 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKiwi-Edit: Versatile Video Editing via Instruction and Reference Guidance
Mar 05, 2026Instruction-based video editing has witnessed rapid progress, yet current methods often struggle with precise visual control, as natural language is inherently limited in describing complex visual nuances. Although reference-guided editing offers a robust solution, its potential is currently bottlenecked by the scarcity of high-quality paired training data. To bridge this gap, we introduce a scalable data generation pipeline that transforms existing video editing pairs into high-fidelity training quadruplets, leveraging image generative models to create synthesized reference scaffolds. Using this pipeline, we construct RefVIE, a large-scale dataset tailored for instruction-reference-following tasks, and establish RefVIE-Bench for comprehensive evaluation. Furthermore, we propose a unified editing architecture, Kiwi-Edit, that synergizes learnable queries and latent visual features for reference semantic guidance. Our model achieves significant gains in instruction following and reference fidelity via a progressive multi-stage training curriculum. Extensive experiments demonstrate that our data and architecture establish a new state-of-the-art in controllable video editing. All datasets, models, and code is released at https://github.com/showlab/Kiwi-Edit.
SIGMA: Selective-Interleaved Generation with Multi-Attribute Tokens
Feb 07, 2026Recent unified models such as Bagel demonstrate that paired image-edit data can effectively align multiple visual tasks within a single diffusion transformer. However, these models remain limited to single-condition inputs and lack the flexibility needed to synthesize results from multiple heterogeneous sources. We present SIGMA (Selective-Interleaved Generation with Multi-Attribute Tokens), a unified post-training framework that enables interleaved multi-condition generation within diffusion transformers. SIGMA introduces selective multi-attribute tokens, including style, content, subject, and identity tokens, which allow the model to interpret and compose multiple visual conditions in an interleaved text-image sequence. Through post-training on the Bagel unified backbone with 700K interleaved examples, SIGMA supports compositional editing, selective attribute transfer, and fine-grained multimodal alignment. Extensive experiments show that SIGMA improves controllability, cross-condition consistency, and visual quality across diverse editing and generation tasks, with substantial gains over Bagel on compositional tasks.
World-VLA-Loop: Closed-Loop Learning of Video World Model and VLA Policy
Feb 06, 2026Recent progress in robotic world models has leveraged video diffusion transformers to predict future observations conditioned on historical states and actions. While these models can simulate realistic visual outcomes, they often exhibit poor action-following precision, hindering their utility for downstream robotic learning. In this work, we introduce World-VLA-Loop, a closed-loop framework for the joint refinement of world models and Vision-Language-Action (VLA) policies. We propose a state-aware video world model that functions as a high-fidelity interactive simulator by jointly predicting future observations and reward signals. To enhance reliability, we introduce the SANS dataset, which incorporates near-success trajectories to improve action-outcome alignment within the world model. This framework enables a closed-loop for reinforcement learning (RL) post-training of VLA policies entirely within a virtual environment. Crucially, our approach facilitates a co-evolving cycle: failure rollouts generated by the VLA policy are iteratively fed back to refine the world model precision, which in turn enhances subsequent RL optimization. Evaluations across simulation and real-world tasks demonstrate that our framework significantly boosts VLA performance with minimal physical interaction, establishing a mutually beneficial relationship between world modeling and policy learning for general-purpose robotics. Project page: https://showlab.github.io/World-VLA-Loop/.
EVOLVE-VLA: Test-Time Training from Environment Feedback for Vision-Language-Action Models
Dec 16, 2025Achieving truly adaptive embodied intelligence requires agents that learn not just by imitating static demonstrations, but by continuously improving through environmental interaction, which is akin to how humans master skills through practice. Vision-Language-Action (VLA) models have advanced robotic manipulation by leveraging large language models, yet remain fundamentally limited by Supervised Finetuning (SFT): requiring hundreds of demonstrations per task, rigidly memorizing trajectories, and failing to adapt when deployment conditions deviate from training. We introduce EVOLVE-VLA, a test-time training framework enabling VLAs to continuously adapt through environment interaction with minimal or zero task-specific demonstrations. The key technical challenge is replacing oracle reward signals (unavailable at test time) with autonomous feedback. We address this through a learned progress estimator providing dense feedback, and critically, we design our framework to ``tame'' this inherently noisy signal via two mechanisms: (1) an accumulative progress estimation mechanism smoothing noisy point-wise estimates, and (2) a progressive horizon extension strategy enabling gradual policy evolution. EVOLVE-VLA achieves substantial gains: +8.6\% on long-horizon tasks, +22.0\% in 1-shot learning, and enables cross-task generalization -- achieving 20.8\% success on unseen tasks without task-specific demonstrations training (vs. 0\% for pure SFT). Qualitative analysis reveals emergent capabilities absent in demonstrations, including error recovery and novel strategies. This work represents a critical step toward VLAs that truly learn and adapt, moving beyond static imitation toward continuous self-improvements.
