 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShowUI-Aloha: Human-Taught GUI Agent
Jan 12, 2026Graphical User Interfaces (GUIs) are central to human-computer interaction, yet automating complex GUI tasks remains a major challenge for autonomous agents, largely due to a lack of scalable, high-quality training data. While recordings of human demonstrations offer a rich data source, they are typically long, unstructured, and lack annotations, making them difficult for agents to learn from.To address this, we introduce ShowUI-Aloha, a comprehensive pipeline that transforms unstructured, in-the-wild human screen recordings from desktop environments into structured, actionable tasks. Our framework includes four key components: A recorder that captures screen video along with precise user interactions like mouse clicks, keystrokes, and scrolls. A learner that semantically interprets these raw interactions and the surrounding visual context, translating them into descriptive natural language captions. A planner that reads the parsed demonstrations, maintains task states, and dynamically formulates the next high-level action plan based on contextual reasoning. An executor that faithfully carries out these action plans at the OS level, performing precise clicks, drags, text inputs, and window operations with safety checks and real-time feedback. Together, these components provide a scalable solution for collecting and parsing real-world human data, demonstrating a viable path toward building general-purpose GUI agents that can learn effectively from simply observing humans.
Factorized Learning for Temporally Grounded Video-Language Models
Dec 30, 2025Recent video-language models have shown great potential for video understanding, but still struggle with accurate temporal grounding for event-level perception. We observe that two main factors in video understanding (i.e., temporal grounding and textual response) form a logical hierarchy: accurate temporal evidence grounding lays the foundation for reliable textual response. However, existing works typically handle these two tasks in a coupled manner without a clear logical structure, leading to sub-optimal objectives. We address this from a factorized learning perspective. We first propose D$^2$VLM, a framework that decouples the learning of these two tasks while also emphasizing their inherent dependency. We adopt a "grounding then answering with evidence referencing" paradigm and introduce evidence tokens for evidence grounding, which emphasize event-level visual semantic capture beyond the focus on timestamp representation in existing works. To further facilitate the learning of these two tasks, we introduce a novel factorized preference optimization (FPO) algorithm. Unlike standard preference optimization, FPO explicitly incorporates probabilistic temporal grounding modeling into the optimization objective, enabling preference learning for both temporal grounding and textual response. We also construct a synthetic dataset to address the lack of suitable datasets for factorized preference learning with explicit temporal grounding. Experiments on various tasks demonstrate the clear advantage of our approach. Our source code is available at https://github.com/nusnlp/d2vlm.
AUTO-Explorer: Automated Data Collection for GUI Agent
Nov 09, 2025Recent advancements in GUI agents have significantly expanded their ability to interpret natural language commands to manage software interfaces. However, acquiring GUI data remains a significant challenge. Existing methods often involve designing automated agents that browse URLs from the Common Crawl, using webpage HTML to collect screenshots and corresponding annotations, including the names and bounding boxes of UI elements. However, this method is difficult to apply to desktop software or some newly launched websites not included in the Common Crawl. While we expect the model to possess strong generalization capabilities to handle this, it is still crucial for personalized scenarios that require rapid and perfect adaptation to new software or websites. To address this, we propose an automated data collection method with minimal annotation costs, named Auto-Explorer. It incorporates a simple yet effective exploration mechanism that autonomously parses and explores GUI environments, gathering data efficiently. Additionally, to assess the quality of exploration, we have developed the UIXplore benchmark. This benchmark creates environments for explorer agents to discover and save software states. Using the data gathered, we fine-tune a multimodal large language model (MLLM) and establish a GUI element grounding testing set to evaluate the effectiveness of the exploration strategies. Our experiments demonstrate the superior performance of Auto-Explorer, showing that our method can quickly enhance the capabilities of an MLLM in explored software.
EmoAgent: Multi-Agent Collaboration of Plan, Edit, and Critic, for Affective Image Manipulation
Mar 14, 2025



Affective Image Manipulation (AIM) aims to alter an image's emotional impact by adjusting multiple visual elements to evoke specific feelings.Effective AIM is inherently complex, necessitating a collaborative approach that involves identifying semantic cues within source images, manipulating these elements to elicit desired emotional responses, and verifying that the combined adjustments successfully evoke the target emotion.To address these challenges, we introduce EmoAgent, the first multi-agent collaboration framework for AIM. By emulating the cognitive behaviors of a human painter, EmoAgent incorporates three specialized agents responsible for planning, editing, and critical evaluation. Furthermore, we develop an emotion-factor knowledge retriever, a decision-making tree space, and a tool library to enhance EmoAgent's effectiveness in handling AIM. Experiments demonstrate that the proposed multi-agent framework outperforms existing methods, offering more reasonable and effective emotional expression.
