 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtiFixer: Enhancing and Extending 3D Reconstruction with Auto-Regressive Diffusion Models
Feb 28, 2026Per-scene optimization methods such as 3D Gaussian Splatting provide state-of-the-art novel view synthesis quality but extrapolate poorly to under-observed areas. Methods that leverage generative priors to correct artifacts in these areas hold promise but currently suffer from two shortcomings. The first is scalability, as existing methods use image diffusion models or bidirectional video models that are limited in the number of views they can generate in a single pass (and thus require a costly iterative distillation process for consistency). The second is quality itself, as generators used in prior work tend to produce outputs that are inconsistent with existing scene content and fail entirely in completely unobserved regions. To solve these, we propose a two-stage pipeline that leverages two key insights. First, we train a powerful bidirectional generative model with a novel opacity mixing strategy that encourages consistency with existing observations while retaining the model's ability to extrapolate novel content in unseen areas. Second, we distill it into a causal auto-regressive model that generates hundreds of frames in a single pass. This model can directly produce novel views or serve as pseudo-supervision to improve the underlying 3D representation in a simple and highly efficient manner. We evaluate our method extensively and demonstrate that it can generate plausible reconstructions in scenarios where existing approaches fail completely. When measured on commonly benchmarked datasets, we outperform existing all existing baselines by a wide margin, exceeding prior state-of-the-art methods by 1-3 dB PSNR.
ChronoEdit: Towards Temporal Reasoning for Image Editing and World Simulation
Oct 05, 2025Recent advances in large generative models have significantly advanced image editing and in-context image generation, yet a critical gap remains in ensuring physical consistency, where edited objects must remain coherent. This capability is especially vital for world simulation related tasks. In this paper, we present ChronoEdit, a framework that reframes image editing as a video generation problem. First, ChronoEdit treats the input and edited images as the first and last frames of a video, allowing it to leverage large pretrained video generative models that capture not only object appearance but also the implicit physics of motion and interaction through learned temporal consistency. Second, ChronoEdit introduces a temporal reasoning stage that explicitly performs editing at inference time. Under this setting, the target frame is jointly denoised with reasoning tokens to imagine a plausible editing trajectory that constrains the solution space to physically viable transformations. The reasoning tokens are then dropped after a few steps to avoid the high computational cost of rendering a full video. To validate ChronoEdit, we introduce PBench-Edit, a new benchmark of image-prompt pairs for contexts that require physical consistency, and demonstrate that ChronoEdit surpasses state-of-the-art baselines in both visual fidelity and physical plausibility. Code and models for both the 14B and 2B variants of ChronoEdit will be released on the project page: https://research.nvidia.com/labs/toronto-ai/chronoedit
Cosmos-Drive-Dreams: Scalable Synthetic Driving Data Generation with World Foundation Models
Jun 11, 2025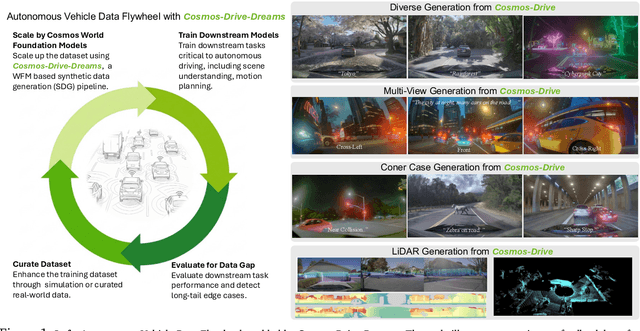
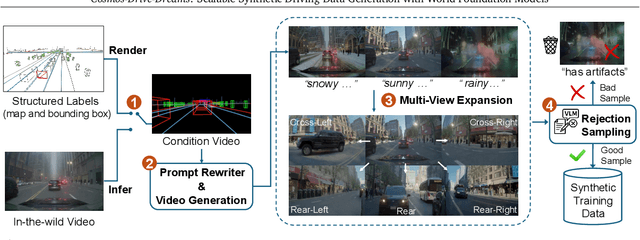
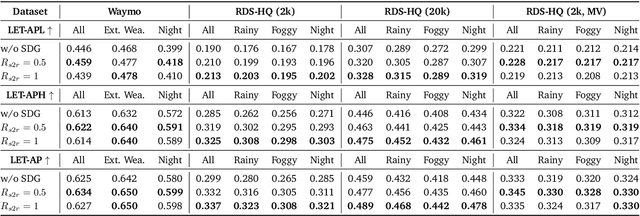
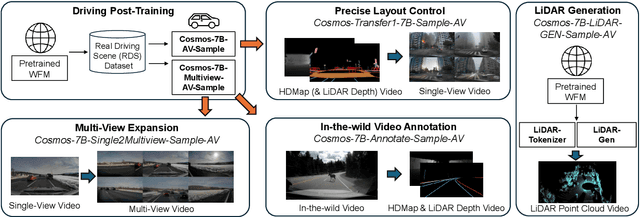
Collecting and annotating real-world data for safety-critical physical AI systems, such as Autonomous Vehicle (AV), is time-consuming and costly. It is especially challenging to capture rare edge cases, which play a critical role in training and testing of an AV system. To address this challenge, we introduce the Cosmos-Drive-Dreams - a synthetic data generation (SDG) pipeline that aims to generate challenging scenarios to facilitate downstream tasks such as perception and driving policy training. Powering this pipeline is Cosmos-Drive, a suite of models specialized from NVIDIA Cosmos world foundation model for the driving domain and are capable of controllable, high-fidelity, multi-view, and spatiotemporally consistent driving video generation. We showcase the utility of these models by applying Cosmos-Drive-Dreams to scale the quantity and diversity of driving datasets with high-fidelity and challenging scenarios. Experimentally, we demonstrate that our generated data helps in mitigating long-tail distribution problems and enhances generalization in downstream tasks such as 3D lane detection, 3D object detection and driving policy learning. We open source our pipeline toolkit, dataset and model weights through the NVIDIA's Cosmos platform. Project page: https://research.nvidia.com/labs/toronto-ai/cosmos_drive_dreams
Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models
Mar 03, 2025Neural Radiance Fields and 3D Gaussian Splatting have revolutionized 3D reconstruction and novel-view synthesis task. However, achieving photorealistic rendering from extreme novel viewpoints remains challenging, as artifacts persist across representations. In this work, we introduce Difix3D+, a novel pipeline designed to enhance 3D reconstruction and novel-view synthesis through single-step diffusion models. At the core of our approach is Difix, a single-step image diffusion model trained to enhance and remove artifacts in rendered novel views caused by underconstrained regions of the 3D representation. Difix serves two critical roles in our pipeline. First, it is used during the reconstruction phase to clean up pseudo-training views that are rendered from the reconstruction and then distilled back into 3D. This greatly enhances underconstrained regions and improves the overall 3D representation quality. More importantly, Difix also acts as a neural enhancer during inference, effectively removing residual artifacts arising from imperfect 3D supervision and the limited capacity of current reconstruction models. Difix3D+ is a general solution, a single model compatible with both NeRF and 3DGS representations, and it achieves an average 2$\times$ improvement in FID score over baselines while maintaining 3D consistency.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
Video-Language Understanding: A Survey from Model Architecture, Model Training, and Data Perspectives
Jun 09, 2024Humans use multiple senses to comprehend the environment. Vision and language are two of the most vital senses since they allow us to easily communicate our thoughts and perceive the world around us. There has been a lot of interest in creating video-language understanding systems with human-like senses since a video-language pair can mimic both our linguistic medium and visual environment with temporal dynamics. In this survey, we review the key tasks of these systems and highlight the associated challenges. Based on the challenges, we summarize their methods from model architecture, model training, and data perspectives. We also conduct performance comparison among the methods, and discuss promising directions for future research.
Towards A Better Metric for Text-to-Video Generation
Jan 15, 2024Generative models have demonstrated remarkable capability in synthesizing high-quality text, images, and videos. For video generation, contemporary text-to-video models exhibit impressive capabilities, crafting visually stunning videos. Nonetheless, evaluating such videos poses significant challenges. Current research predominantly employs automated metrics such as FVD, IS, and CLIP Score. However, these metrics provide an incomplete analysis, particularly in the temporal assessment of video content, thus rendering them unreliable indicators of true video quality. Furthermore, while user studies have the potential to reflect human perception accurately, they are hampered by their time-intensive and laborious nature, with outcomes that are often tainted by subjective bias. In this paper, we investigate the limitations inherent in existing metrics and introduce a novel evaluation pipeline, the Text-to-Video Score (T2VScore). This metric integrates two pivotal criteria: (1) Text-Video Alignment, which scrutinizes the fidelity of the video in representing the given text description, and (2) Video Quality, which evaluates the video's overall production caliber with a mixture of experts. Moreover, to evaluate the proposed metrics and facilitate future improvements on them, we present the TVGE dataset, collecting human judgements of 2,543 text-to-video generated videos on the two criteria. Experiments on the TVGE dataset demonstrate the superiority of the proposed T2VScore on offering a better metric for text-to-video generation.