Impossible Videos
Mar 18, 2025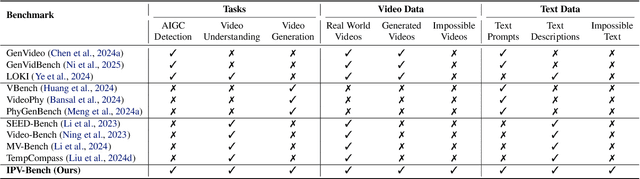
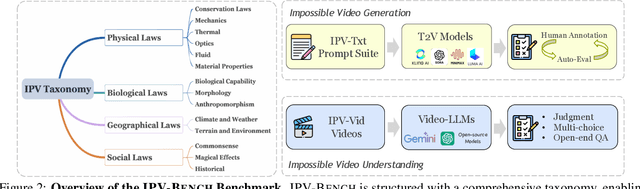
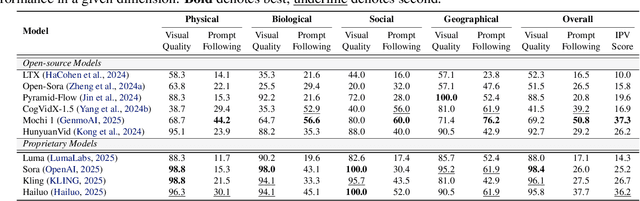

Synthetic videos nowadays is widely used to complement data scarcity and diversity of real-world videos. Current synthetic datasets primarily replicate real-world scenarios, leaving impossible, counterfactual and anti-reality video concepts underexplored. This work aims to answer two questions: 1) Can today's video generation models effectively follow prompts to create impossible video content? 2) Are today's video understanding models good enough for understanding impossible videos? To this end, we introduce IPV-Bench, a novel benchmark designed to evaluate and foster progress in video understanding and generation. IPV-Bench is underpinned by a comprehensive taxonomy, encompassing 4 domains, 14 categories. It features diverse scenes that defy physical, biological, geographical, or social laws. Based on the taxonomy, a prompt suite is constructed to evaluate video generation models, challenging their prompt following and creativity capabilities. In addition, a video benchmark is curated to assess Video-LLMs on their ability of understanding impossible videos, which particularly requires reasoning on temporal dynamics and world knowledge. Comprehensive evaluations reveal limitations and insights for future directions of video models, paving the way for next-generation video models.
