 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTPDiff: Temporal Pyramid Video Diffusion Model
Mar 12, 2025The development of video diffusion models unveils a significant challenge: the substantial computational demands. To mitigate this challenge, we note that the reverse process of diffusion exhibits an inherent entropy-reducing nature. Given the inter-frame redundancy in video modality, maintaining full frame rates in high-entropy stages is unnecessary. Based on this insight, we propose TPDiff, a unified framework to enhance training and inference efficiency. By dividing diffusion into several stages, our framework progressively increases frame rate along the diffusion process with only the last stage operating on full frame rate, thereby optimizing computational efficiency. To train the multi-stage diffusion model, we introduce a dedicated training framework: stage-wise diffusion. By solving the partitioned probability flow ordinary differential equations (ODE) of diffusion under aligned data and noise, our training strategy is applicable to various diffusion forms and further enhances training efficiency. Comprehensive experimental evaluations validate the generality of our method, demonstrating 50% reduction in training cost and 1.5x improvement in inference efficiency.
EvolveDirector: Approaching Advanced Text-to-Image Generation with Large Vision-Language Models
Oct 10, 2024
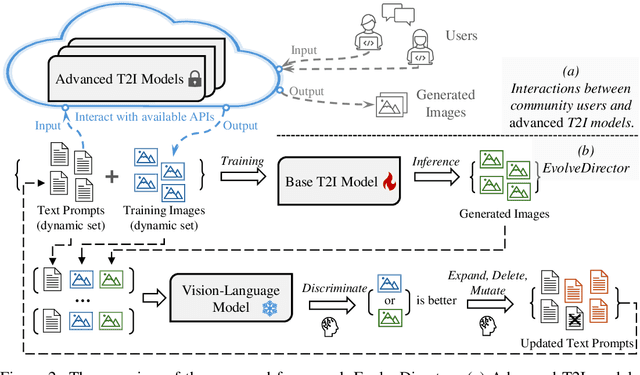

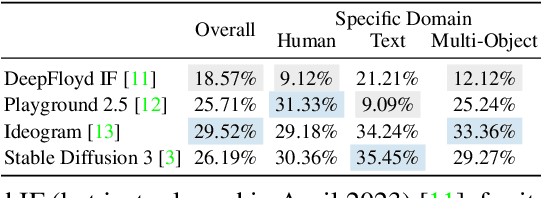
Recent advancements in generation models have showcased remarkable capabilities in generating fantastic content. However, most of them are trained on proprietary high-quality data, and some models withhold their parameters and only provide accessible application programming interfaces (APIs), limiting their benefits for downstream tasks. To explore the feasibility of training a text-to-image generation model comparable to advanced models using publicly available resources, we introduce EvolveDirector. This framework interacts with advanced models through their public APIs to obtain text-image data pairs to train a base model. Our experiments with extensive data indicate that the model trained on generated data of the advanced model can approximate its generation capability. However, it requires large-scale samples of 10 million or more. This incurs significant expenses in time, computational resources, and especially the costs associated with calling fee-based APIs. To address this problem, we leverage pre-trained large vision-language models (VLMs) to guide the evolution of the base model. VLM continuously evaluates the base model during training and dynamically updates and refines the training dataset by the discrimination, expansion, deletion, and mutation operations. Experimental results show that this paradigm significantly reduces the required data volume. Furthermore, when approaching multiple advanced models, EvolveDirector can select the best samples generated by them to learn powerful and balanced abilities. The final trained model Edgen is demonstrated to outperform these advanced models. The code and model weights are available at https://github.com/showlab/EvolveDirector.
X-Adapter: Adding Universal Compatibility of Plugins for Upgraded Diffusion Model
Dec 06, 2023



We introduce X-Adapter, a universal upgrader to enable the pretrained plug-and-play modules (e.g., ControlNet, LoRA) to work directly with the upgraded text-to-image diffusion model (e.g., SDXL) without further retraining. We achieve this goal by training an additional network to control the frozen upgraded model with the new text-image data pairs. In detail, X-Adapter keeps a frozen copy of the old model to preserve the connectors of different plugins. Additionally, X-Adapter adds trainable mapping layers that bridge the decoders from models of different versions for feature remapping. The remapped features will be used as guidance for the upgraded model. To enhance the guidance ability of X-Adapter, we employ a null-text training strategy for the upgraded model. After training, we also introduce a two-stage denoising strategy to align the initial latents of X-Adapter and the upgraded model. Thanks to our strategies, X-Adapter demonstrates universal compatibility with various plugins and also enables plugins of different versions to work together, thereby expanding the functionalities of diffusion community. To verify the effectiveness of the proposed method, we conduct extensive experiments and the results show that X-Adapter may facilitate wider application in the upgraded foundational diffusion model.
Show-1: Marrying Pixel and Latent Diffusion Models for Text-to-Video Generation
Sep 27, 2023Significant advancements have been achieved in the realm of large-scale pre-trained text-to-video Diffusion Models (VDMs). However, previous methods either rely solely on pixel-based VDMs, which come with high computational costs, or on latent-based VDMs, which often struggle with precise text-video alignment. In this paper, we are the first to propose a hybrid model, dubbed as Show-1, which marries pixel-based and latent-based VDMs for text-to-video generation. Our model first uses pixel-based VDMs to produce a low-resolution video of strong text-video correlation. After that, we propose a novel expert translation method that employs the latent-based VDMs to further upsample the low-resolution video to high resolution. Compared to latent VDMs, Show-1 can produce high-quality videos of precise text-video alignment; Compared to pixel VDMs, Show-1 is much more efficient (GPU memory usage during inference is 15G vs 72G). We also validate our model on standard video generation benchmarks. Our code and model weights are publicly available at \url{https://github.com/showlab/Show-1}.