VideoSwap: Customized Video Subject Swapping with Interactive Semantic Point Correspondence
Dec 05, 2023



Current diffusion-based video editing primarily focuses on structure-preserved editing by utilizing various dense correspondences to ensure temporal consistency and motion alignment. However, these approaches are often ineffective when the target edit involves a shape change. To embark on video editing with shape change, we explore customized video subject swapping in this work, where we aim to replace the main subject in a source video with a target subject having a distinct identity and potentially different shape. In contrast to previous methods that rely on dense correspondences, we introduce the VideoSwap framework that exploits semantic point correspondences, inspired by our observation that only a small number of semantic points are necessary to align the subject's motion trajectory and modify its shape. We also introduce various user-point interactions (\eg, removing points and dragging points) to address various semantic point correspondence. Extensive experiments demonstrate state-of-the-art video subject swapping results across a variety of real-world videos.
CVPR 2023 Text Guided Video Editing Competition
Oct 24, 2023



Humans watch more than a billion hours of video per day. Most of this video was edited manually, which is a tedious process. However, AI-enabled video-generation and video-editing is on the rise. Building on text-to-image models like Stable Diffusion and Imagen, generative AI has improved dramatically on video tasks. But it's hard to evaluate progress in these video tasks because there is no standard benchmark. So, we propose a new dataset for text-guided video editing (TGVE), and we run a competition at CVPR to evaluate models on our TGVE dataset. In this paper we present a retrospective on the competition and describe the winning method. The competition dataset is available at https://sites.google.com/view/loveucvpr23/track4.
DynVideo-E: Harnessing Dynamic NeRF for Large-Scale Motion- and View-Change Human-Centric Video Editing
Oct 16, 2023
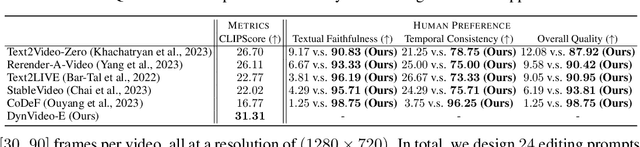
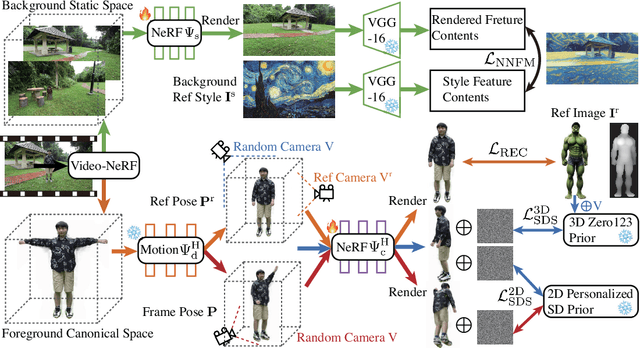

Despite remarkable research advances in diffusion-based video editing, existing methods are limited to short-length videos due to the contradiction between long-range consistency and frame-wise editing. Recent approaches attempt to tackle this challenge by introducing video-2D representations to degrade video editing to image editing. However, they encounter significant difficulties in handling large-scale motion- and view-change videos especially for human-centric videos. This motivates us to introduce the dynamic Neural Radiance Fields (NeRF) as the human-centric video representation to ease the video editing problem to a 3D space editing task. As such, editing can be performed in the 3D spaces and propagated to the entire video via the deformation field. To provide finer and direct controllable editing, we propose the image-based 3D space editing pipeline with a set of effective designs. These include multi-view multi-pose Score Distillation Sampling (SDS) from both 2D personalized diffusion priors and 3D diffusion priors, reconstruction losses on the reference image, text-guided local parts super-resolution, and style transfer for 3D background space. Extensive experiments demonstrate that our method, dubbed as DynVideo-E, significantly outperforms SOTA approaches on two challenging datasets by a large margin of 50% ~ 95% in terms of human preference. Compelling video comparisons are provided in the project page https://showlab.github.io/DynVideo-E/. Our code and data will be released to the community.