 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models
Jun 11, 2025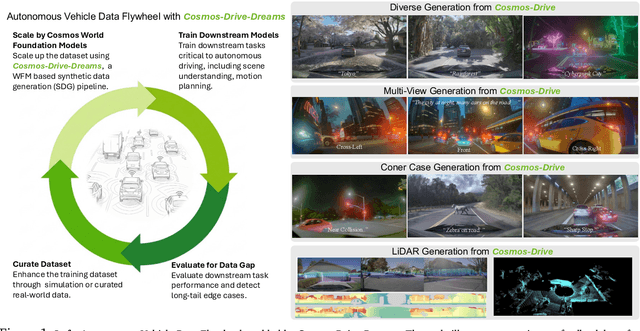
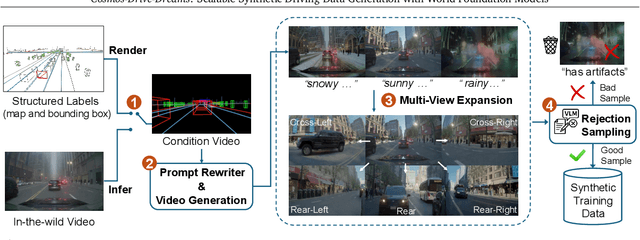
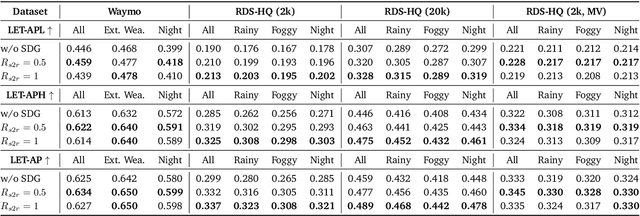
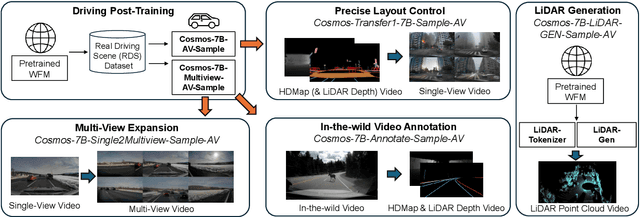
Collecting and annotating real-world data for safety-critical physical AI systems, such as Autonomous Vehicle (AV), is time-consuming and costly. It is especially challenging to capture rare edge cases, which play a critical role in training and testing of an AV system. To address this challenge, we introduce the Cosmos-Drive-Dreams - a synthetic data generation (SDG) pipeline that aims to generate challenging scenarios to facilitate downstream tasks such as perception and driving policy training. Powering this pipeline is Cosmos-Drive, a suite of models specialized from NVIDIA Cosmos world foundation model for the driving domain and are capable of controllable, high-fidelity, multi-view, and spatiotemporally consistent driving video generation. We showcase the utility of these models by applying Cosmos-Drive-Dreams to scale the quantity and diversity of driving datasets with high-fidelity and challenging scenarios. Experimentally, we demonstrate that our generated data helps in mitigating long-tail distribution problems and enhances generalization in downstream tasks such as 3D lane detection, 3D object detection and driving policy learning. We open source our pipeline toolkit, dataset and model weights through the NVIDIA's Cosmos platform. Project page: https://research.nvidia.com/labs/toronto-ai/cosmos_drive_dreams
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
Lidar Panoptic Segmentation in an Open World
Sep 22, 2024Addressing Lidar Panoptic Segmentation (LPS ) is crucial for safe deployment of autonomous vehicles. LPS aims to recognize and segment lidar points w.r.t. a pre-defined vocabulary of semantic classes, including thing classes of countable objects (e.g., pedestrians and vehicles) and stuff classes of amorphous regions (e.g., vegetation and road). Importantly, LPS requires segmenting individual thing instances (e.g., every single vehicle). Current LPS methods make an unrealistic assumption that the semantic class vocabulary is fixed in the real open world, but in fact, class ontologies usually evolve over time as robots encounter instances of novel classes that are considered to be unknowns w.r.t. the pre-defined class vocabulary. To address this unrealistic assumption, we study LPS in the Open World (LiPSOW): we train models on a dataset with a pre-defined semantic class vocabulary and study their generalization to a larger dataset where novel instances of thing and stuff classes can appear. This experimental setting leads to interesting conclusions. While prior art train class-specific instance segmentation methods and obtain state-of-the-art results on known classes, methods based on class-agnostic bottom-up grouping perform favorably on classes outside of the initial class vocabulary (i.e., unknown classes). Unfortunately, these methods do not perform on-par with fully data-driven methods on known classes. Our work suggests a middle ground: we perform class-agnostic point clustering and over-segment the input cloud in a hierarchical fashion, followed by binary point segment classification, akin to Region Proposal Network [1]. We obtain the final point cloud segmentation by computing a cut in the weighted hierarchical tree of point segments, independently of semantic classification. Remarkably, this unified approach leads to strong performance on both known and unknown classes.