ShowUI: One Vision-Language-Action Model for GUI Visual Agent
Nov 26, 2024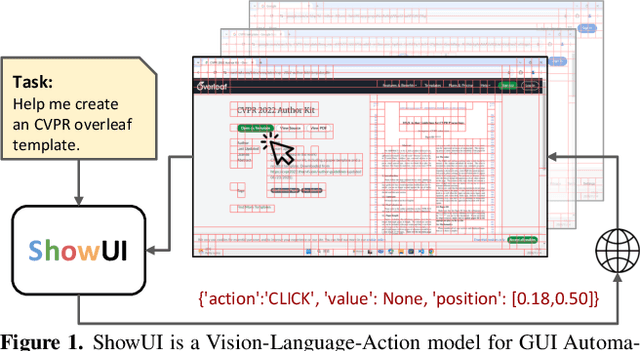
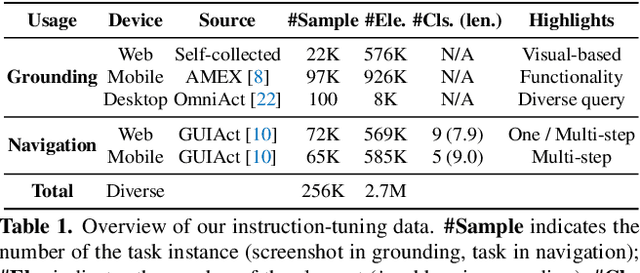
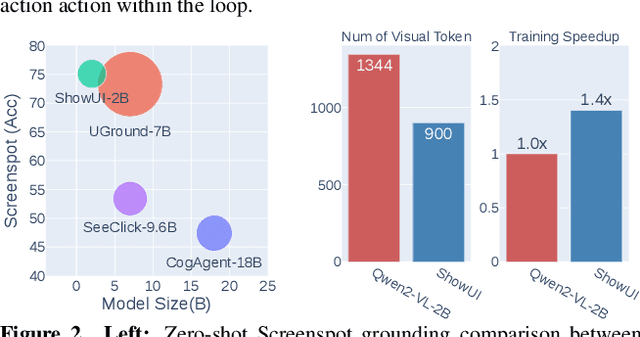
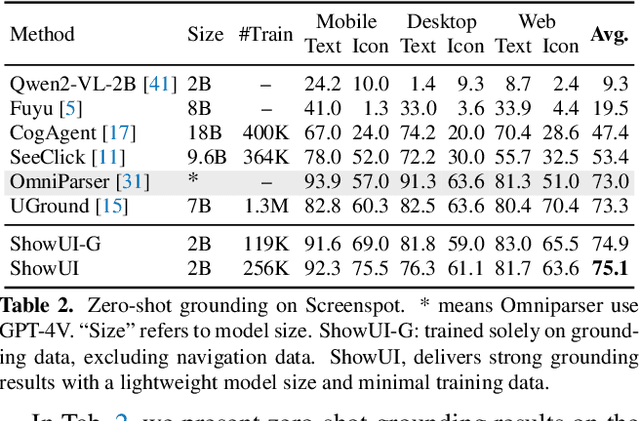
Building Graphical User Interface (GUI) assistants holds significant promise for enhancing human workflow productivity. While most agents are language-based, relying on closed-source API with text-rich meta-information (e.g., HTML or accessibility tree), they show limitations in perceiving UI visuals as humans do, highlighting the need for GUI visual agents. In this work, we develop a vision-language-action model in digital world, namely ShowUI, which features the following innovations: (i) UI-Guided Visual Token Selection to reduce computational costs by formulating screenshots as an UI connected graph, adaptively identifying their redundant relationship and serve as the criteria for token selection during self-attention blocks; (ii) Interleaved Vision-Language-Action Streaming that flexibly unifies diverse needs within GUI tasks, enabling effective management of visual-action history in navigation or pairing multi-turn query-action sequences per screenshot to enhance training efficiency; (iii) Small-scale High-quality GUI Instruction-following Datasets by careful data curation and employing a resampling strategy to address significant data type imbalances. With above components, ShowUI, a lightweight 2B model using 256K data, achieves a strong 75.1% accuracy in zero-shot screenshot grounding. Its UI-guided token selection further reduces 33% of redundant visual tokens during training and speeds up the performance by 1.4x. Navigation experiments across web Mind2Web, mobile AITW, and online MiniWob environments further underscore the effectiveness and potential of our model in advancing GUI visual agents. The models are available at https://github.com/showlab/ShowUI.