WorldGUI: Dynamic Testing for Comprehensive Desktop GUI Automation
Feb 12, 2025Current GUI agents have achieved outstanding performance in GUI element grounding. However, planning remains highly challenging, especially due to sensitivity to the initial state of the environment. Specifically, slight differences in the initial state-such as the target software not being open or the interface not being in its default state-often lead to planning errors. This issue is widespread in real user scenarios, but existing benchmarks fail to evaluate it. In this paper, we present WorldGUI, a novel GUI benchmark that designs GUI tasks with various initial states to simulate real computer-user interactions. The benchmark spans a wide range of tasks across 10 popular software applications, including PowerPoint, VSCode, and Adobe Acrobat. In addition, to address the challenges of dynamic GUI automation tasks, we propose GUI-Thinker, a holistic framework, leveraging a critique mechanism, that effectively manages the unpredictability and complexity of GUI interactions. Experimental results demonstrate that GUI-Thinker significantly outperforms Claude-3.5 (Computer Use) by 14.9% in success rate on WorldGUI tasks. This improvement underscores the effectiveness of our critical-thinking-based framework in enhancing GUI automation.
ShowUI: One Vision-Language-Action Model for GUI Visual Agent
Nov 26, 2024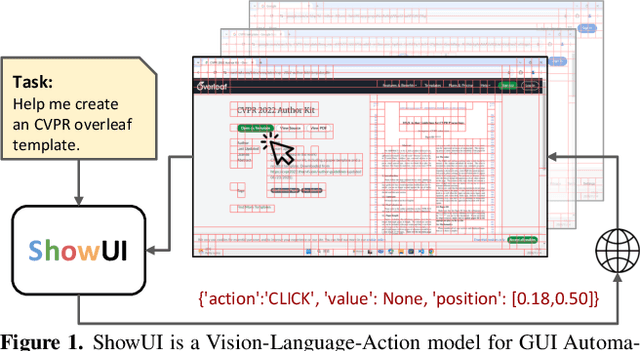
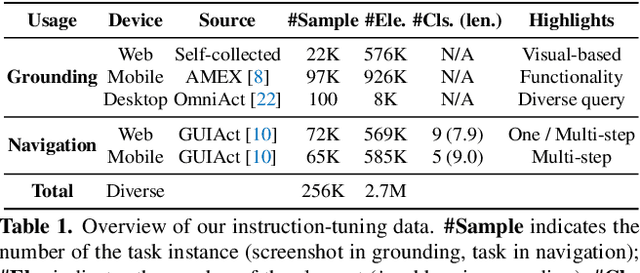
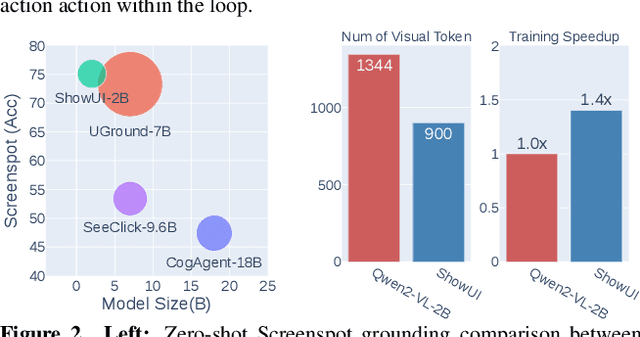
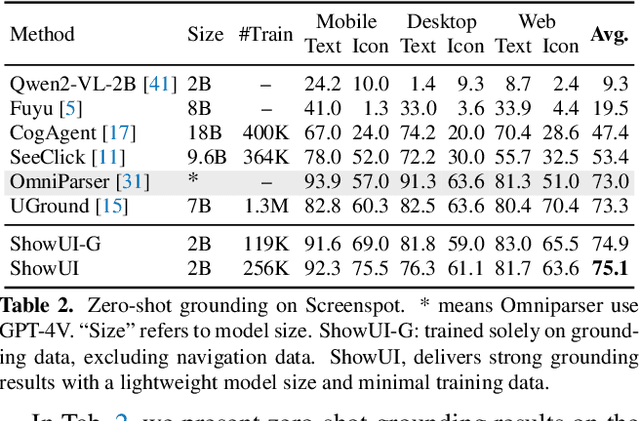
Building Graphical User Interface (GUI) assistants holds significant promise for enhancing human workflow productivity. While most agents are language-based, relying on closed-source API with text-rich meta-information (e.g., HTML or accessibility tree), they show limitations in perceiving UI visuals as humans do, highlighting the need for GUI visual agents. In this work, we develop a vision-language-action model in digital world, namely ShowUI, which features the following innovations: (i) UI-Guided Visual Token Selection to reduce computational costs by formulating screenshots as an UI connected graph, adaptively identifying their redundant relationship and serve as the criteria for token selection during self-attention blocks; (ii) Interleaved Vision-Language-Action Streaming that flexibly unifies diverse needs within GUI tasks, enabling effective management of visual-action history in navigation or pairing multi-turn query-action sequences per screenshot to enhance training efficiency; (iii) Small-scale High-quality GUI Instruction-following Datasets by careful data curation and employing a resampling strategy to address significant data type imbalances. With above components, ShowUI, a lightweight 2B model using 256K data, achieves a strong 75.1% accuracy in zero-shot screenshot grounding. Its UI-guided token selection further reduces 33% of redundant visual tokens during training and speeds up the performance by 1.4x. Navigation experiments across web Mind2Web, mobile AITW, and online MiniWob environments further underscore the effectiveness and potential of our model in advancing GUI visual agents. The models are available at https://github.com/showlab/ShowUI.
The Dawn of GUI Agent: A Preliminary Case Study with Claude 3.5 Computer Use
Nov 15, 2024