NOVIS: A Case for End-to-End Near-Online Video Instance Segmentation
Aug 29, 2023



Until recently, the Video Instance Segmentation (VIS) community operated under the common belief that offline methods are generally superior to a frame by frame online processing. However, the recent success of online methods questions this belief, in particular, for challenging and long video sequences. We understand this work as a rebuttal of those recent observations and an appeal to the community to focus on dedicated near-online VIS approaches. To support our argument, we present a detailed analysis on different processing paradigms and the new end-to-end trainable NOVIS (Near-Online Video Instance Segmentation) method. Our transformer-based model directly predicts spatio-temporal mask volumes for clips of frames and performs instance tracking between clips via overlap embeddings. NOVIS represents the first near-online VIS approach which avoids any handcrafted tracking heuristics. We outperform all existing VIS methods by large margins and provide new state-of-the-art results on both YouTube-VIS (2019/2021) and the OVIS benchmarks.
Multi-Object Tracking and Segmentation via Neural Message Passing
Jul 15, 2022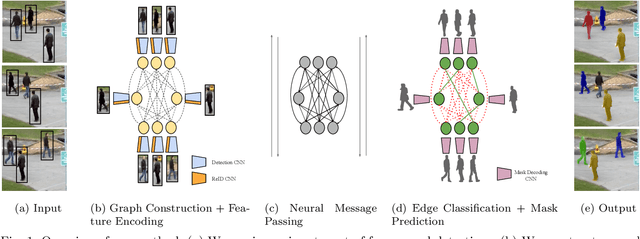
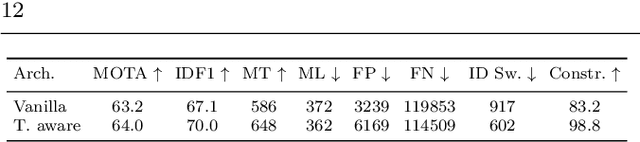
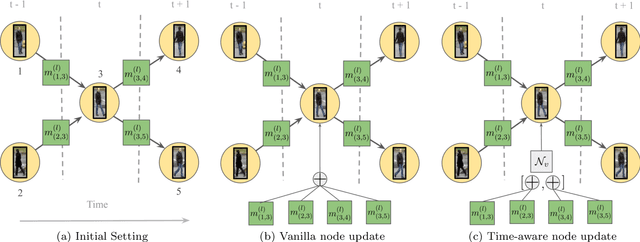
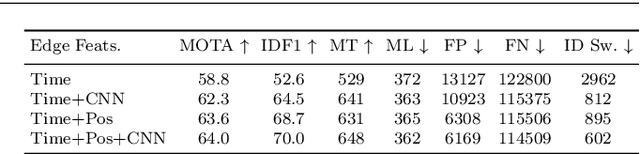
Graphs offer a natural way to formulate Multiple Object Tracking (MOT) and Multiple Object Tracking and Segmentation (MOTS) within the tracking-by-detection paradigm. However, they also introduce a major challenge for learning methods, as defining a model that can operate on such structured domain is not trivial. In this work, we exploit the classical network flow formulation of MOT to define a fully differentiable framework based on Message Passing Networks (MPNs). By operating directly on the graph domain, our method can reason globally over an entire set of detections and exploit contextual features. It then jointly predicts both final solutions for the data association problem and segmentation masks for all objects in the scene while exploiting synergies between the two tasks. We achieve state-of-the-art results for both tracking and segmentation in several publicly available datasets. Our code is available at github.com/ocetintas/MPNTrackSeg.
