challenging problem. Not only do object candidates first have to be localized in the input images, but many interesting object categories occur relatively infrequently. Object discovery will therefore have to deal with the difficulties of operating in the long tail of the object distribution. We demonstrate the feasibility of performing fully automatic object discovery in such a setting by mining object tracks using a generic object tracker. In order to facilitate further research in object discovery, we release a collection of more than 360,000 automatically mined object tracks from 10+ hours of video data (560,000 frames). We use this dataset to evaluate the suitability of different feature representations and clustering strategies for object discovery.