The recently released model, Claude 3.5 Computer Use, stands out as the first frontier AI model to offer computer use in public beta as a graphical user interface (GUI) agent. As an early beta, its capability in the real-world complex environment remains unknown. In this case study to explore Claude 3.5 Computer Use, we curate and organize a collection of carefully designed tasks spanning a variety of domains and software. Observations from these cases demonstrate Claude 3.5 Computer Use's unprecedented ability in end-to-end language to desktop actions. Along with this study, we provide an out-of-the-box agent framework for deploying API-based GUI automation models with easy implementation. Our case studies aim to showcase a groundwork of capabilities and limitations of Claude 3.5 Computer Use with detailed analyses and bring to the fore questions about planning, action, and critic, which must be considered for future improvement. We hope this preliminary exploration will inspire future research into the GUI agent community. All the test cases in the paper can be tried through the project: https://github.com/showlab/computer_use_ootb.
Learning Video Context as Interleaved Multimodal Sequences
Jul 31, 2024



Narrative videos, such as movies, pose significant challenges in video understanding due to their rich contexts (characters, dialogues, storylines) and diverse demands (identify who, relationship, and reason). In this paper, we introduce MovieSeq, a multimodal language model developed to address the wide range of challenges in understanding video contexts. Our core idea is to represent videos as interleaved multimodal sequences (including images, plots, videos, and subtitles), either by linking external knowledge databases or using offline models (such as whisper for subtitles). Through instruction-tuning, this approach empowers the language model to interact with videos using interleaved multimodal instructions. For example, instead of solely relying on video as input, we jointly provide character photos alongside their names and dialogues, allowing the model to associate these elements and generate more comprehensive responses. To demonstrate its effectiveness, we validate MovieSeq's performance on six datasets (LVU, MAD, Movienet, CMD, TVC, MovieQA) across five settings (video classification, audio description, video-text retrieval, video captioning, and video question-answering). The code will be public at https://github.com/showlab/MovieSeq.
GUI Action Narrator: Where and When Did That Action Take Place?
Jun 19, 2024



The advent of Multimodal LLMs has significantly enhanced image OCR recognition capabilities, making GUI automation a viable reality for increasing efficiency in digital tasks. One fundamental aspect of developing a GUI automation system is understanding primitive GUI actions. This comprehension is crucial as it enables agents to learn from user demonstrations, an essential element of automation. To rigorously evaluate such capabilities, we developed a video captioning benchmark for GUI actions, comprising 4,189 diverse video captioning samples. This task presents unique challenges compared to natural scene video captioning: 1) GUI screenshots typically contain denser information than natural scenes, and 2) events within GUIs are subtler and occur more rapidly, requiring precise attention to the appropriate time span and spatial region for accurate understanding. To address these challenges, we introduce our GUI action dataset \textbf{Act2Cap} as well as a simple yet effective framework, \textbf{GUI Narrator}, for GUI video captioning that utilizes the cursor as a visual prompt to enhance the interpretation of high-resolution screenshots. Specifically, a cursor detector is trained on our dataset, and a multimodal LLM model with mechanisms for selecting keyframes and key regions generates the captions. Experimental results indicate that even for today's most advanced multimodal models, such as GPT-4o, the task remains highly challenging. Additionally, our evaluations show that our strategy effectively enhances model performance, whether integrated into the fine-tuning of open-source models or employed as a prompting strategy in closed-source models.