Text2Pos: Text-to-Point-Cloud Cross-Modal Localization
Apr 05, 2022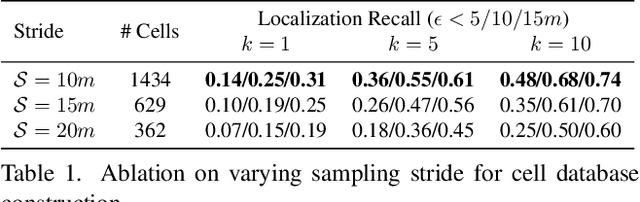
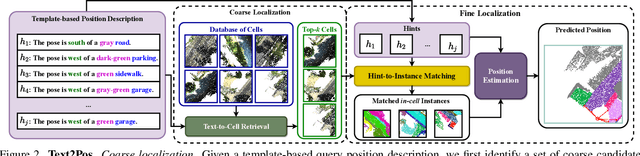
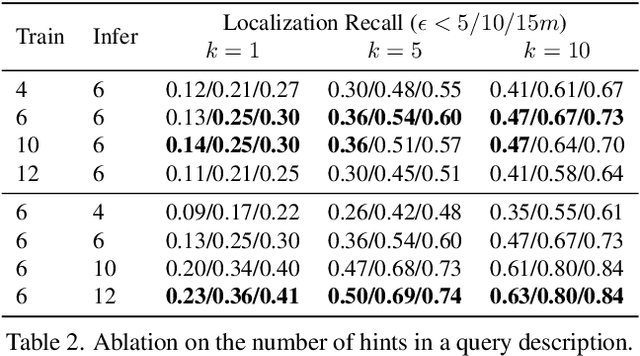
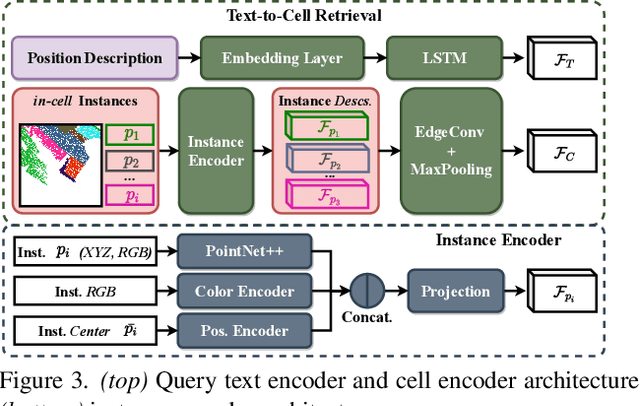
Natural language-based communication with mobile devices and home appliances is becoming increasingly popular and has the potential to become natural for communicating with mobile robots in the future. Towards this goal, we investigate cross-modal text-to-point-cloud localization that will allow us to specify, for example, a vehicle pick-up or goods delivery location. In particular, we propose Text2Pos, a cross-modal localization module that learns to align textual descriptions with localization cues in a coarse- to-fine manner. Given a point cloud of the environment, Text2Pos locates a position that is specified via a natural language-based description of the immediate surroundings. To train Text2Pos and study its performance, we construct KITTI360Pose, the first dataset for this task based on the recently introduced KITTI360 dataset. Our experiments show that we can localize 65% of textual queries within 15m distance to query locations for top-10 retrieved locations. This is a starting point that we hope will spark future developments towards language-based navigation.
