 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Geometry Enough for Matching in Visual Localization?
Mar 24, 2022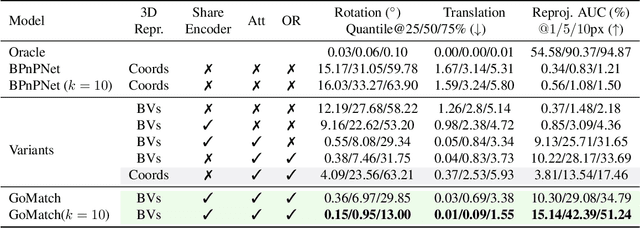
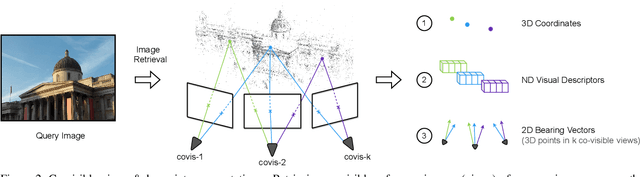
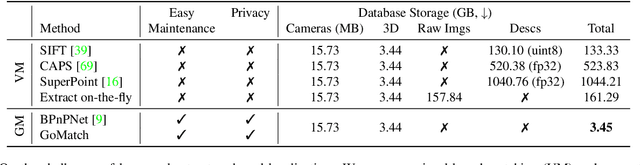
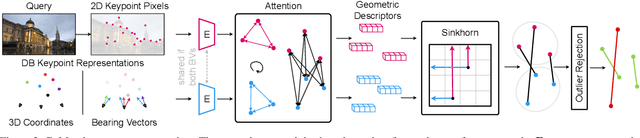
In this paper, we propose to go beyond the well-established approach to vision-based localization that relies on visual descriptor matching between a query image and a 3D point cloud. While matching keypoints via visual descriptors makes localization highly accurate, it has significant storage demands, raises privacy concerns and increases map maintenance complexity. To elegantly address those practical challenges for large-scale localization, we present GoMatch, an alternative to visual-based matching that solely relies on geometric information for matching image keypoints to maps, represented as sets of bearing vectors. Our novel bearing vectors representation of 3D points, significantly relieves the cross-domain challenge in geometric-based matching that prevented prior work to tackle localization in a realistic environment. With additional careful architecture design, GoMatch improves over prior geometric-based matching work with a reduction of ($10.67m, 95.7^{\circ}$) and ($1.43m$, $34.7^{\circ}$) in average median pose errors on Cambridge Landmarks and 7-Scenes, while requiring as little as $1.5/1.7\%$ of storage capacity in comparison to the best visual-based matching methods. This confirms its potential and feasibility for real-world localization and opens the door to future efforts in advancing city-scale visual localization methods that do not require storing visual descriptors.