VideoLLM-online: Online Video Large Language Model for Streaming Video
Jun 17, 2024
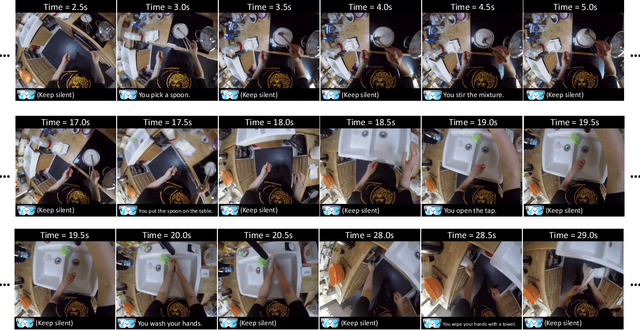
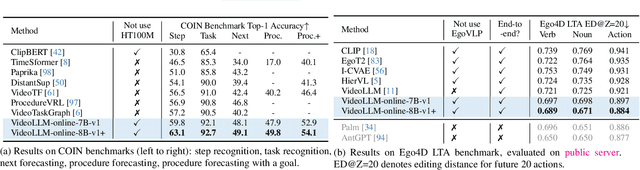
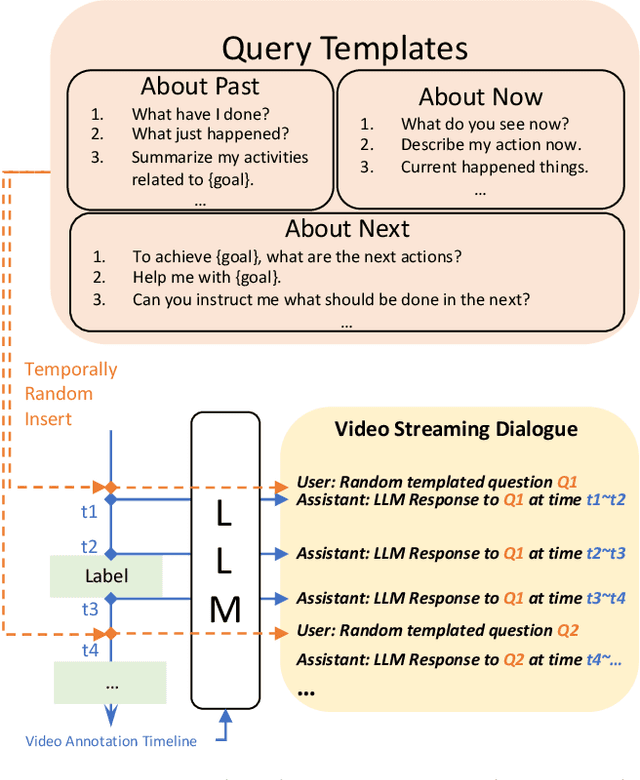
Recent Large Language Models have been enhanced with vision capabilities, enabling them to comprehend images, videos, and interleaved vision-language content. However, the learning methods of these large multimodal models typically treat videos as predetermined clips, making them less effective and efficient at handling streaming video inputs. In this paper, we propose a novel Learning-In-Video-Stream (LIVE) framework, which enables temporally aligned, long-context, and real-time conversation within a continuous video stream. Our LIVE framework comprises comprehensive approaches to achieve video streaming dialogue, encompassing: (1) a training objective designed to perform language modeling for continuous streaming inputs, (2) a data generation scheme that converts offline temporal annotations into a streaming dialogue format, and (3) an optimized inference pipeline to speed up the model responses in real-world video streams. With our LIVE framework, we built VideoLLM-online model upon Llama-2/Llama-3 and demonstrate its significant advantages in processing streaming videos. For instance, on average, our model can support streaming dialogue in a 5-minute video clip at over 10 FPS on an A100 GPU. Moreover, it also showcases state-of-the-art performance on public offline video benchmarks, such as recognition, captioning, and forecasting. The code, model, data, and demo have been made available at https://showlab.github.io/videollm-online.