The Group Loss++: A deeper look into group loss for deep metric learning
Apr 04, 2022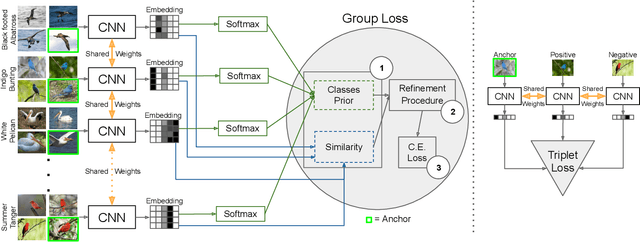
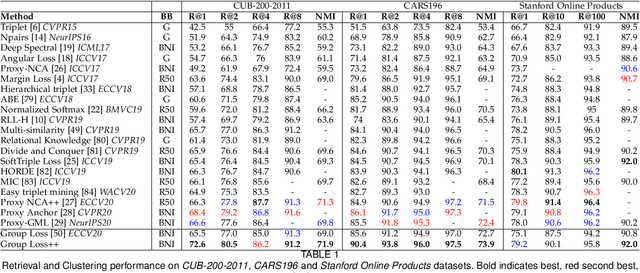
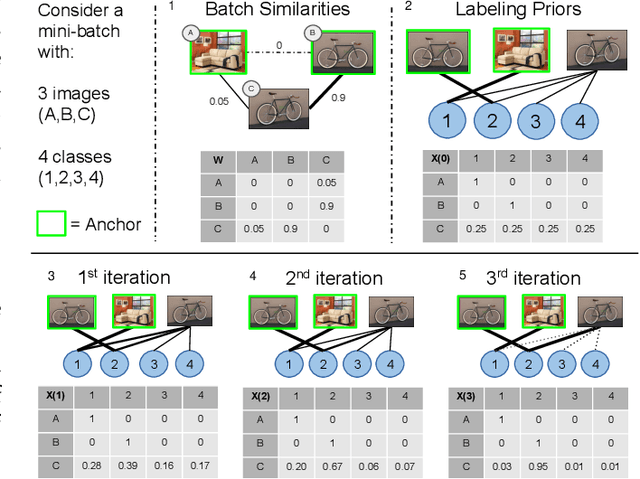
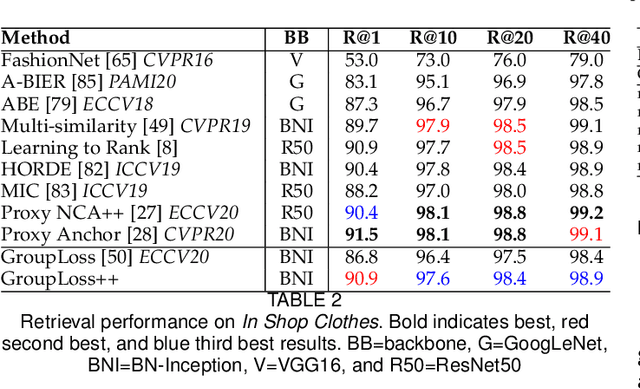
Deep metric learning has yielded impressive results in tasks such as clustering and image retrieval by leveraging neural networks to obtain highly discriminative feature embeddings, which can be used to group samples into different classes. Much research has been devoted to the design of smart loss functions or data mining strategies for training such networks. Most methods consider only pairs or triplets of samples within a mini-batch to compute the loss function, which is commonly based on the distance between embeddings. We propose Group Loss, a loss function based on a differentiable label-propagation method that enforces embedding similarity across all samples of a group while promoting, at the same time, low-density regions amongst data points belonging to different groups. Guided by the smoothness assumption that "similar objects should belong to the same group", the proposed loss trains the neural network for a classification task, enforcing a consistent labelling amongst samples within a class. We design a set of inference strategies tailored towards our algorithm, named Group Loss++ that further improve the results of our model. We show state-of-the-art results on clustering and image retrieval on four retrieval datasets, and present competitive results on two person re-identification datasets, providing a unified framework for retrieval and re-identification.