Factorized Visual Tokenization and Generation
Nov 25, 2024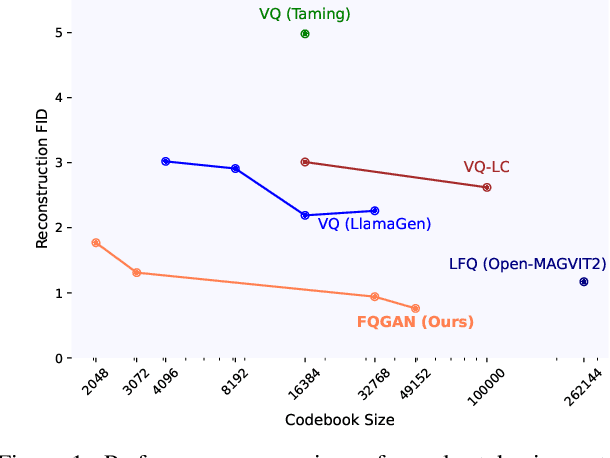
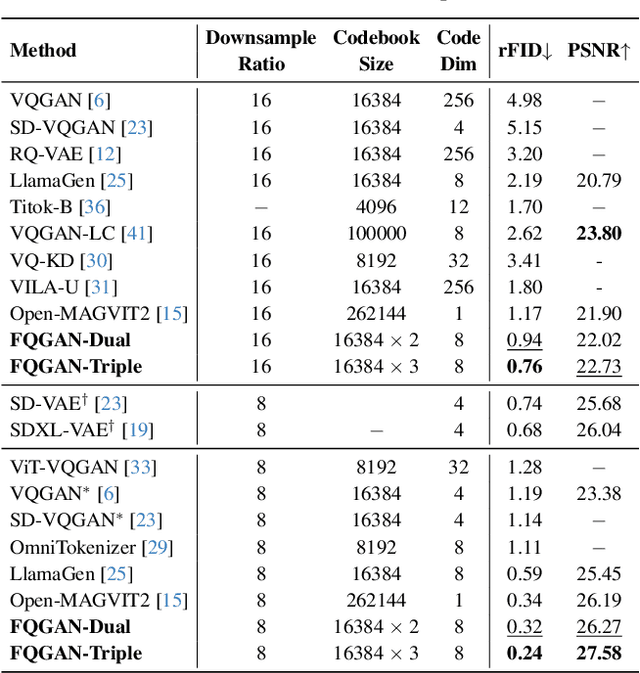
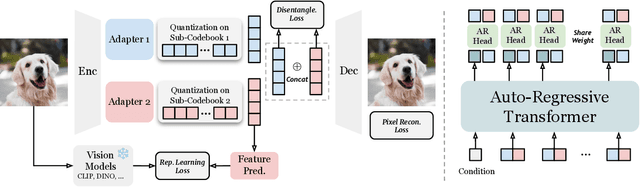
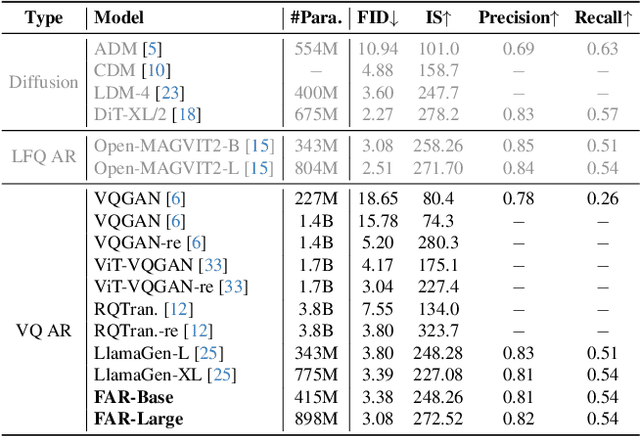
Visual tokenizers are fundamental to image generation. They convert visual data into discrete tokens, enabling transformer-based models to excel at image generation. Despite their success, VQ-based tokenizers like VQGAN face significant limitations due to constrained vocabulary sizes. Simply expanding the codebook often leads to training instability and diminishing performance gains, making scalability a critical challenge. In this work, we introduce Factorized Quantization (FQ), a novel approach that revitalizes VQ-based tokenizers by decomposing a large codebook into multiple independent sub-codebooks. This factorization reduces the lookup complexity of large codebooks, enabling more efficient and scalable visual tokenization. To ensure each sub-codebook captures distinct and complementary information, we propose a disentanglement regularization that explicitly reduces redundancy, promoting diversity across the sub-codebooks. Furthermore, we integrate representation learning into the training process, leveraging pretrained vision models like CLIP and DINO to infuse semantic richness into the learned representations. This design ensures our tokenizer captures diverse semantic levels, leading to more expressive and disentangled representations. Experiments show that the proposed FQGAN model substantially improves the reconstruction quality of visual tokenizers, achieving state-of-the-art performance. We further demonstrate that this tokenizer can be effectively adapted into auto-regressive image generation. https://showlab.github.io/FQGAN
One Token to Seg Them All: Language Instructed Reasoning Segmentation in Videos
Sep 29, 2024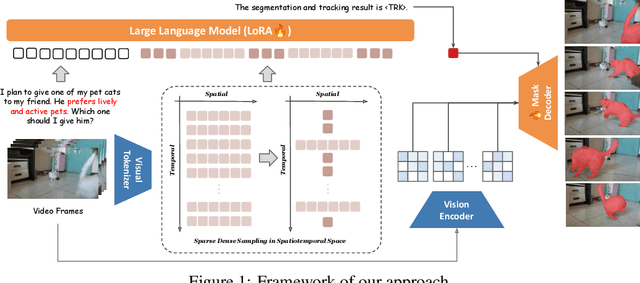
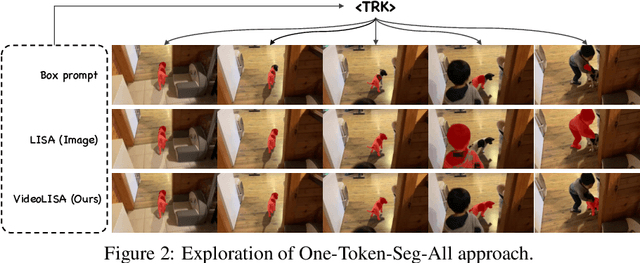


We introduce VideoLISA, a video-based multimodal large language model designed to tackle the problem of language-instructed reasoning segmentation in videos. Leveraging the reasoning capabilities and world knowledge of large language models, and augmented by the Segment Anything Model, VideoLISA generates temporally consistent segmentation masks in videos based on language instructions. Existing image-based methods, such as LISA, struggle with video tasks due to the additional temporal dimension, which requires temporal dynamic understanding and consistent segmentation across frames. VideoLISA addresses these challenges by integrating a Sparse Dense Sampling strategy into the video-LLM, which balances temporal context and spatial detail within computational constraints. Additionally, we propose a One-Token-Seg-All approach using a specially designed <TRK> token, enabling the model to segment and track objects across multiple frames. Extensive evaluations on diverse benchmarks, including our newly introduced ReasonVOS benchmark, demonstrate VideoLISA's superior performance in video object segmentation tasks involving complex reasoning, temporal understanding, and object tracking. While optimized for videos, VideoLISA also shows promising generalization to image segmentation, revealing its potential as a unified foundation model for language-instructed object segmentation. Code and model will be available at: https://github.com/showlab/VideoLISA.