Is Geometry Enough for Matching in Visual Localization?
Mar 24, 2022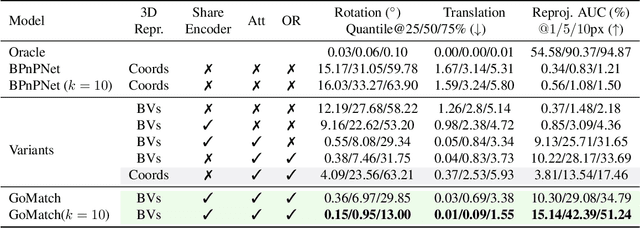
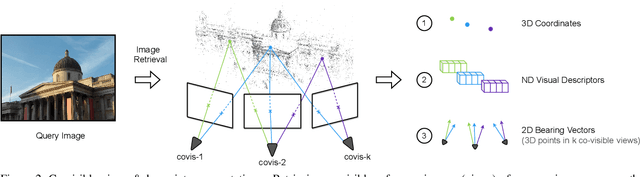
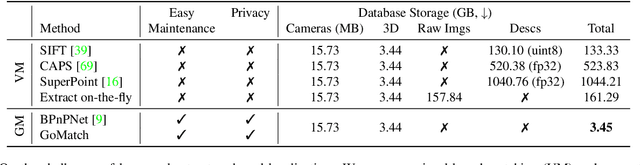
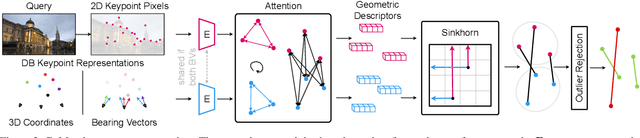
In this paper, we propose to go beyond the well-established approach to vision-based localization that relies on visual descriptor matching between a query image and a 3D point cloud. While matching keypoints via visual descriptors makes localization highly accurate, it has significant storage demands, raises privacy concerns and increases map maintenance complexity. To elegantly address those practical challenges for large-scale localization, we present GoMatch, an alternative to visual-based matching that solely relies on geometric information for matching image keypoints to maps, represented as sets of bearing vectors. Our novel bearing vectors representation of 3D points, significantly relieves the cross-domain challenge in geometric-based matching that prevented prior work to tackle localization in a realistic environment. With additional careful architecture design, GoMatch improves over prior geometric-based matching work with a reduction of ($10.67m, 95.7^{\circ}$) and ($1.43m$, $34.7^{\circ}$) in average median pose errors on Cambridge Landmarks and 7-Scenes, while requiring as little as $1.5/1.7\%$ of storage capacity in comparison to the best visual-based matching methods. This confirms its potential and feasibility for real-world localization and opens the door to future efforts in advancing city-scale visual localization methods that do not require storing visual descriptors.
MOTSynth: How Can Synthetic Data Help Pedestrian Detection and Tracking?