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Aug 22, 2024



We present a unified transformer, i.e., Show-o, that unifies multimodal understanding and generation. Unlike fully autoregressive models, Show-o unifies autoregressive and (discrete) diffusion modeling to adaptively handle inputs and outputs of various and mixed modalities. The unified model flexibly supports a wide range of vision-language tasks including visual question-answering, text-to-image generation, text-guided inpainting/extrapolation, and mixed-modality generation. Across various benchmarks, it demonstrates comparable or superior performance to existing individual models with an equivalent or larger number of parameters tailored for understanding or generation. This significantly highlights its potential as a next-generation foundation model. Code and models are released at https://github.com/showlab/Show-o.
GQE: Generalized Query Expansion for Enhanced Text-Video Retrieval
Aug 14, 2024In the rapidly expanding domain of web video content, the task of text-video retrieval has become increasingly critical, bridging the semantic gap between textual queries and video data. This paper introduces a novel data-centric approach, Generalized Query Expansion (GQE), to address the inherent information imbalance between text and video, enhancing the effectiveness of text-video retrieval systems. Unlike traditional model-centric methods that focus on designing intricate cross-modal interaction mechanisms, GQE aims to expand the text queries associated with videos both during training and testing phases. By adaptively segmenting videos into short clips and employing zero-shot captioning, GQE enriches the training dataset with comprehensive scene descriptions, effectively bridging the data imbalance gap. Furthermore, during retrieval, GQE utilizes Large Language Models (LLM) to generate a diverse set of queries and a query selection module to filter these queries based on relevance and diversity, thus optimizing retrieval performance while reducing computational overhead. Our contributions include a detailed examination of the information imbalance challenge, a novel approach to query expansion in video-text datasets, and the introduction of a query selection strategy that enhances retrieval accuracy without increasing computational costs. GQE achieves state-of-the-art performance on several benchmarks, including MSR-VTT, MSVD, LSMDC, and VATEX, demonstrating the effectiveness of addressing text-video retrieval from a data-centric perspective.