Aug 21, 2021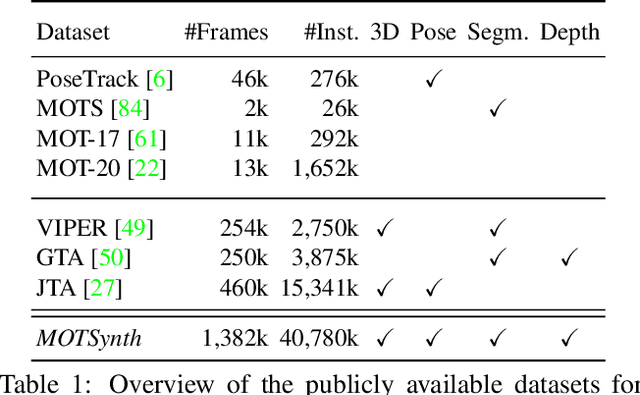

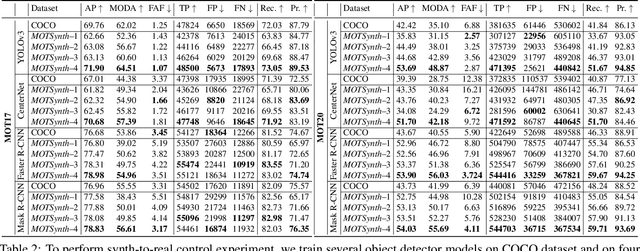
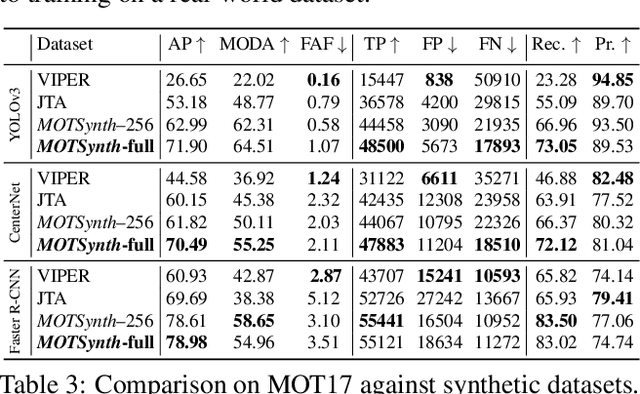
Deep learning-based methods for video pedestrian detection and tracking require large volumes of training data to achieve good performance. However, data acquisition in crowded public environments raises data privacy concerns -- we are not allowed to simply record and store data without the explicit consent of all participants. Furthermore, the annotation of such data for computer vision applications usually requires a substantial amount of manual effort, especially in the video domain. Labeling instances of pedestrians in highly crowded scenarios can be challenging even for human annotators and may introduce errors in the training data. In this paper, we study how we can advance different aspects of multi-person tracking using solely synthetic data. To this end, we generate MOTSynth, a large, highly diverse synthetic dataset for object detection and tracking using a rendering game engine. Our experiments show that MOTSynth can be used as a replacement for real data on tasks such as pedestrian detection, re-identification, segmentation, and tracking.
Towards Reducing Labeling Cost in Deep Object Detection
Jun 22, 2021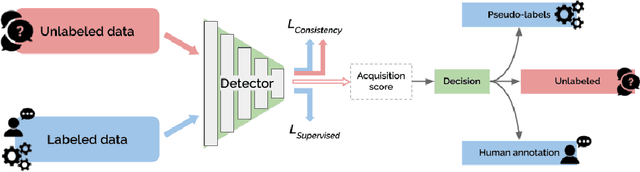

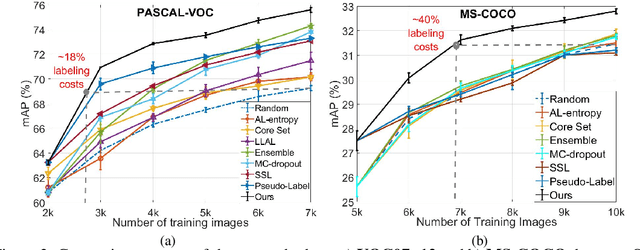

Deep neural networks have reached very high accuracy on object detection but their success hinges on large amounts of labeled data. To reduce the dependency on labels, various active-learning strategies have been proposed, typically based on the confidence of the detector. However, these methods are biased towards best-performing classes and can lead to acquired datasets that are not good representatives of the data in the testing set. In this work, we propose a unified framework for active learning, that considers both the uncertainty and the robustness of the detector, ensuring that the network performs accurately in all classes. Furthermore, our method is able to pseudo-label the very confident predictions, suppressing a potential distribution drift while further boosting the performance of the model. Experiments show that our method comprehensively outperforms a wide range of active-learning methods on PASCAL VOC07+12 and MS-COCO, having up to a 7.7% relative improvement, or up to 82% reduction in labeling cost.